

Comment RAJA Group a construit une plateforme data unifiée avec Microsoft Fabric – et comment Cellenza a contribué à écrire...
5 décembre 2023
Construction d’une pipeline CI/CD pour Databricks avec Azure DevOps

Le processus CI/CD (Continuous Integration – Continuous Delivery) est un incontournable des projets de développement de solutions, qu’elles soient Data, software ou autre. En ce qui concerne Databricks, la mise en place d’un tel process n’est pas toujours une évidence, mais dans cet article, on vous explique tout !
Pour ceux qui ne connaissent pas encore Databricks, c’est une solution Platform as a Service (PaaS) disponible chez plusieurs Cloud providers et notamment Microsoft Azure. Cette solution permet de réaliser des extractions, des transformations et des écritures de données à partir d’une source externe (par exemple une Azure SQL ou un Blob storage) ou interne sur le Databricks File Storage (DBFS). Elle propose une interface simple à prendre en main pour les Data Engineers qui s’intéressent plutôt à l’extraction, à la transformation et au chargement de la donnée, et pour les Data Scientists et Analysts qui sont plus orientés analyses et création de notebooks python/R dans l’onglet « Workspace », Machine Learning et autoML dans l’onglet « Experiments », ainsi que l’automatisation et l’ordonnancement de jobs dans l’onglet « Workflow ».
En ce qui concerne Azure DevOps, il s’agit d’un outil regroupant plusieurs briques fort utiles pour :
- l’écriture de notes ou de documentations techniques : « Overview »,
- la gestion de projet (SCRUM ou AGILE) : « Boards »,
- le versioning de code : « Repos »,
- ainsi que la conception de pipeline CI-CD : « Pipeline »
Les principales briques d’Azure DevOps dont nous allons parler ici sont « Repos » et « Pipeline ».
Mais pour commencer, il nous faut évoquer l’infrastructure nécessaire à la mise en place de ce processus, et ça passe déjà par la création d’au moins deux environnements : les environnements de développement « Dev » et de production « Prod ». Comme son nom l’indique, l’environnement de Dev est utilisé pour le développement et la mise en place d’évolutions d’une application. L’environnement de Prod est quant à lui destiné à l’usage par les utilisateurs finaux : il est donc important de bien séparer les deux, pour que l’apport de modifications au code n’impacte pas les utilisateurs dans leurs activités, d’autant plus qu’il est rare que tout fonctionne du premier coup. Il est important de mettre en place des tests fonctionnels du code, et pour cela je vous invite à consulter notre précédent article : Les bonnes pratiques de tests unitaires PySpark.
Pourquoi mettre en place une pipeline CI-CD ?
L’avantage du CI-CD est de pouvoir travailler à plusieurs développeurs sur un même projet, tout en automatisant les tests et la mise en production du code lors d’évolutions, ce qui arrive souvent dans le cycle de vie d’une application. Cela passe tout d’abord par l’utilisation d’un « repository » ou « repo » et l’organisation du code en plusieurs branches. Similaire à GitHub ou GitLab, Azure DevOps dispose d’une fonctionnalité Repos permettant aux développeurs d’un projet de versionner le code (utile pour revenir sur une version antérieure lorsque le ctrl + Z n’est plus une option), et de faire des revues par les pairs dans un processus appelé « Pull Request » ou « PR ». Dans les bonnes pratiques de développement, les collaborateurs travaillent en effet en « feature_branch », c’est-à-dire que pour chaque évolution ou ajout de fonctionnalité sur une application, le développeur travaille donc sur une branche dédiée basée sur la branche « Dev ». La branche « main » est la plus propre possible, elle est alimentée par la branche « Dev » lors des mises en production une fois la phase de recette et les tests réalisés avec succès. Cette branche « main » correspond au code exploité par l’environnement de production « Prod ». Lorsque le développeur estime avoir apporté les modifications nécessaires à l’évolution sur laquelle il travaille, il peut alors créer une PR et y attribuer des reviewers.
