

Cas d’usage – extraction du data lineage Prérequis : Databricks runtime 17.0 (June 2025 – Link), Databricks Unity catalog, accès...
5 septembre 2024
AutoML custom dans Databricks avec MLflow

Le Machine Learning automatisé (ou AutoML) est une méthode d’optimisation des paramètres pour vos modèles de Machine Learning (ML). Il consiste à explorer et tester de manière automatique (d’où le « auto » dans AutoML) une étendue plus ou moins large de certains ou de tous les paramètres possibles d’un modèle, et à regarder l’impact en bien ou en mal sur la précision du modèle en question. On génère donc plusieurs modèles avec des paramètres aléatoires ou optimisés pour minimiser un critère d’évaluation, pour ne garder à la fin que le meilleur modèle par rapport à ce critère d’évaluation. Databricks propose déjà via l’interface « Machine Learning » > « Experiments » la création d’expériences de tests sur plusieurs types de problème ML :
- La classification
- La régression
- La projection (time series)
L’utilisation de l’interface de Databricks rend l’utilisation d’AutoML très simple, sans développement de code, mais assez peu customisable. Je vous propose de voir dans cet article comment personnaliser l’exploration des paramètres en Python avec les librairies mlflow, hyperopt et hpsklearn.
Prérequis
Le compute
Le choix du compute est important et fait toujours l’objet d’un compromis entre vitesse d’exécution et coût. Plus le cluster créé est puissant, plus il sera cher évidemment. Pour nos tests, nous vous recommandons un petit cluster :
- Policy : Personal Compute
- Runtime : 12.2 LTS ML (Scala 2.12, Spark 3.3.2)
- Worker type : Standard_DS3_v2
Les librairies python
Une fois le cluster créé, vous devez installer les dépendances suivantes :
PyPi :
- catboost==1.2.5
- databricks-automl-runtime
- hyperopt==0.2.5
- hpsklearn@git+https://github.com/hyperopt/hyperopt-sklearn@4b3f6fde3a1ded2e71e8373d52c1b51a0239ef91
- Imblearn
- lightgbm==3.3.4
- lxml==4.9.3
- mlflow
- numpy>=1.21.2
- pandas==1.4.2
- scikit-learn>=1.0,<1.2
- scipy>=1.7.1
- xgboost==1.7.2
- # vacances-scolaires-france==0.10.0
- # jours_feries_france==0.7.0
- # azure-storage-blob==12.17.0
- # holidays>=0.11.1.3,<0.14
- # category_encoders
Les expériences Databricks :
En choisissant l’option « Create AutoML Experiment » dans Databricks, vous pouvez accéder à une interface vous permettant de configurer en mode « no code » votre expérience, et notamment par les paramètres suivants :
- Le choix du compute et du cluster utilisé pour l’AutoML : Cluster
- Le type de problème à résoudre (cités ci-dessus)
- Les données d’entrainement d’entrée
- L’objectif de prédiction (c’est-à-dire la colonne cible)
- Le nom de l’expérience, c’est-à-dire le nom de l’« Experiment » dans Databricks
- Dans l’onglet de configuration avancée (options facultatives) :
– La métrique d’évaluation (dépend du type de modèle choisi, mais peut être le score F1 pour une classification par exemple, ou bien le score R2 pour une régression)
– Le Frameworks d’entrainement :
-
- Lightgbm
- Skealrn
- Xgboost
– La condition d’arrêt :
-
- Le délai d’expiration en minutes, par défaut 120 minutes
- Le nombre de tests d’exécution, par défaut 200 (peut être absent selon la version de l’environnement Databricks)
– L’emplacement de stockage des données intermédiaires (peut être absent selon la version de l’environnement Databricks)
L’interface vous permet même de prendre en charge les valeurs manquantes (s’il y en a) et de les imputer pour vous selon plusieurs méthodes (mean, max, min, most frequent value, auto). Si vous démarrez l’expérience ainsi, vous verrez au rechargement de la page toutes les exécutions enregistrées, les scores, la durée d’exécution pour chaque run, etc.
Vous allez pouvoir lancer votre première expérience AutoML avec Databricks. Le temps de calcul dépend du type de cluster choisi, et de la quantité de données présentes dans le dataset.

