

Cas d’usage – extraction du data lineage Prérequis : Databricks runtime 17.0 (June 2025 – Link), Databricks Unity catalog, accès...
27 février 2024
Databricks Bundle : gestion des déploiements des jobs Databricks via CI/CD

Avec l’intensité des sujets Data dans la majeure partie des entreprises, Databricks est de plus en plus présent chez les clients de Cellenza. Cependant, la plupart d’entre eux peinent à gérer efficacement leurs jobs dans leurs divers environnements (développement, staging, production…). Dans cet article, nous allons parler des Databricks Asset Bundles (que nous appellerons Bundle), une solution en Public Preview de Databricks (lors de l’écriture de cet article) qui permet la gestion des déploiements des jobs.
Job Databricks
Pour faire de la transformation de données dans Databricks, il existe deux types de clusters : les clusters interactifs (all-purpose cluster) et les clusters jobs.
Les clusters interactifs sont nécessaires pour exécuter les notebooks de manière interactive, et pour analyser les données de manière collaborative. Ces clusters sont utilisés lors de phases de développement. Une fois que le développement est « fini », il est préférable de créer un job Databricks qui utilise des cluster jobs qui sont optimisés pour lancer des workflows automatisés et robustes de manière rapide. Il est aussi important de savoir que les clusters interactifs sont plus chers que les clusters jobs sur une configuration similaire.
La création d’un job Databricks se fait via l’espace « workflows » de Databricks. Lors de la création d’un job, cette interface s’affiche :

Il vous suffit alors de configurer votre job de la façon dont vous le souhaitez. Bien souvent, cela comprend le lancement de différents notebooks dans l’ordre que vous définissez ; vous pouvez avoir des notebooks qui se lancent en parallèle :
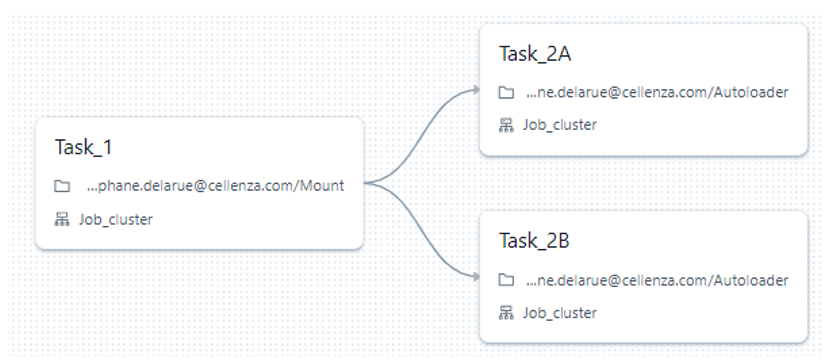
Il est aussi possible de lancer une tâche lors de l’échec d’une autre, de mettre en place une politique de « retry », l’envoi de mail automatique lorsque le job échoue ou dure trop longtemps, ou encore d’envoyer des notifications dans un canal Teams.
Une fois que vos tâches sont configurées, vous pouvez également configurer le cluster qui va lancer chaque tâche (un cluster différent peut être configuré pour chaque tâche, ou garder le même cluster pour toutes les tâches). Il est aussi possible d’ajouter un trigger pour lancer le job tous les jours, toutes les heures…
La question qui va nous intéresser ici, c’est de savoir comment répliquer le job dans les autres environnements. C’est ici que le Bundle va entrer en jeu.
Installation et configuration de databricks-cli
Les Bundle font partie de « databricks-cli » à partir de la version 0.205 et supérieur, il est donc nécessaire que celui-ci soit installé. Pour cela, je vous invite à consulter la documentation Databricks.