Les reviewers doivent relire le code, peuvent apporter des commentaires, demander des corrections, et finalement, accepter la PR. Lorsque tous les reviewers ont terminé cette étape de relecture, ils peuvent accepter la PR qui sera ensuite validée. Ce processus de validation peut être paramétré en « auto-completion » : cela signifie qu’à l’acceptation du code par tous les pairs, on valide automatiquement la PR, la branche Dev est mise à jour avec le code contenu dans la feature_branch et cette dernière est supprimée. À l’issue de cette validation, le code est poussé sur la branche de développement « Dev », et c’est là que ce déclenche notre pipeline de CI-CD.

Figure 1 : Processus global d’une pipeline CI-CD conçue sur Azure DevOps pour Databricks
La pipeline CI-CD est en fait une suite d’étapes (voir Figure 1), comme dit précédemment, déclenchée par la mise à jour de la branche de Dev, normalement à la suite d’une PR.
Prenons un exemple : Adrien développe ses évolutions dans la branche us_4242_compute_new_metric_feature_branch et décide de créer une PR à la fin de son développement relatif à la User Story (US) 4242. La PR est relue, validée et complétée par les reviewers (étape 1). Ensuite, la branche de Dev est mise à jour avec les modifications d’Adrien (étape 2). La troisième étape de la pipeline met donc à jour le code dans la branche de Dev dans le Databricks de Dev. S’ensuit le déclenchement des jobs de test sur cette même instance de Databricks, la pipeline est en attente de la réalisation de ces tests et d’une issue « successfull » ou bien « failed » (étape 3). Si, et seulement si, les tests sont réalisés avec succès, alors la pipeline va mettre à jour le code de la branche main dans Azure DevOps et mettre à jour le code dans le Databricks de l’environnement de Prod (étapes 4 et 5). Ceci aura pour effet de pousser les évolutions d’Adrien aux utilisateurs finaux.
Intéressons-nous maintenant à la mise en place de la pipeline CI/CD
Prérequis à la mise en place de pipeline CI/CD
En considérant que vous avez bien les deux environnements créés dans Azure, que votre code est bien organisé dans les branches de Dev et main dans Repo, et que vous avez déjà créé le ou les notebooks de tests sur le Databricks de l’environnement de Dev, on vous explique à présent comment faire pour mettre en place la pipeline CI-CD dans Azure DevOps.
Le service principal
Tout d’abord, vous devez créer un principal de service ou service principal (SP), et ça se passe dans Azure.
Dans le portail Azure, tapez « Microsoft Entra ID » dans la barre de recherche puis, dans la vue d’ensemble, cliquez sur « Inscription d’applications ». Il nous faut ajouter une application en cliquant sur « + Nouvelle inscription ». Donnez un nom, comme par exemple « Databricks-sp », et validez. Notez l’ID d’application (client) car nous en aurons besoin plus tard.
Nous allons maintenant linker ce service principal à Databricks. Pour cela, dans votre espace de travail, en haut à droite, cliquez sur « Paramètres d’administration », puis « Identité et accès » et « Gérer » à côté de « Service principals ». Renseignez ensuite la valeur copiée précédemment, c’est-à-dire l’Application ID et donnez un nom à votre service principal.

Figure 2 : Ajout d’un principal de service à Databricks
Création du cluster dans Databricks
Il nous faut créer un nouveau cluster de calcul sur Databricks, qui sera dédié à la pipeline CI-CD.
Dans l’onglet « Calculer », choisissez « Créer un compute », dans la nouvelle page, renommez le cluster « CI-CD cluster ». Choisissez la taille du cluster et les policies de dimensionnement et d’arrêt. Cliquez sur « Créer un compute » et récupérez l’id du cluster en cliquant sur « JSON » en haut à droite, puis cherchez « cluster_id » dans le json qui s’affiche. Avant de passer à la suite, il faut donner l’autorisation à votre service principal de démarrer ce cluster : dans « … Plus », puis « Autorisations », sélectionnez votre service principal et attribuez-lui l’option « Gestion autorisée », cliquez sur « Ajouter » puis sauvegardez.
