Dans cet article, nous allons nous pencher sur les aspects réseaux d’Azure Kubernetes Services. En effet, il n’est pas aisé...
23 mai 2017
Azure Search : installation et configuration !

Azure Search est un outil qui facilite l’ajout de fonctionnalités de recherches puissantes et sophistiquées, comme la recherche « full texte », la suggestion, possibilité de mettre en place un profil de scoring qui aura une incidence sur les résultats.
Azure Search peut être utilisé depuis de nombreuse plateformes comme une application console, un site web, une application mobile ou WPF…
Installer le service Azure Search
On installe Azure Search via le portail Azure, pour cela il vous faut un compte live. Si vous n’avez pas de compte, n’hésitez pas à vous inscrire, Microsoft propose des offres intéressantes pour les nouveaux venus.
Tarification
Au niveau du pricing, Microsoft à une offre pour toutes les bourses !

Installation du service
Azure Search peut s’installer via le portail, mais pas seulement : Azure CLI, Powershell et Powershell DSC ou même via les API Azure.
L’installation du service via le portail Azure
Pour ajouter le service au groupe de ressources, cliquer sur le bouton ajouter, puis dans la barre de recherche, taper « Azure Search », sélectionner puis cliquer sur créer.

Importer les données vers le service
La collecte de données vers l’index peut se faire à partir d’Azure DocumentDB, Azure SQL Database, Azure Blob Storage…
Aujourd’hui, nous allons nous intéresser à la collecte de données via Azure Sql Database.
Au niveau de notre service de recherche que nous avons nommé « cellenzademoazuresearch » nous procédons aux étapes suivantes :
- Import des données à partir d’une table

- Sélectionner un « data source »
On sélectionne « Azure SQL Database », l’objectif est de connecter notre base de données au Data Source.
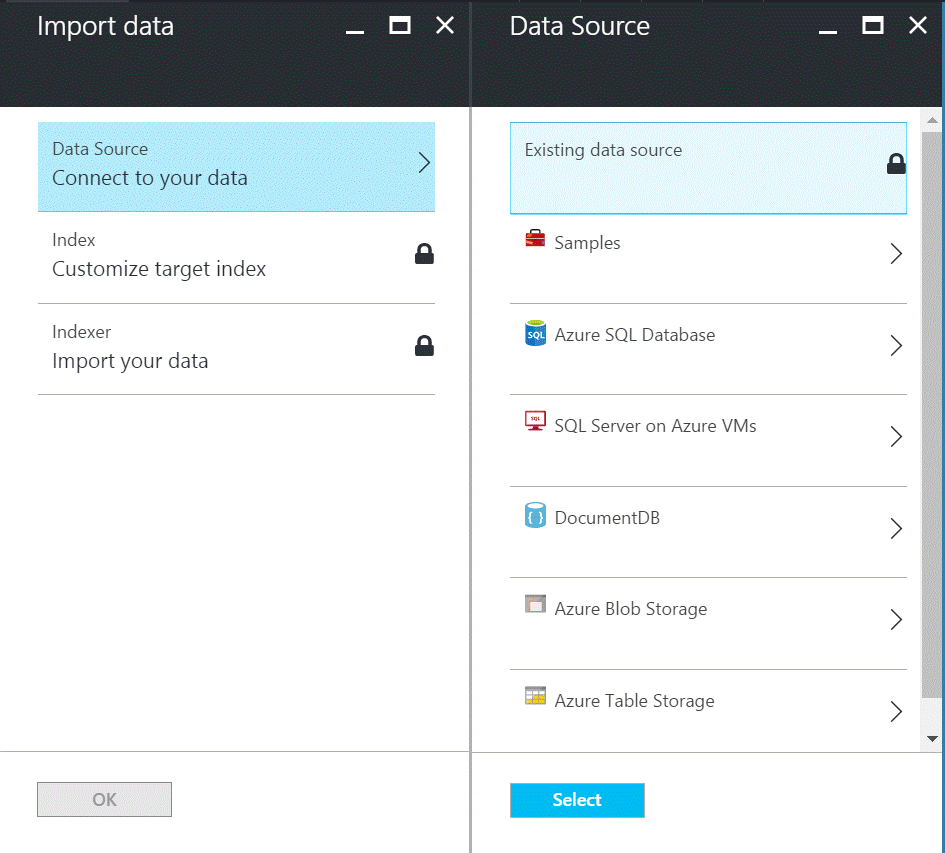
- On Renseigne les infos de connexion de la base de données « azuresearchdemo » et on teste la connexion.

- Sélectionner la table ou la vue que vous souhaitez indexer.
Ici, nous allons importer vers l’index les données de la table « SalesLt.Customer ».
Notons qu’il est aussi possible d’importer des données à partir d’une vue.

Nous avons maintenant choisi de collecter les données de la table « SalesLT.Customer ».
Maintenant il faut configurer les champs de l’index, nous allons procéder comme suit :
Configuration de l’index
Après la création du « DataSource », nous sommes automatiquement redirigés vers l’écran de configuration de l’index.
Nous y retrouvons toutes les colonnes de table « SalesLT.Customer ». Ces colonnes sont aussi automatiquement typées en correspondance avec le type correspondant à la table.
Je donne un nom à notre index, ce nom doit être en minuscule. Et je définis une clé, naturellement je donne la clé primaire de ma table.

