

Comment RAJA Group a construit une plateforme data unifiée avec Microsoft Fabric – et comment Cellenza a contribué à écrire...
5 décembre 2024
Data vs Développement : Identifier les blocages et optimiser les performances

Introduction
Les avancées récentes autour de la donnée et de son utilité stratégique poussent les entreprises à la considérer comme un levier essentiel de transformation. Exploiter les données permet de prendre des décisions plus éclairées, de mieux comprendre les publics et les processus, et de tirer parti des technologies d’intelligence artificielle. Face à ces opportunités, de plus en plus d’organisations se tournent vers des solutions Cloud et des stratégies data adaptées à leurs besoins.
Dans cette démarche, les projets Data démarrent souvent par une phase d’idéation et d’exploration. Cela permet de définir des cas d’usage, qu’il s’agisse d’analyses exploratoires pour la Business Intelligence (BI) ou d’initiatives avancées comme des modèles de machine learning. Il faut ensuite identifier le retour sur investissement (ROI) potentiel de ces projets pour valider leur pertinence. Cependant, ces cas d’usage ne sont qu’une pièce d’un processus plus large qui, correctement mené, évolue vers une industrialisation.
Les approches et stratégies nécessaires pour aboutir à ce résultat, souvent qualifiées de « stratégie Data », sont complexes à mettre en œuvre. La voie est semée d’obstacles techniques et organisationnels. En tant que cabinet de conseil expert du Cloud Microsoft, Cellenza accompagne les entreprises dans leurs projets de transformation numérique, en les aidant à structurer et déployer des stratégies data ambitieuses et sur mesure.
Cet article présente les spécificités des équipes data par rapport aux équipes de développement logiciel, leurs besoins spécifiques et les blocages courants. Il est expliqué pourquoi une approche identique pour les deux équipes mène souvent à des difficultés opérationnelles, ainsi que des solutions concrètes pour maximiser la valeur apportée par ces équipes à l’entreprise.
Différences entre une équipe Data et une équipe de Développement : Pourquoi les équipes Data rencontrent-elles des difficultés ?
Nature des missions et des processus
Les équipes de développement et les équipes Data ont des missions et des processus opérationnels fondamentalement différents, ce qui peut entraîner des incompréhensions lorsqu’elles sont gérées de manière identique.
Les équipes de développement travaillent dans un cadre où les objectifs sont généralement définis dès le départ. Leur mission est de livrer des logiciels ou des applications répondant à des spécifications précises, avec un périmètre délimité. Dans le cas où leur travail est itératif, ce processus s’applique à chaque itération : des phases successives de conception, de développement, de tests et de mise en production.
Les équipes Data, quant à elles, évoluent dans un environnement plus incertain. Leur mission inclut l’exploration, l’analyse et l’exploitation des données pour répondre à des problématiques variées. Ces problématiques peuvent concerner la Business Intelligence (BI), comme la création de tableaux de bord automatisés, ou des initiatives avancées en IA/ML, comme le développement de modèles prédictifs.
Les processus suivis par les équipes Data sont nécessairement itératifs et évolutifs. L’objectif initial peut être flou et s’affiner au fur et à mesure des découvertes. Parfois, ces découvertes modifient la direction du projet et génèrent de nouvelles possibilités. Les données peuvent se révéler une mine d’or ou, à l’inverse, peu exploitables. Cela exige une gestion adaptée et des interactions fréquentes avec les parties prenantes. Cette nature exploratoire peut frustrer les décideurs, qui attendent parfois des résultats plus rapides, similaires à ceux produits par les équipes de développement.
Temporalité et perception de la valeur générée
Une différence majeure entre les différents types d’équipe réside dans le délai et la perception de la valeur qu’elles apportent.
Pour les équipes de développement, la valeur générée est souvent tangible à court terme. Une fonctionnalité ou une application livrée peut immédiatement améliorer l’expérience utilisateur, automatiser un processus ou générer des revenus. Ces projets ont des cycles de vie relativement courts et des résultats mesurables rapidement.