Une fois l’outil installé, il est nécessaire de le configurer pour vous connecter à votre workspace de développement. Le plus simple est d’utiliser un Personal Access Token (PAT). Par défaut, lors de la création d’un workspace, l’utilisation des PAT est désactivée : pour l’activer, cliquez sur votre nom d’utilisateur en haut à droite de votre workspace Databricks, puis « Admin Settings », puis dans la catégorie « Workspace admin » sélectionnez l’option « Advanced », et activez les « Personal Access Tokens » :
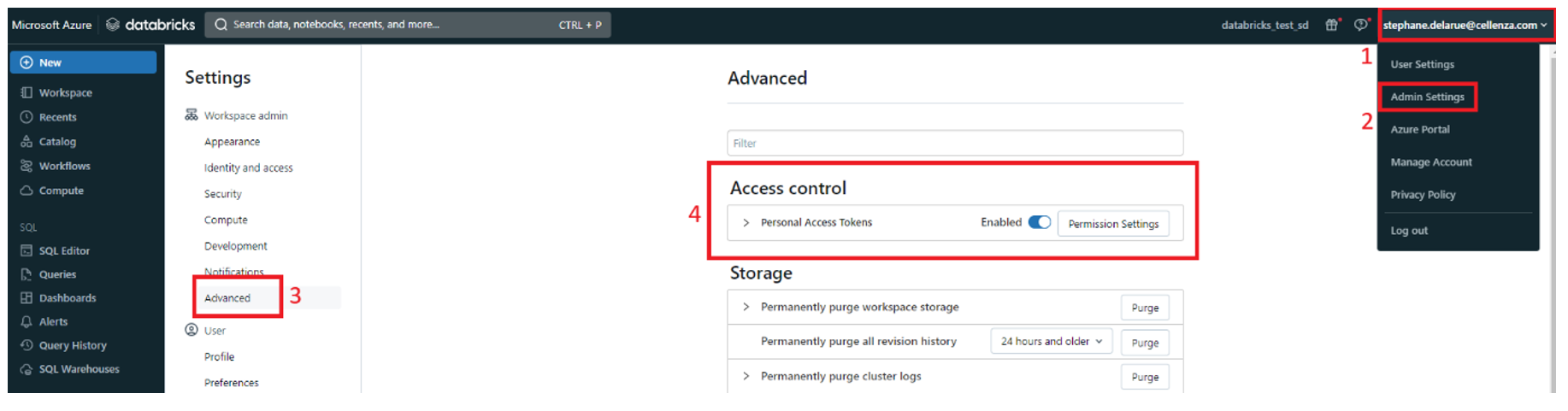
Si votre entreprise empêche la création de token, il existe d’autres méthodes pour se connecter via databricks-cli (le plus commun reste via PAT ou via service principal (M2M)) :
https://docs.databricks.com/en/dev-tools/cli/authentication.html
Pour créer votre PAT, dans la catégorie « User », cliquez sur « Developer » puis « Manage » sur les « Access tokens » :
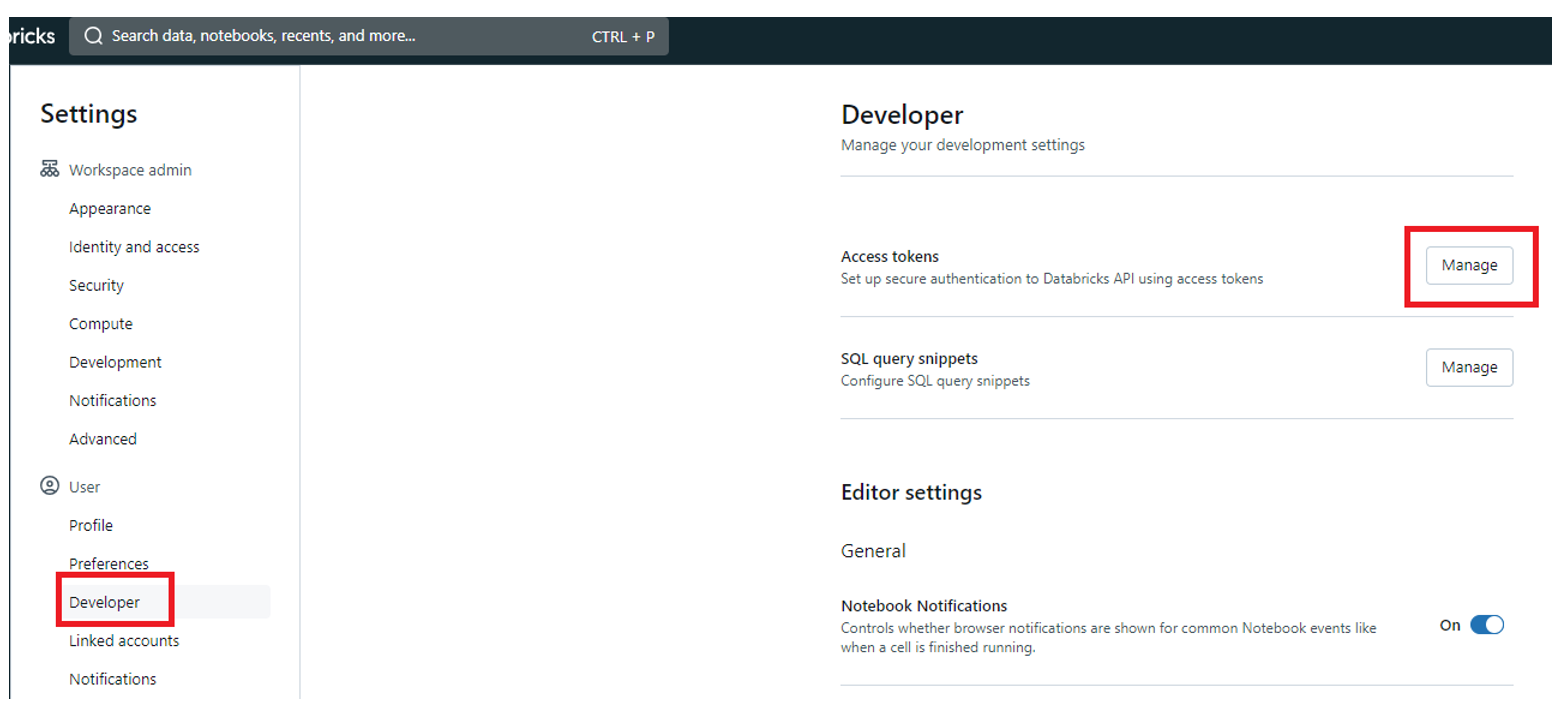
Ici, vous pouvez générer un nouveau token et ajouter un commentaire pour vous rappeler où ce token est utilisé. Personnellement, je mets « databricks-cli ». Pour le Lifetime, vous pouvez le laisser à 90 jours (par défaut) ou bien laisser le champ vide pour qu’il n’expire jamais (en fonction des contraintes de sécurité de votre entreprise) : un token sera alors généré.
⚠️ ATTENTION : sauvegardez bien ce token, vous ne pourrez plus jamais le revoir !
Une fois que vous avez votre token, il suffit de lancer la commande « databricks configure ». On vous demandera l’url de votre workspace Databricks puis votre token :

NOTE : suite à cette commande, un fichier « .databrickscfg » est créé à la racine de votre répertoire utilisateur. Si vous l’ouvrez, vous y verrez que le PAT y est stocké en clair, faites donc très attention à ce fichier et ne le transmettez à personne.
Maintenant que databricks-cli est configuré, nous pouvons mettre en place le Bundle.
Initialisation du Bundle
La mise en place du Bundle va demander une manipulation de fichier YAML. Je vous conseille fortement de faire cela sur votre IDE, et vous recommande VS Code avec l’extension YAML.