Figure 1 : Exemple d’une classification sur le dataset iris si bien connu
En cliquant sur les liens dans la colonne « Source », vous pouvez même accéder au notebook généré automatiquement qui a conduit à ces résultats, et ainsi extraire les paramètres optimisés. Les modèles sont également logés dans MLflow, et peuvent être récupérés via une ID. En consultant le code dans le notebook, nous pouvons constater que le jeu de donné initial est divisé en 3 sous-datasets :
- 60 % de train
- 20 % de validation
- 20 % de test
Ces datasets nous permettent de (1) entrainer le modèle sur 60% des données, de (2) tuner => évaluer => valider (ou non, auquel cas on repart sur l’étape (1)) les paramètres du modèle en cours d’affinage, et de (3) tester le modèle avec les paramètres optimisés et figés.

Figure 2 : Processus d’optimisation des paramètres du modèle
Un code AutoML customisé
La création d’expérience sur Databricks est plutôt intuitive et facile, néanmoins, elle ne permet pas de personnaliser certains aspects tels que les fenêtres d’exploration autorisées pour les paramètres, ou encore le choix des modèles à explorer. Elle ne permet pas non plus d’automatiser le processus d’AutoML dans un pipeline Databricks.
Je vous propose de voir ensemble un code qui permet de résoudre tous ces problèmes. Ce code est bien entendu personnalisable pour vos usages. Pour notre exemple, nous allons utiliser les librairies lightgbm, xgboost et catboost. Nous allons voir ensemble comment utiliser les librairies hyperopt et hpsklearn pour tuner les paramètres de nos modèles.
La création des espaces de recherche
Ici, nous allons définir les espaces à explorer pour nos différents paramètres. Il va de soi que ces espaces dépendent des modèles, et chaque modèle dispose de ses propres paramètres. Pour cela, nous utilisons hyperopt pour créer les fenêtres à explorer avec les fonctions :
- choice() : choisit un des éléments d’une liste fournie en argument
- uniform() : choisit une valeur uniformément comprise entre deux seuils ‘low’ et ‘high’ fournis en argument
- quniform() : applique la formule : round(uniform(low, high) / q) * q, choisit une valeur entre plusieurs variables discrètes, avec ‘low’, ‘high’ et ‘q’ fournis en argument
- loguniform() : applique la formule : exp(uniform(low, high)), choisit une valeur sur une distribution uniforme entre ‘low’ et ‘high’ fournis en argument
Je vous invite à en lire davantage sur le choix des fenêtres des paramètres sur la documentation d’hyperopt : Defining search spaces – Hyperopt Documentation
Recherche des meilleurs paramètres avec fmin() et les librairies hyperopt et hpsklearn
Maintenant, rentrons dans le vif du sujet, et regardons comment nous pouvons explorer nos trois modèles pour en tirer le meilleur. Je vous propose de créer une classe AutoML :
Comme vous pouvez le constater, cette classe AutoML prend un certain nombre de variables pour être instanciée :
- exp_name: Le nom de l’expérience : string
- prepared_data: Les données préparées : pd.DataFrame()
- features_col_name : La liste des noms des colonnes features à utiliser : list[string]
- target_col_name: Le nom de la colonne cible : string
- time_col_name: Le nom de la colonne temps ou index : string
- results_col_name: Le nom de la colonne résultats, ici « Predictions » par défaut : string
- residual_col_name: Le nom de la colonne des résidus, dans laquelle sera stockée la différence entre la réalité et la prédiction, « Residuals » par défaut : string
- split_param: Les paramètres de split de, par défaut {« train »: 60, « val »: 20, « test »: 20} : dict
- max_iteration: Le nombre d’itérations maximal, c’est-à-dire le nombre de boucles d’exploration (cf. Figure 2) : integer