Création de la pipeline
Dans Azure DevOps, rendez-vous sur l’onglet « Pipeline », puis « New pipeline ». En fonction de votre aisance avec le format YAML, vous pouvez écrire à la main le fichier .yml ou bien choisir l’option tout en bas « Use classic editor to create a pipeline without YAML ». De là, vous pouvez choisir parmi les 6 options de Repo. Dans notre cas, comme le code est dans le Repo Azure DevOps, nous choisirons l’option correspondante : « Azure Repo Git ». Sélectionnez ensuite le projet dans « Team project », le Repo concerné « Repository » et la branche main dans « Default branch for manual and scheduled builds », puis « Continue ».

Figure 3 : Création d’une nouvelle pipeline dans Azure DevOps
Puis dans « Select a template », choisissez « Empty job ». Vous venez de créer votre première pipeline vide. Pour renommer votre pipeline, vous pouvez cliquer sur le nom de la pipeline (qui est défini par défaut en se basant sur le nom du Repo choisi) pour le modifier, ou la renommer dans la partie droite « Name ».
Dans « Agent Pool », laissez « Azure Pipelines » par défaut, et dans « Agent specification », vous pouvez choisir un agent « Ubuntu 20.04 » : cela aura pour effet de réduire le temps d’instanciation de l’agent par rapport à un agent Windows, mais ce choix n’aura pas d’autres conséquences.

Figure 4 : Paramètre de la pipeline après sa création
Dans l’onglet « Variables », cliquez sur « Manage variable groups » puis « + Variable group » dans la nouvelle page qui s’est ouverte. Choisissez un nom comme « Databricks variables » et ajoutez une description (optionnelle). Puis sur « add » ajoutez les variables suivantes :
- « Name » : « DATABRICKS_ADDRESS » et Value : https://<votreespacedetravaildatabricks>.azuredatabricks.net/
- « Name » : « DATABRICKS_API_TOKEN » et Value : <votretokenPAT>
- « Name » : « DATABRICKS_CLUSTER_ID » et Value <votreclusterCICD>
Pour rendre secrète la valeur, vous pouvez cliquer le cadenas à droite de chaque ligne, puis appuyez sur « Save » pour sauver ce groupe de variables :

Figure 5 : Création d’un groupe de variable dans Azure DevOps
Il faut maintenant linker le groupe de variables à la pipeline. Retournons sur la page de la pipeline et rafraichissons la page « Variables ». Puis dans « Link variable group », choisissez le groupe « Databricks variables » que nous venons de renseigner. Il est temps pour nous de créer les taches de la pipeline CI-CD.