Cloner en local votre repo GIT où vous avez stocké vos notebooks Databricks, puis créez le fichier « databricks.yml ». Ce fichier est la base de votre Bundle, il doit forcément avoir ce nom. Pour faciliter l’écriture des Bundle, Databricks met à disposition un schéma qui permet de vérifier la structure du YAML que vous écrivez. Pour récupérer ce schéma, taper la ligne de commande suivante : « databricks bundle schema > bundle_config_schema.json ».
Cette commande va vous créer un fichier json à la racine du répertoire. Dans le fichier « databricks.yml », ajoutez cette ligne :
# yaml-language-server: $schema=bundle_config_schema.json
NOTE : vous devez ajouter cette ligne aux autres fichiers YAML que nous allons créer dans la suite de cet article.
Si vous êtes sur VS Code avec l’extension YAML, cela aura pour effet de vérifier si le YAML est conforme au schéma et vous enverra des erreurs si ce n’est pas le cas.
Le Bundle se compose de quatre parties :
- La base: qui permet de configurer le nom du Bundle
- Les ressources : qui permettent de définir les jobs
- Les variables: pour paramétrer votre Bundle selon vos environnements
- Les targets: pour définir les différents environnements dans lesquels vous voulez déployer vos jobs.
Il est possible de mettre ces quatre parties dans le même fichier. La bonne pratique est de séparer ces quatre parties en quatre fichiers distincts pour des facilités de maintenance du code.
Étape 1 : La base du Bundle
Le fichier de base du Bundle est le fichier que nous avons déjà créé « databricks.yml » : c’est dans ce fichier que l’on va paramétrer le nom unique pour notre Bundle, ainsi que l’emplacement des autres fichiers de notre Bundle.
Pour paramétrer le nom de notre Bundle, voilà les deux lignes à ajouter :
bundle: name: [nom_bundle]
ATTENTION : pour ceux qui ne sont pas habitués à YAML, c’est un codage qui se base sur l’indentation de votre fichier. Veillez donc à faire très attention à ce point.