- time_out: Le temps en seconde maximal pendant lequel on va parcourir la boucle d’exploration (cf. Figure 2) : integer
- model_type: Le type de modèle, entre « regression » et « classification » : string
- sorting_metric: Le nom de la métrique d’évaluation sur laquelle nous choisirons le meilleur modèle : string
Nous ajoutons à cela plusieurs variables de classe qui sont les dataframes pandas vides qui permettront de créer les datasets de train, de val et de test pour les colonnes features (X) et pour la cible (y).
Il est temps de créer notre première fonction dans cette classe AutoML : elle permet de splitter le dataframe en utilisant le paramètre split_param et le dataframe prepared_data passés en entrée.
Nous utilisons SMOTE(), pour homogénéiser le jeu de données dans le cas d’une classification, notamment si nos catégories ne sont pas représentées de façon homogène :
Une seconde fonction permet de tracker et de stocker les modèles grâce à MLflow. Nous pouvons également y intégrer des calculs pour les scores, qui seront eux-mêmes stockés avec le modèle. Les métriques d’évaluations des modèles seront précédées par les préfixes training_, val_ et test_ pour permettre une meilleure lecture des résultats. Dans le cas d’une régression, nous regarderons le r2, et dans le cas d’une classification, nous regarderons le score f1 pour comparer les modèles produits par l’AutoML :
La fonction suivante est la plus importante dans la classe AutoML : elle utilise fmin() qui est la fonction de minimisation et de recherche des meilleurs paramètres. Je vous invite à en lire davantage ici : Minimizing functions – Hyperopt Documentation. Ici, nous passons deux éléments à cette fonction hyperopt_procedure(), qui sont la fonction à optimiser : objective, et l’espace à explorer : space (ceux que nous avons créés dans le second bloc de code). Comme nous pouvons le voir, nous passons également un algorithme d’optimisation, ici tpe.suggest et le nombre d’itérations maximal pour ce run max_iteration, argument d’instanciation de la classe.
Les fonctions objectives objective_<framework> maintenant, il y en a 3 : une pour chaque algorithme à explorer, où nous instancions les trois modèles, ce sont ces fonctions qui seront optimisées par hyperopt. Chacun des trois frameworks nous permet d’instancier un régresseur Regressor et un classifier Classifier. Si vous avez de nouveaux frameworks à explorer, il faudra créer une nouvelle fonction objective_<framework> avec l’instanciation des deux types (regresseurs/classifiers) :
Pour continuer, nous ajoutons deux fonctions pour exploiter les librairies hyperopt et hpsklearn, et permettre les logs des scores et des autres métriques toujours grâce à MLlflow. On constate que la complexité de développement est moins importante avec hpsklearn qu’avec hyperopt, car nous n’avons pas besoin de créer les classes objectives ni les espaces d’exploration. Néanmoins, nous avons moins la main avec hpsklearn :
Nous y sommes presque : plus qu’une fonction qui va extraire les meilleurs résultats avec cette dernière fonction. Cette fonction nous permet simplement de sortir les meilleurs scores r2 et f1 sur les différents jeux de données :
Notre premier run d’AutoML sur une régression
Et voilà ! Nous pouvons faire notre première régression avec notre classe AutoML, par exemple sur le dataset diabetes de sklearn. Il faut savoir que le temps d’exécution de ce code dépend du cluster utilisé (puissance de compute), de la taille du dataset (nombre de lignes) et du nombre d’itérations maximal que nous voulons faire pour optimiser nos paramètres :
Et voici nos résultats :