À l’inverse, les équipes Data produisent une valeur souvent plus progressive et moins directement perceptible, car elle dépend du type de projet :
- Projets BI : Le retour sur investissement (ROI) peut être rapide grâce à l’automatisation et à la centralisation des indicateurs, mais la valeur perçue repose sur la fiabilité, l’acceptation des insights produits et leur utilisation.
- Projets IA/ML : Ces initiatives nécessitent plusieurs itérations avant de produire des résultats exploitables. Par exemple, la création d’un modèle prédictif peut nécessiter des ajustements constants, sans garantie de succès immédiat. Ces projets apportent une valeur stratégique à long terme, permettant des décisions mieux informées et des processus optimisés.
Cette différence dans la temporalité et la démonstration de valeur peut générer des tensions. Les parties prenantes peuvent s’impatienter face à des projets data qui n’offrent pas des résultats aussi immédiats que ceux des projets de développement. Cela souligne l’importance d’établir des attentes réalistes dès le début du projet et de communiquer régulièrement sur les avancées.
Les besoins spécifiques des équipes Data
Accès aux données et outils spécialisés
Les équipes Data s’appuient sur des données souvent complexes, dispersées et cloisonnées dans des systèmes hétérogènes (ERP, CRM, bases locales, etc…). Une part significative de leur travail consiste à collecter, nettoyer et préparer ces données, une étape critique mais chronophage.
Comparées aux équipes de développement, qui produisent des API ou des fonctionnalités plus visibles, les équipes Data nécessitent des infrastructures spécifiques pour supporter des workflows complexes, qu’il s’agisse de reporting BI ou de traitement avancé pour l’IA/ML. Ces infrastructures incluent des outils de traitement de données massives (Azure Databricks ou Fabric dans l’écosystème Microsoft, par exemple), des frameworks de machine learning (TensorFlow, PyTorch) ou des outils de visualisation (Tableau, Power BI, par exemple).
Sans une infrastructure adaptée, comme une data platform centralisant et rendant accessibles les données, le travail des équipes data peut être considérablement ralenti, limitant leur capacité à démontrer rapidement la valeur des projets.
Le manque d’accès fluide aux données, ou l’absence d’infrastructures adaptées, constitue l’un des principaux blocages pour les équipes Data. Leur travail dépend de la qualité et de la disponibilité des données, ralentissant l’avancement des projets et compliquant la démonstration rapide de la valeur ajoutée.
Par exemple, dans une entreprise de distribution, une équipe data souhaite analyser les données de ventes en temps réel pour optimiser les stocks et prévoir les ruptures. Cependant, ces données sont éparpillées entre plusieurs systèmes — un ERP, une base de données locale et un CRM dans le cloud. Sans accès centralisé et fluide à ces sources, l’équipe data passe un temps considérable à collecter et nettoyer les données, ce qui retarde l’analyse et limite l’efficacité des prévisions. En l’absence d’infrastructure adaptée, leur travail devient directement dépendant de la qualité et de la disponibilité des données disponibles, freinant ainsi la réactivité de l’entreprise face aux variations de demande.
Une approche séquencée : de l’idéation à l’industrialisation
La mise en place d’un projet Data peut se découper en trois grandes étapes :
- Étape 1 : Idéation et exploration
Lors de cette phase, les Data scientists et analysts collaborent avec les équipes métiers pour formuler des hypothèses, explorer les données disponibles, et tester des approches. L’objectif est d’identifier des opportunités et cas d’usage à fort potentiel, tout en évaluant les limites des données et des outils. Cette étape est cruciale pour démontrer la faisabilité et la valeur potentielle d’une initiative.
- Étape 2 : Proof of Concept (PoC)
Une fois un cas d’usage prometteur identifié, un PoC est développé pour démontrer la valeur ajoutée du projet. Par exemple, un modèle de machine learning peut être conçu pour améliorer la prédiction des ventes ou optimiser les processus de production. Cette phase permet de valider le ROI attendu et d’affiner les besoins en infrastructure.