Toujours pour des facilités de maintenance du code, je vais stocker l’ensemble des fichiers spécifiques au Bundle dans un dossier à part. J’ai donc créé un dossier « bundle_file » où j’ai l’intention de stocker les trois autres fichiers de notre Bundle. Pour que ceux-ci soient pris en compte, je dois ajouter deux lignes en plus dans mon fichier de base :
include: - bundle_file/*.yml
Cela aura pour effet d’inclure tous les fichiers d’extension « .yml » qui sont dans le répertoire « bundle_file » dans la configuration de mon Bundle. Il est bien sûr possible d’inclure d’autres fichiers ou de les préciser avec leur nom complet.
Étape 2 : Les ressources du Bundle
Le fichier ressource va permettre d’avoir la définition du job Databricks que vous voulez déployer. Le plus simple est de récupérer la définition directement sur le job que vous avez créé dans le Workspace Databricks. Pour ce faire, il suffit de cliquer sur les « … » en haut à droite quand vous êtes sur le job en question, puis de cliquer sur « View YAML/JSON » :
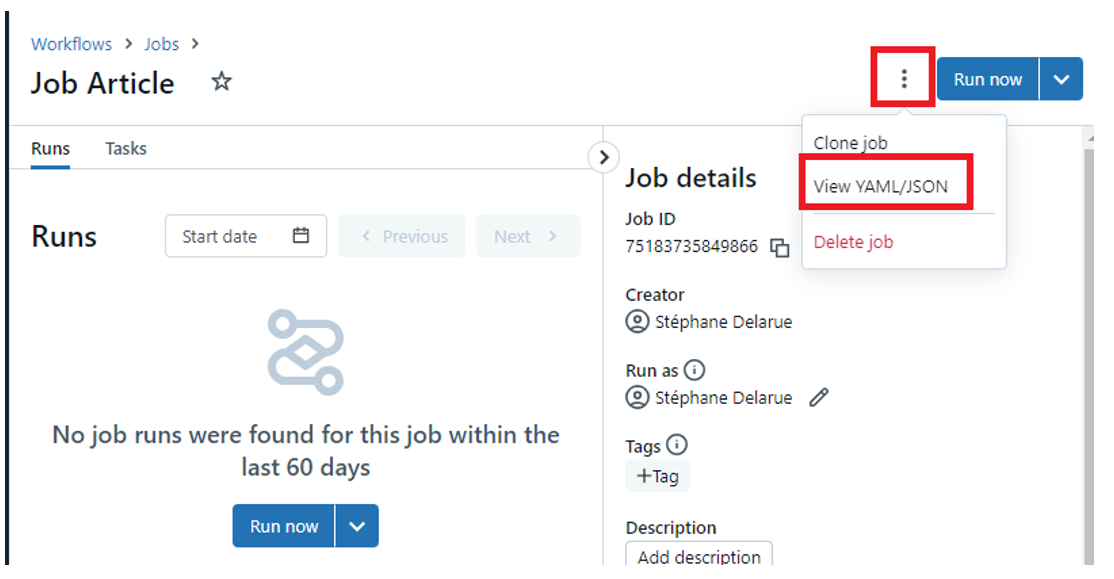
La définition YAML du job va alors s’afficher :
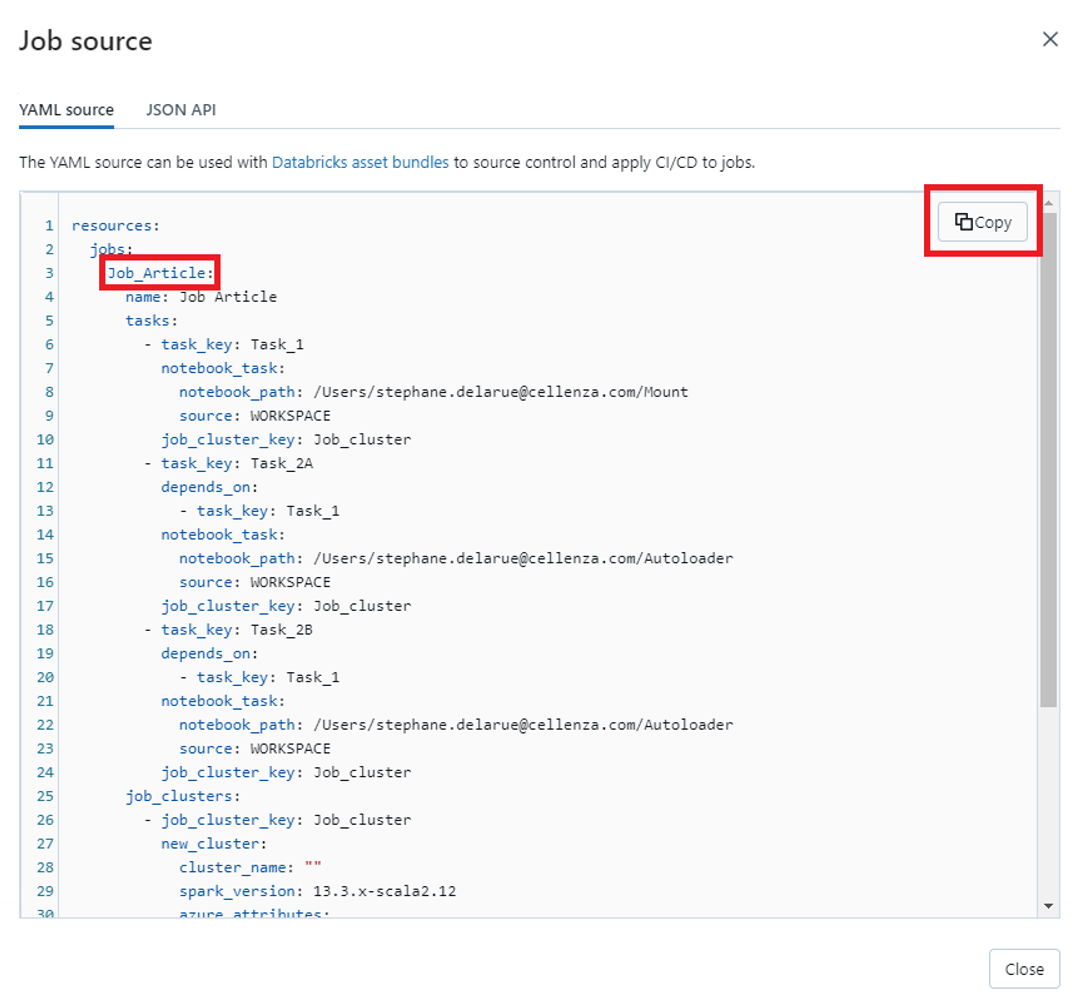
Le « Job_Article » encadré en rouge ci-dessus correspond au nom du Bundle. Vous devez le modifier pour qu’il corresponde au nom que vous avez configuré dans votre fichier « databricks.yml ».
Dans cet exemple, « Job_Article » va être renommé « article_bundle ». Ci-dessous, le nom « article_bundle » doit donc être le même dans le fichier « databricks.yml » et le fichier « bundle.resource.yml » :
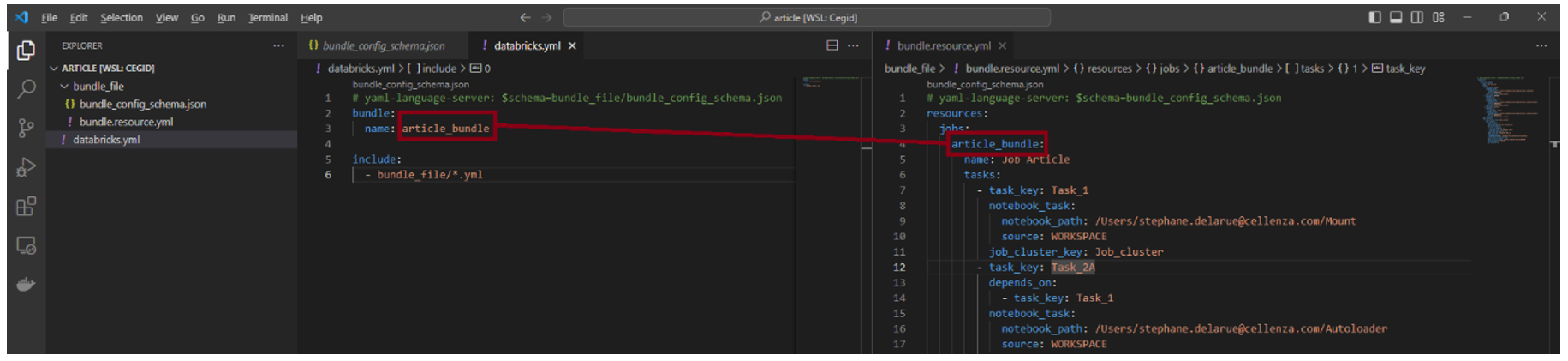
NOTE : n’oubliez pas d’ajouter la ligne de spécification du schéma dans l’en-tête de votre fichier pour vérifier sa conformité.