Figure 3 : Dataframe en sortie d’AutoML régression sur le dataset diabetes
Nous pouvons également apprécier les résultats dans l’onglet « Experiments » de Databricks, car tout a été loggé avec MLflow. En cliquant sur le + à côté de « Afficher plus de colonnes », on peut apprécier les scores loggés par MLflow, et classer nos modèles en fonction de ces scores et métriques.

Figure 4 : Visualisation des résultats dans l’onglet « Experiments »
Ici, nous pouvons voir que le r2 sur le jeu de donnée train est très bon, mais pas sur les jeux de donnée test et val. Il semblerait que le split du dataset n’ait pas été fait de manière aléatoire, ce qui ne permet pas d’avoir suffisamment d’homogénéité dans les jeux de données d’entrée, et peut causer de mauvais résultats. Un autre facteur peut également nous donner de mauvais résultats sur un AutoML, comme des fenêtres d’exploration ne contenant pas les combinaisons des meilleurs paramètres pour le cas des données utilisées.
Notre premier run d’AutoML sur une classification
Nous pouvons tester la classe AutoML() sur une classification désormais, c’est le plus pertinent sur notre exemple de données breast_cancer :
Une fois le calcul terminé, nous pouvons déjà voir les premiers résultats directement dans le notebook :
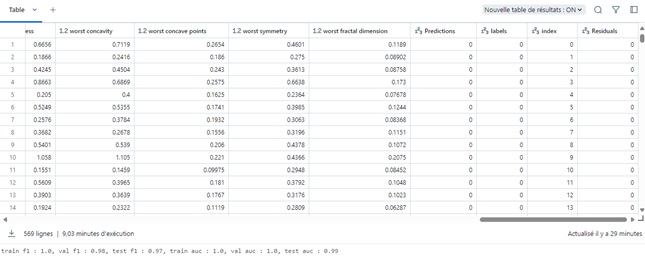
Figure 5 : Dataframe en sortie d’AutoML classification sur le dataset breast_cancer
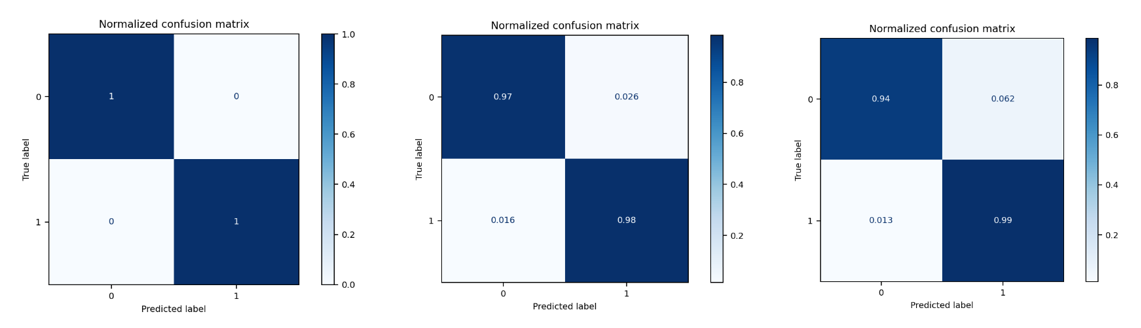
Figure 6 : Matrices de confusion pour les jeux de données train, val et test respectivement
Nous pouvons apprécier les résultats tout comme pour la régression :

Ici, on peut constater que les scores f1 entre les différents modèles et les datasets train, val et test sont très différents. Les résultats sont classés par valeur de score sur le dataset test, et nous pouvons donc voir en haut les meilleurs modèles et en bas les modèles les moins bons. Le meilleur modèle est un catboost classifier.
Attention tout de même à l’overfitting : nous pouvons voir que certains modèles ont des scores f1 et roc_auc égaux à 1, ce qui témoigne peut-être d’un overfit sur ces modèles.
Parallélisation du calcul avec SparkTrials
Pour tirer le meilleur parti de Databricks, et notamment de son compute, nous pouvons utiliser SparkTrials à la place de Trials :
Comme toujours, attention au coût du compute dans Databricks, tout n’est qu’une question de compromis entre le coût, le temps de calcul et la précision du modèle.
L’essentiel à retenir sur l’AutoML
L’AutoML est une méthode incontournable pour obtenir les meilleures combinaisons des paramètres, et ainsi obtenir les modèles les plus précis. Néanmoins, c’est une méthode coûteuse en compute et en temps : la qualité a un coût. Databricks est une plateforme intéressante pour ce genre d’expérience, car elle permet de mettre à disposition la capacité de calcul distribuée nécessaire pour ces problèmes exploratoires et d’optimisation.
Dans cet article, nous avons vu l’onglet « Experiments » de Databricks, et comment monter en « no code » une expérience et réaliser une exploration AutoML en quelques clics.
Puis, nous avons pu rentrer dans le détail du code et en faire une variante personnalisée, où nous pouvons utiliser / implémenter les classifiers et regressors que nous souhaitons, avec les fenêtres exploratoires que nous souhaitons, etc. Je vous invite à reprendre ce code et à l’adapter pour vos propres données, et tester la puissance de MLflow pour logger toutes vos métriques et récupérer vos modèles après entrainement.
Une fois que vous avez produit votre modèle et que vous souhaitez le mettre en production, je vous invite à vous intéresser au MLOps, ou comment surveiller et gérer les environnements et les modèles dans le contexte exigent de la production, grâce à notre article : Le MLOps en toute simplicité : rationaliser vos workflows ML avec Azure Machine Learning.