Les attributs Retrievable, Filterable, Sortable, Facetable et Searchable peuvent être définis lors de la création de l’index. Tout d’abord nous allons les définir :
- Retrievable (récupérable)
Définit si le champ peut être renvoyé dans un résultat de recherche. - Filterable (filtrable)
Permet de référencer le champ dans les requêtes $ filter.
Les champs de type Edm.String ou Collection (Edm.String) qui sont filtrables et ne subissent pas de rupture de mot, donc les comparaisons sont pour les correspondances exactes seulement.
Par exemple, si vous définissez un champ de type Edm.String avec une valeur à « jour ensoleillé », $ filter = f eq ‘ensoleillé’ ne trouvera pas de correspondance, mais la trouvera pour $ filter = f eq ‘jour ensoleillé’. - Sortable
Par défaut, le système trie les résultats par score, mais il est fort probable que les utilisateurs voudront trier par champs les documents. - Facetable
Utilisé dans une présentation des résultats de recherche qui inclut le nombre de hits par catégorie (par exemple, recherche d’appareils photo numériques et voir les hits par marque, par mégapixels, par prix, etc.). - Searchable
Marque le champ en tant que recherche de texte intégral. Cela signifie qu’il subira une analyse telle que la rupture de mot lors de l’indexation.
Si vous définissez un champ de recherche à une valeur comme « jour ensoleillé », à l’interne, il sera divisé en jetons individuels « ensoleillé » et « jour ».
Cela permet des recherches en texte intégral pour ces termes.
Les champs de type Edm.String ou Collection (Edm.String) sont consultables par défaut.
Nous allons définir les champs « LastName« , « FirstName » et « CompanyName » comme « Filterable« , cela nous permettra de faire une recherche par filtre sur ces champs.
Nous allons mettre l’ensemble des champs en « Retriviable » parce que nous voulons récupérer l’ensemble des champs de l’index sauf « PasswordHash » et « PasswordSalt« , par mesure de sécurité.
Nous allons également mettre les champs « CustomerID« , « FirstName« , « LastName » et « CompanyName » en « Sortable » cela nous permettra de faire un tri sur chacun de ces champs.
Pour finir, nous mettrons l’option « Searchable » sur l’ensemble des champs de type « Edm.String« , ça nous permettra de faire une recherche full text sur ces champs.
Nous verrons l’option « Facetable » dans un autre post.

Import des données dans l’index
Pour que l’index soit mis à jour automatiquement, nous pouvons configurer le Scheduler.
Nous choisissons une mise à jour toutes les heures, mais il est possible de charger l’index qu’une seule fois avec l’option «Once», chaque jour avec «Daily» ou «Custom» pour une mise à jour de l’index selon les critères de votre choix.
La colonne «High watermark column» est utilisée pour déterminer si la ligne a changé depuis la dernière exécution de l’indexeur.
Nous sélectionnons la colonne «ModifiedDate» qui est un type « DateTime ». Il est recommandé d’utiliser une colonne de type «RowVersion» ou un « TimeStamp ».
Et voila, c’était la dernière étape, notre service est maintenant configuré !
Notre index est maintenant accessible à partir de la page d’accueil du service, nous avons des informations essentielles comme le nombre de documents et l’espace disque occupé par notre service.
Search Explorer
Cet outil va nous permettre d’interroger notre index à l’aide de filtre Odata.
Les principaux mots clés pour filtrer la requête au service
- Search
Tous les champs consultables sont recherchés par défaut, à moins que les champs de recherche ne soient spécifiés. Les termes multiples peuvent être séparés par des espaces blancs. - highlightPreTag
Par défaut, (facultatif, la valeur par défaut est<em>) , balise de chaîne qui ajoute un préfixe aux mises en surbrillance des correspondances trouvées. Doit être défini avechighlightPostTag.
Les caractères réservés dans l'URL doivent être encodés en pourcentage (par exemple, % 23 au lieu de #).
- highlightPostTag
Par défaut, . (facultatif, la valeur par défaut est</em>) : balise de chaîne qui ajoute un élément aux mises en surbrillance des correspondances. Doit être défini avechighlightPreTag.
Les caractères réservés dans l’URL doivent être encodés en pourcentage (par exemple, % 23 au lieu de #). - $filter
Filtre d’expression Odata, il permet d’effectuer une recherche OData structurée uniquement sur les colonnes de l’index paramétrées comme « Filterable ».
Exemple de requête
Nous allons analyser la requête suivante
« search=’Eric’&$select=*&$top=10&highlightPreTag=’‘&highlightPostTag=’‘ »
Description de la requête :
- search :
Nous cherchons le mot « Eric » dans toutes les colonnes de l’index configurées comme « Searchable ». - top :
Nous remontons les 10 premiers résultats - Select :
Nous voulons toutes les colonnes de l’index (select). - highlightPreTag et highlightPostTag :
Le mot rechercher sera encadré du tag html « ».
L’outil nous renvoie 10 lignes de l’index ou les colonnes contiennent le mot « Eric ».

Nous avons donc vu ensemble comment créer un index sur le service Azure Search dont les données sont collectées à partir d’une base de données Azure SQL Database.
Il est assez simple de brancher le service Azure Search sur votre site web ou application mobile et profiter d’un moteur de recherche rapide fiable et de haute disponibilité !