Étape 3 : Les variables
Chaque environnement étant différent, il est quasi sûr que vous serez amené à utiliser les variables pour paramétrer vos jobs pour les adapter à chaque environnement. L’exemple le plus simple étant la source de vos données qui est forcément différente pour chacun de votre environnement. Dans cette partie, nous allons voir comment ajouter une variable à un notebook, récupérer sa valeur dans le notebook, le paramétriser dans le job, et l’ajouter dans notre Bundle.
Pour ajouter une variable à un notebook, il faut faire appel au widget via cette commande :
dbutils.widgets.text("source", "")
Si vous lancez cette commande, cela va créer des zones de saisie de texte en haut de votre notebook, qui vous permettront de configurer la valeur de votre paramètre. Pour récupérer la valeur dans votre notebook, il suffit d’appeler la méthode « get » des widgets :
dbutils.widgets.get("source")
Ainsi dans un notebook, voilà ce que ça donne :

L’utilisation d’un paramètre dans un notebook se fait ainsi facilement. Regardons à présent comment nous pouvons configurer ce paramètre dans notre job Databricks. Pour ce faire, allez sur votre job Databricks, puis cliquez sur la tâche qui exécute le notebook dans lequel vous avez ajouté votre paramètre. Il vous suffit alors de cliquer sur « + Add » au niveau des « Parameters » :
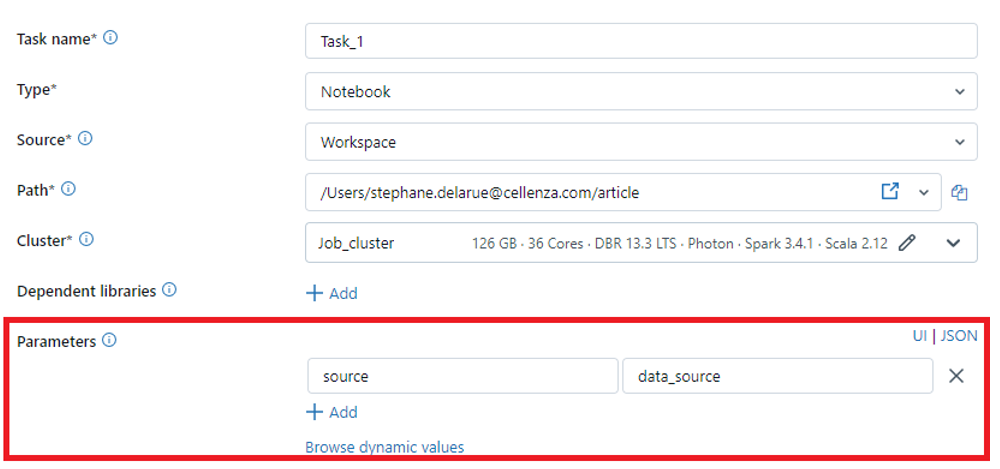
Vous pouvez alors mettre à jour votre fichier des ressources Bundle avec la nouvelle définition avec le paramètre.
Il nous reste maintenant à variabiliser la valeur de ce paramètre pour pouvoir donner une valeur différente en fonction de l’environnement dans lequel on va déployer le job. Pour cela, créons tout d’abord le fichier pour les variables du Bundle. Dans notre exemple, le fichier est nommé « bundle.variable.yml ». Puis ajoutons l’en-tête avec la définition du schéma dans ce fichier.
Ensuite, ajoutons une variable « source » :
Dans le cas de plusieurs variables, il suffit d’en créer une autre au même niveau d’indentation que « source ». Le champ « description » est obligatoire, et doit être renseigné pour que le YAML soit valide.
Il est également possible d’ajouter une valeur par défaut de la variable avec la propriété « default » qui est optionnelle.
Il reste maintenant à configurer la valeur de cette variable en fonction de l’environnement dans lequel on déploie le job. Pour cela, il faut mettre en place le dernier fichier : les targets !