Dans « Tasks », sous « Pipeline Build Pipeline », cliquez sur « Get sources » et vérifiez que le projet, le Repo source, la branche par défaut sont bien les bons. Votre pipeline est pour l’instant composée d’un seul agent appelé « Agent job 1 ». Vous pouvez cliquer dessus pour que, dans la partie de droite, de nouveaux paramètres apparaissent, et en dessous de « Additional options », cochez « Allow scripts to access the OAuth token ». Dans « Display name », vous pouvez rentrer le nom de votre premier agent, « Update dev repo on Databricks » et cliquer sur « + » pour y ajouter une nouvelle tâche. Dans la partie de droite, tapez Python dans la barre de recherche « Search » et choisissez « Use Python version » puis « Add » :

Figure 6 : Ajout d’une nouvelle tâche dans un premier agent
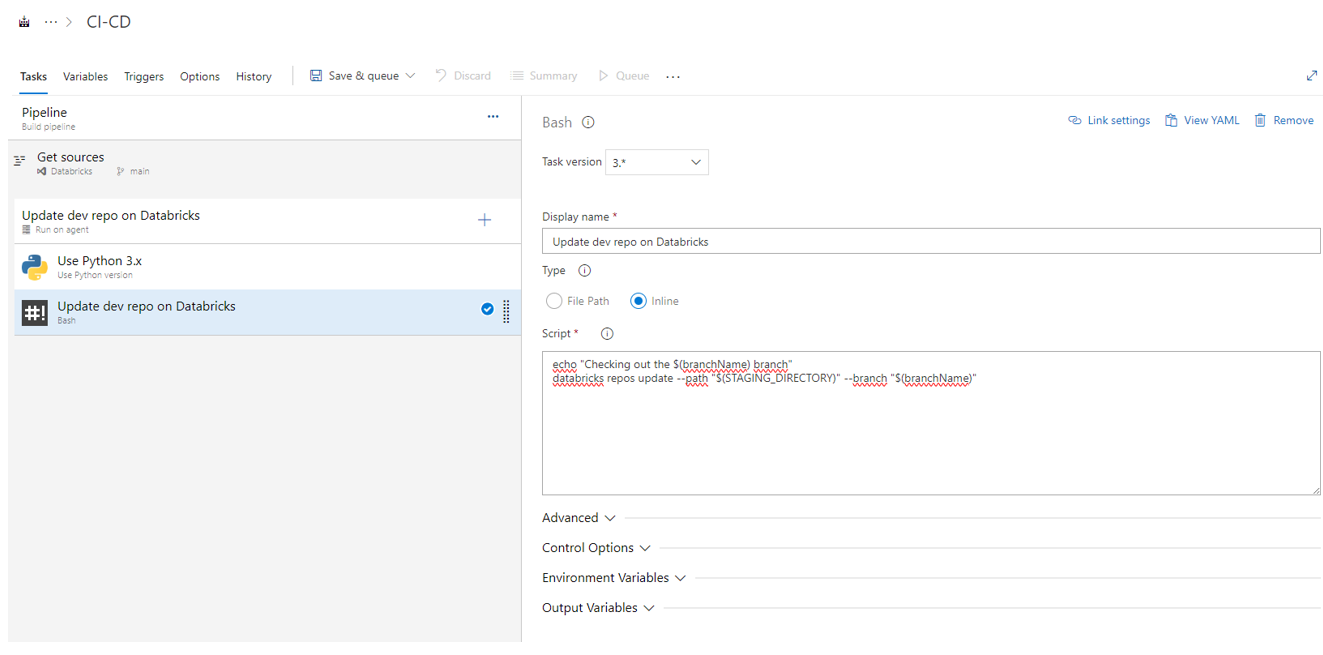
Une nouvelle tâche s’est ajoutée dans l’agent « Update dev branch on dev Databricks ». Cliquez sur cette nouvelle tâche et dans l’onglet de droite, modifiez uniquement le nom de la tâche dans « Display name » par « Use Python x » avec x la version de python nécessaire pour lancer le code des notebooks que nous allons tester. Faites de même dans la case « Version spec ». Ajoutez une nouvelle tâche « Bash » appelée « Install dependencies », et renseignez le « Script » suivant : « python -m pip install –upgrade databricks-cli. Ajoutez à nouveau une tache « Bash » appelée « Update dev repo on Databricks » et renseignez le script suivant :
echo "Checking out the $(branchName) branch" databricks repos update --path "$(STAGING_DIRECTORY)" --branch "$(branchName)"
Figure 7 : Paramétrage d’une tâche « Bash » pour le lancement d’un script « Inline »
Nous allons maintenant créer un nouvel agent afin de lancer les tests sur Databricks.
Tout en haut de la pipeline dans l’onglet de gauche, cliquez sur les « … » à droite de « Pipeline Build pipeline » puis « Add an agent job ». Un nouvel agent s’est rajouté à la suite du premier. Renommez ce nouvel agent « Run test job(s) on dev Databricks », ajoutez une dépendance dans « Dependencies » à l’agent « Update dev repo on Databricks » et choisissez « Only when all previous jobs have succeeded » dans « Additional options ».
Ajoutez une nouvelle tâche dans cet agent, cherchez « Databricks » dans « Search », et choisissez « Configure Databricks ». Dans cette nouvelle tâche que vous renommerez « Configure Databricks CLI », vous pouvez renseigner « Workspace URL » par « $(DATABRICKS_ADDRESS) » et « Access Token » par « $(DATABRICKS_API_TOKEN) ».