- Étape 3 : Industrialisation et mise en production
Si le PoC est concluant, le projet passe à une phase d’industrialisation. À ce stade, la construction d’une data platform devient essentielle pour garantir la scalabilité et la pérennité du projet. Une plateforme centralisée permet d’automatiser les processus, d’assurer la gouvernance des données, et de rendre les résultats accessibles à grande échelle.
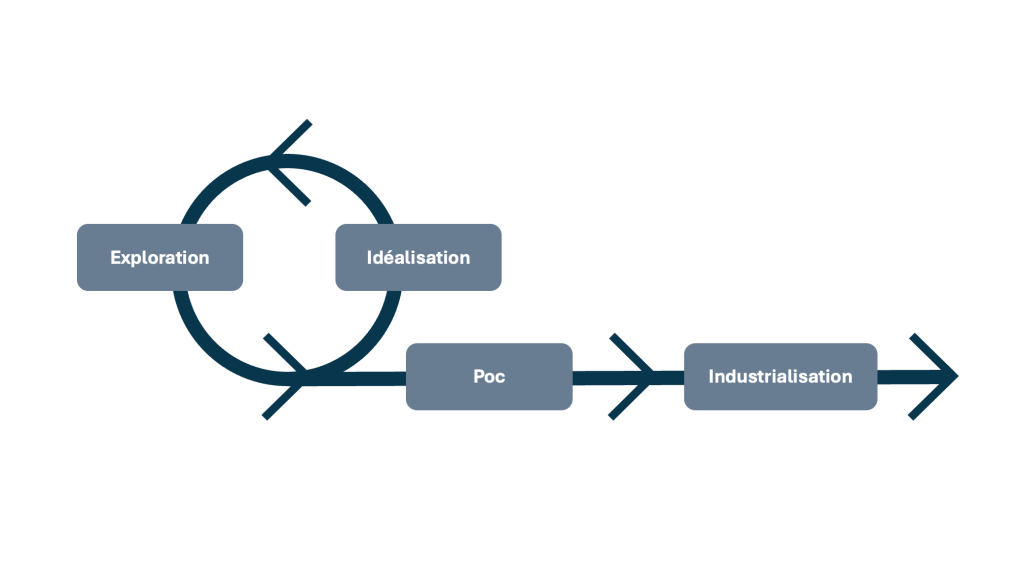
Méthodologies adaptées aux équipes Data : explorer, analyser, et industrialiser
Les équipes Data évoluent dans un cadre où l’incertitude est omniprésente et les objectifs peuvent changer au fil des analyses. Les projets data nécessitent donc des approches itératives et flexibles. Ces méthodologies permettent aux équipes de naviguer dans un environnement complexe et d’apporter une valeur mesurable tout au long du cycle de vie des projets, qu’il s’agisse de Business Intelligence (BI) ou de machine learning (ML).
Voici un aperçu des méthodologies les plus utilisées et prometteuses dans la Data science et l’ingénierie des données, répondant aux divers besoins des équipes Data.
CRISP-DM : une approche standard pour l’analyse de données
Le CRISP-DM est l’une des méthodologies les plus populaires pour les projets data. Elle se structure en six phases, chacune reflétant une étape clé du processus d’analyse de données :
- Compréhension métier : Définir les objectifs métiers et les exigences du projet.
- Compréhension des données : Analyser les données disponibles et identifier les éventuels problèmes.
- Préparation des données : Nettoyer, transformer et structurer les données pour les rendre exploitables.
- Modélisation : Construire des modèles via des techniques statistiques ou de machine learning.
- Évaluation : S’assurer que les résultats obtenus répondent aux besoins métiers.
- Déploiement : Mettre en production les modèles ou les insights générés.