Étape 4 : Les targets du Bundle
Le fichier des targets d’un Bundle permet de définir les différents environnements dans lesquels on peut déployer le job. Comme pour les autres fichiers, créons ce fichier avec le schéma en en-tête. Ici, nous souhaitons déployer dans trois environnements (DEV, QUAL, PROD) le paramètre « source » avec des valeurs différentes pour notre paramètre :
Avec ce dernier fichier, nous avons la configuration minimale requise pour avoir un Bundle complet.
Pour vérifier, vous pouvez lancer cette commande dans votre terminal « databricks bundle validate -t DEV » : cela aura pour effet de valider votre Bundle pour le target « DEV ». S’il n’y a pas d’erreur, un JSON s’affichera en retour de la commande et un nouveau dossier « .databricks » sera créé :
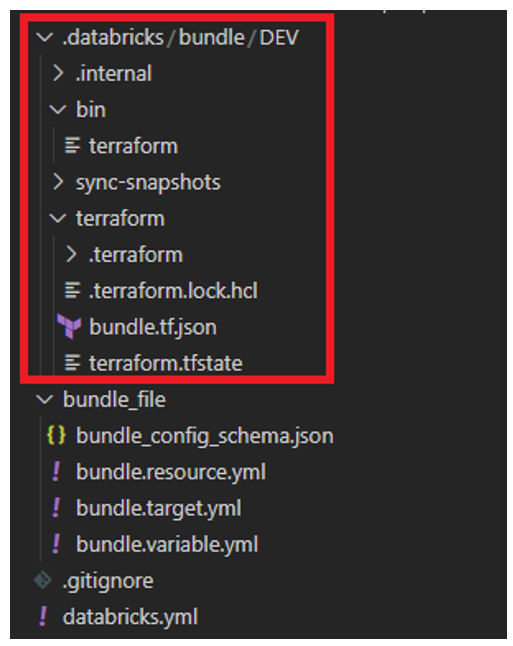
Pour déployer le job, il faut lancer cette commande « databricks bundle deploy -t DEV » et le job sera déployé dans le workspace que vous avez configuré précédemment dans le databricks-cli.
À NOTER : il est possible d’avoir plusieurs « profils » dans databricks-cli qui vous permet de sélectionner facilement dans quel workspace vous voulez déployer votre job (https://docs.databricks.com/en/dev-tools/cli/profiles.html).
CI/CD
Maintenant que le Bundle est configuré, il reste à configurer une CI/CD pour déployer les jobs dans Azure DevOps.
La CI/CD avec le Bundle se décompose en deux étapes :
- L’installation de databricks-cli
- Le déploiement du Bundle.
L’installation de databricks-cli peut se faire en une ligne de script :
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | sh)"
Cela aura pour but de télécharger la version la plus à jour du repo de Databricks et de l’installer sur l’agent.
La seconde partie consiste à lancer le « databricks bundle deploy ». Pour cela, il est nécessaire de configurer le databricks-cli pour qu’il se connecte au workspace Databricks souhaité. Pour cela, il est possible d’envoyer des variables d’environnement.
Pour stocker les informations de connexion, nous allons créer un groupe de variable dans Azure DevOps, dans lequel on stockera les informations de connexion à Databricks :
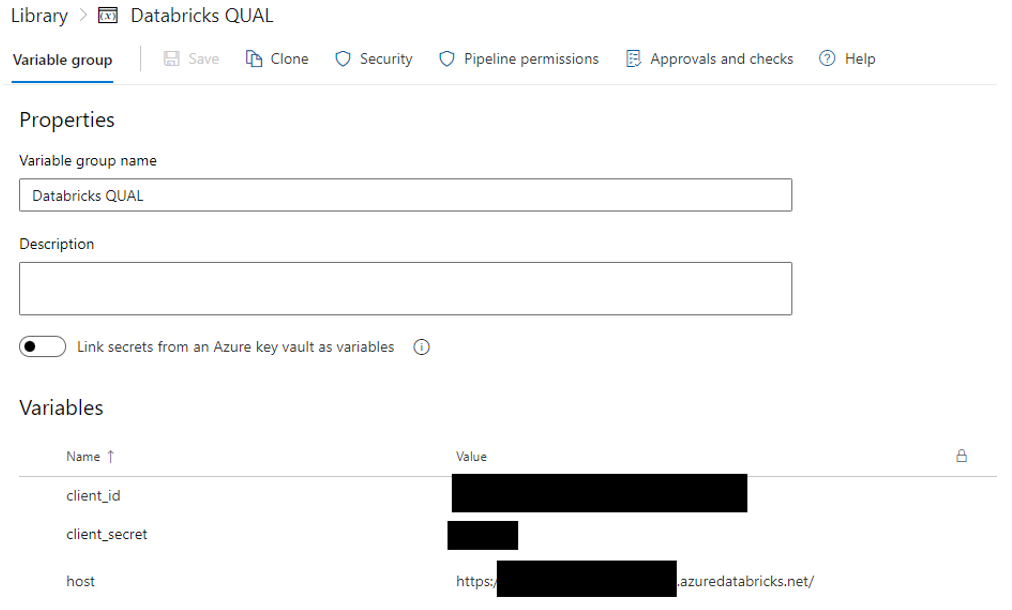
Ici, pour le déploiement dans notre environnement de qualification, nous passons par un service principal directement avec son client_id/client_secret. Il est possible de passer par un PAT Token également en fonction de votre besoin.