Ici, nous appelons les variables « DATABRICKS_ADDRESS » et « DATABRICKS_API_TOKEN » que nous avons précédemment créées dans le groupe de variable « Databricks CI-CD ». Ces informations permettent de pointer les tâches suivantes vers le Databricks de Dev et de renseigner le token PAT pour utiliser les APIs de l’instance de Dev. Ajoutez une nouvelle tâche « Exécute Databricks Notebook » que vous appellerez « Execute test », et dans « Notebook path (at workspace) », entrez le chemin du notebook de test : il doit commencer par « /Repos/ ». Dans « Existing Cluster ID », renseignez « $(DATABRICKS_CLUSTER_ID) ». Optionnellement, vous pouvez renseigner les paramètres nécessaires au démarrage du notebook au format .json dans « Notebook parameters ». Ajoutez une nouvelle tâche « Wait for Databricks Notebook exécution » et laissez la tâche telle quelle. Si vous avez plusieurs notebooks de test, vous devez recréer ces deux nouvelles tâches pour chaque notebook de test. Puis, créez un nouvel agent que nous appellerons « Merge dev into main », et dans l’onglet de droite, ajoutez les dépendances dans « Dependencies », sélectionnez tous les agents créés précédemment et choisissez « Only when all previous jobs have succeeded » dans « Additional options ». Pour terminer, cochez la case « Allow scripts to access the OAuth token » sous « Additional options ». Ajoutez une nouvelle tâche « Bash » et renseignez le script suivant :
Lors de cette étape, nous faisons un update de la branche main avec la branche Dev, et si vous n’avez pas coché la case « Allow scripts to access OAuth token », vous aurez des problèmes d’authentification non autorisée pour git.
Nous allons créer un dernier agent que nous appellerons « Update main branch on prod Databricks », et ajouter les dépendances aux agents précédents comme ce que nous avons fait pour tous les agents. Ajoutez une nouvelle tâche « Use Python x » et choisissez votre version de python, une tâche « Bash », renseignez le script « python -m pip install –upgrade databricks-cli » et terminez par une tâche « Bash » avec le script :
echo "Checking out the prod branch" databricks repos update --path "$(STAGING_DIRECTORY)" --branch "main"
Pour finir, nous devons paramétrer le trigger de notre pipeline. Pour cela, vous devez cliquer sur « Triggers », cocher « Enable continuous integration » et sélectionner la branche « Dev » dans « Branch specification ».