CRISP-DM offre une approche robuste et flexible, idéale pour les projets où l’exploration des données joue un rôle central. La nature itérative de ce processus permet de revenir en arrière à tout moment pour ajuster les résultats en fonction des nouvelles informations découvertes. Toutefois, sa flexibilité peut ralentir le rythme de livraison si elle n’est pas bien gérée.
TDSP : une méthodologie collaborative signée Microsoft
Le Team Data Science Process (TDSP), développé par Microsoft, est une méthodologie pour structurer les projets Data tout en favorisant la collaboration entre les équipes techniques et métiers. Il intègre également des outils spécifiques à l’écosystème Microsoft.
Les principales étapes du TDSP comprennent :
- Planification : Identifier les cas d’usage, définir les objectifs et structurer l’équipe.
- Exploration des données : Collecter et analyser les données pour en comprendre la structure et détecter des opportunités.
- Modélisation : Concevoir et tester des modèles prédictifs ou analytiques.
- Déploiement : Intégrer les modèles dans des systèmes existants ou automatiser les pipelines.
- Amélioration continue : Effectuer des itérations pour améliorer les performances des modèles dans le temps.
Ce cadre méthodologique est particulièrement adapté aux environnements d’entreprise nécessitant des pipelines robustes et une collaboration étroite entre équipes.
DataOps : garantir l’efficacité des pipelines de données
Inspiré par les principes de DevOps, DataOps vise à optimiser l’automatisation, la qualité et la fiabilité des pipelines de données.
Les piliers de DataOps incluent :
- Automatisation des workflows : Réduction des interventions manuelles.
- Collaboration renforcée : Intégration étroite entre les data engineers, analysts et métiers.
- Surveillance continue : Mise en place de tests automatisés pour assurer la qualité des données.
DataOps est indispensable pour les environnements où des pipelines robustes sont essentiels, comme les systèmes BI temps réel ou les analyses prédictives à grande échelle.
Agile Data Science : itérations rapides et livraisons incrémentales
L’Agile Data Science applique les principes Agile aux projets Data. Cette méthodologie repose sur des cycles courts, appelés sprints, pour fournir des livraisons progressives et répondre aux besoins évolutifs des métiers.
Ses caractéristiques principales sont :
- Prototypes rapides : Validation des hypothèses et ajustement des priorités.
- Feedback continu : Incorporation des retours après chaque itération.
- Adaptabilité : Révision des objectifs en fonction des découvertes.
Cette approche est idéale pour les projets exploratoires, où la finalité reste encore incertaine.
ModelOps : optimiser les modèles en production
Contrairement à DataOps, qui se concentre sur les pipelines, ModelOps cible spécifiquement la mise en production et la maintenance des modèles analytiques ou prédictifs.
Les points clés incluent :
- Gestion des versions : Suivi des itérations des modèles.
- Déploiement automatisé : Intégration sécurisée dans les systèmes.
- Surveillance active : Détection des dérives ou baisses de performance.
ModelOps garantit que les modèles restent pertinents face aux évolutions des environnements.
Synthèse
En combinant des méthodologies structurées comme CRISP-DM et TDSP avec des approches modernes telles que DataOps ou ModelOps, les entreprises maximisent leur capacité à générer de la valeur tout en restant agiles face à l’incertitude.
Obstacles fréquents dans la mise en œuvre d’une stratégie Data
Malgré les promesses de la transformation digitale, de nombreuses entreprises rencontrent des blocages pour exploiter pleinement la valeur de leurs données. Ces blocages se manifestent à différents niveaux de l’organisation et freinent l’efficacité des équipes Data.
Accès limité aux données
Un des défis majeurs pour les équipes Data est le manque d’accès direct et fluide aux données. Les données d’une entreprise sont souvent cloisonnées, dispersées dans des systèmes hétérogènes (ERP, CRM, bases de données transactionnelles). Cette fragmentation complique la préparation des données pour l’analyse, d’autant que les questions de sécurité et de conformité imposent des processus d’accès complexes.
Manque de culture data-driven
Le manque de culture data-driven est un obstacle important dans la mise en place d’une stratégie Data. Sans une compréhension partagée de la valeur que peuvent apporter les données, les équipes métiers peuvent être réticentes à s’engager dans des projets basés sur l’analyse de données ou à ajuster leurs processus en conséquence. Cette résistance s’accompagne souvent d’une méfiance quant aux recommandations basées sur des modèles prédictifs ou des analyses exploratoires, surtout si les décisions reposent traditionnellement sur des intuitions ou des pratiques historiques.
Infrastructures techniques obsolètes
L’infrastructure technique d’une entreprise est la pierre angulaire de toute stratégie Data. Cependant, de nombreuses organisations sont encore limitées par des infrastructures obsolètes, peu adaptées aux besoins modernes en termes de traitement de données massives. Ces limitations incluent des systèmes de stockage inadéquats, des performances de calcul insuffisantes, et un manque d’outils de gestion de données avancés. Sans une infrastructure moderne, les équipes Data peinent à réaliser des analyses en temps réel, à manipuler des volumes de données importants ou à déployer des modèles de machine learning en production
Difficulté à recruter des experts Data
Les compétences nécessaires pour tirer de la valeur des données sont spécifiques et variées. Les équipes Data nécessitent des experts en machine learning, des Data engineers, des Data analysts et des spécialistes en visualisation de données. Toutefois, le recrutement de ces profils techniques est souvent difficile en raison de leur rareté sur le marché et des coûts associés. En outre, les entreprises doivent parfois combler des lacunes en matière de formation continue pour suivre l’évolution rapide des technologies et des méthodologies analytiques.
Stratégies pour maximiser la valeur des équipes Data
Pour transformer les défis en opportunités, les entreprises doivent aborder ces blocages de manière structurée et stratégique. Voici quelques approches pour maximiser la valeur de leurs équipes Data.
Mise en place d’une gouvernance des données
La gouvernance des données est essentielle pour assurer la qualité, la sécurité, et la disponibilité des données. Elle englobe des pratiques visant à gérer l’ensemble du cycle de vie des données : collecte, stockage, accès, et utilisation. La mise en place de standards de gouvernance permet d’établir des politiques d’accès aux données pour garantir que les équipes disposent des informations dont elles ont besoin tout en respectant les normes de conformité. Une gouvernance efficace inclut également la création de rôles dédiés, tels que les responsables de la qualité des données et les architectes de données, pour surveiller la cohérence et la sécurité de l’information.
Développement d’une culture Data-driven
Pour qu’une stratégie Data soit pleinement intégrée dans l’entreprise, il est crucial d’instaurer une culture data-driven, dans laquelle les décisions sont orientées par des insights fondés sur des données plutôt que par des intuitions. Cela passe par des actions de sensibilisation et de formation auprès des équipes métiers, pour leur démontrer la valeur ajoutée de l’analyse de données. La culture Data-driven doit être impulsée par la direction et se traduire par des objectifs communs alignés avec les analyses de données. Cela implique également d’encourager la collaboration entre les équipes Data et les autres départements pour assurer l’adhésion et la compréhension des résultats des projets data.
Investir dans une Data Platform
Une infrastructure adaptée, souvent appelée « Data platform », est essentielle pour exploiter pleinement la puissance des analyses de données et du machine learning. Une Data platform moderne inclut le stockage de données dans le Cloud, des systèmes de calcul distribués, et des plateformes de traitement de données en temps réel. En investissant dans une telle plateforme, les équipes data peuvent travailler avec des outils de pointe, gérer de grandes quantités de données de manière efficace, et déployer des modèles en production sans obstacles techniques. La Data platform doit également faciliter une intégration fluide des données, grâce à des outils d’ETL et des pipelines automatisés, pour que les équipes puissent accéder rapidement à des informations fiables et actualisées.