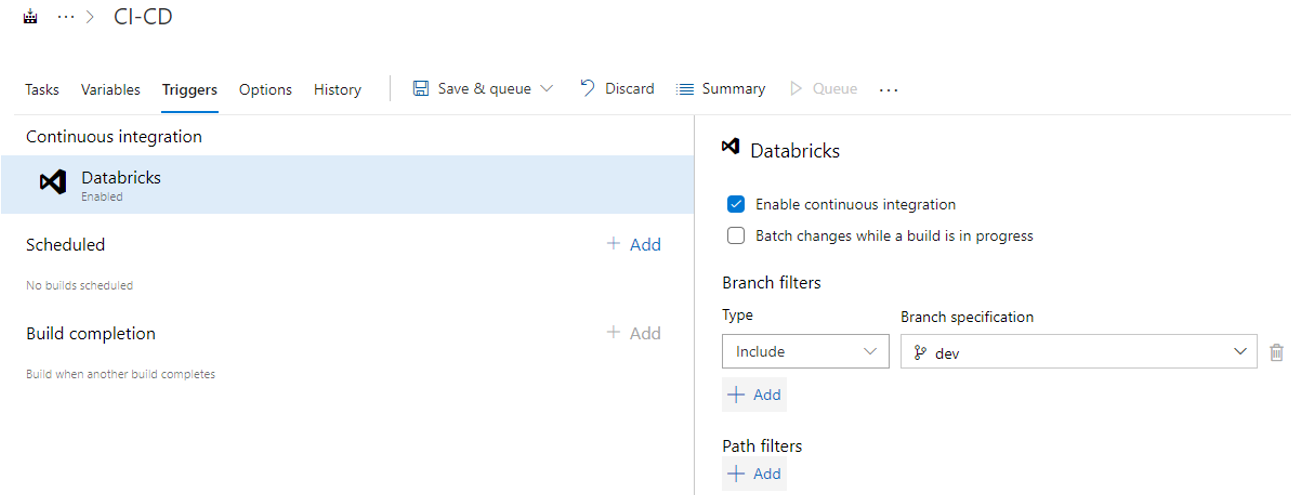
Figure 8 : Activation de l’intégration continue (automatisation) de la pipeline
Nous allons maintenant sauver notre pipeline (ne quittez pas la page trop vite sinon tout sera perdu !) et appuyer sur « Save & queue ». Dans l’onglet « Pipelines » puis « Pipelines », nous pouvons maintenant apprécier notre proccess CI-CD en cours sous « Recently run pipelines », et ainsi voir son statut sous « Last run » comme étant « successful » ou « failed ». Notez que si vous souhaitez en apprendre plus sur l’écriture de pipeline directement en yaml, vous pouvez cliquer sur « View YAML » lorsque vous sélectionnez un agent pour regarder le code qui se cache derrière l’interface Low Code de « DevOps Pipeline Editor » :
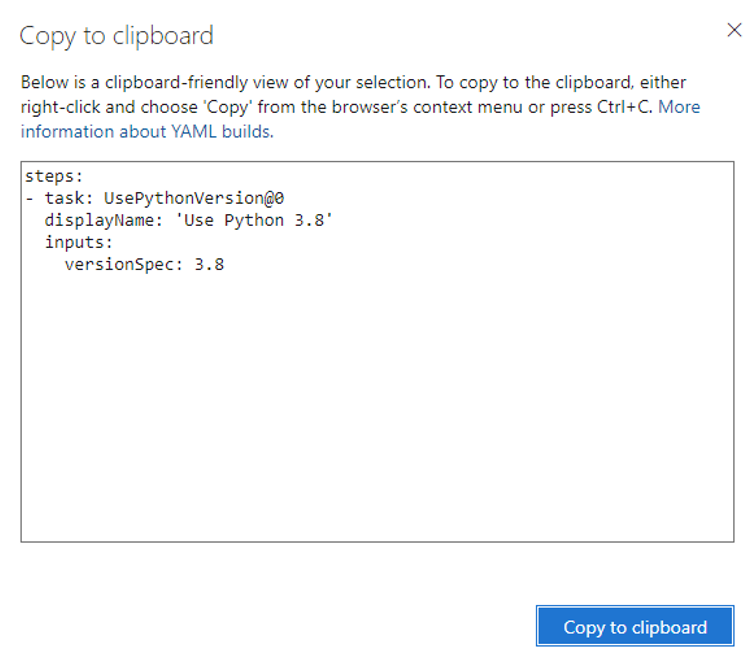
Figure 9 : Example de yaml pour la tâche d’instanciation d’une version de python
Et voilà, nous avons créé notre première pipeline ! Félicitations !
L’essentiel à retenir
Pour résumer, nous avons donc créé 4 agents :
- « Update dev branch on Databricks »
- « Run test job(s) on dev Databricks »
- « Merge dev into prod »
- « Update main branch on prod Databricks »
Nous avons tout d’abord (1) mis à jour le code du Databricks de Dev en utilisant des commandes git, (2) lancé les tests sur le Databricks de Dev afin de vérifier que le nouveau code n’induit pas de nouvelles erreurs avec le code déjà existant, et si tout se passe bien (3) nous avons mis à jour la branche main puis (4) nous avons mis à jour le code du Databricks de Prod. Pour faire un parallèle avec la Figure 1 de l’introduction, nous pourrions dire que (1) et (2) correspondent à l’étape 3, et que (3) correspond à l’étape 4 puis que (4) correspond à l’étape 5.
Nous avons donc vu pourquoi travailler avec le CI/CD est important, et comment mettre en place une pipeline CI/CD pour Databricks avec Azure DevOps. Nous avons vu par quelles étapes passait le code avant d’être poussé sur l’environnement de production, et ce afin de garantir la stabilité de l’application pour les utilisateurs.
Pour aller plus loin, vous pouvez consulter les yaml de chacun des agents, et comprendre la syntaxe pour vous affranchir de la construction via l’interface. La prochaine étape sera de réussir à créer une pipeline directement via un yaml, en l’important dans l’éditeur texte « Starter pipeline » proposé par Azure DevOps.
Vous souhaitez être accompagnés dans vos projets ? Contactez-nous !