Dans ce cas, voilà le yaml qui permet de faire le déploiement du Bundle :
Si vous utilisez un PAT Token, à la place de ARM_TENANT_ID, ARM_CLIENT_ID et ARM_CLIENT_SECRET, utilisez « DATABRICKS_TOKEN ». Ces paramètres sont pour Azure. Ils seront différents pour AWS et GCP.
Deep Dive du Bundle
Maintenant que le Bundle est fonctionnel et que la CI/CD est paramétrée, voici un deep dive sur les différentes fonctionnalités présentes dans le Bundle qui pourraient vous intéresser :
- Terraform
- Mode du Bundle
- Python wheel
- Définir une variable
Terraform
Pour les plus curieux d’entre vous, si vous avez jeté un œil à ce qui se trouve dans le répertoire « .databricks » après votre « validate », vous avez dû voir un répertoire et un fichier binaire « terraform ».
En effet, en interne, les Bundle Databricks utilisent Terraform pour le déploiement des Jobs. Pour ceux qui ont l’habitude d’utiliser Terraform, une question doit vous brûler les lèvres : où est le tfstate ?
Pour les néophytes, Terraform est un outil d’Infrastructure as Code (IaC) : pour son bon fonctionnement, il a besoin d’un fichier d’état, le tfstate (https://developer.hashicorp.com/terraform/language/state/purpose?ref=blog.ippon.fr).
Ce fichier est très important : c’est lui qui stocke toutes les informations de votre job et qui permet, une fois déployé, de le mettre à jour (en gardant en mémoire l’ID du job dans le workspace Databricks). Par défaut, ce fichier est stocké dans le répertoire du compte qui a déployé le Bundle :

Il est possible de modifier l’emplacement de sauvegarde de ces fichiers. Pour cela, il faut faire appel à la propriété « root_path » du workspace du target, comme dans l’exemple suivant :
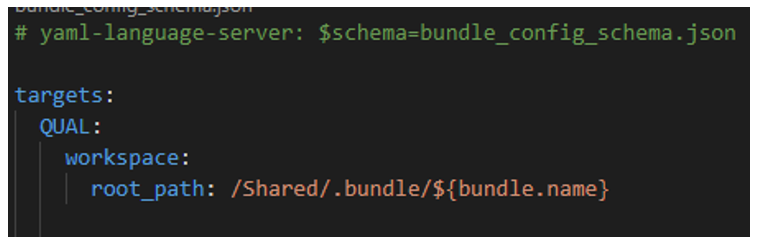
NOTE : lors de l’utilisation du « mode » development (cf. ci-dessous) du Bundle, le « root_path » doit forcément être dans le répertoire de l’utilisateur.
Mode du Bundle
Pour chaque target du Bundle, il est possible de spécifier un « mode ».
Il existe deux modes :
- « development »
- « production »

Le mode « development » permet de :
- Activer le mode debug pour DLT
- Ajouter un préfixe [dev ${workspace.current_user.userName}] sur l’ensemble des ressources déployées
- Spécifier un cluster-id lors du déploiement
- Mettre en pause l’ensemble des schedules et triggers
- Activer le lancement concurrent pour les jobs déployés
Le mode « production » permet de :
- Valider que tous les pipelines DLT ne sont pas marqués en cours de développement
- Valider que la branche courante de Git correspond à celle indiquée dans le target
- Si vous n’utilisez pas de service principal pour le déploiement :
- Vérifier que les path ne sont pas override vers un utilisateur spécifique
- Vérifier que les permissions et le « run_as » sont spécifiés
Python wheel
Lors de déploiement de job faisant référence à une wheel Python, la commande « databricks bundle deploy » va automatiquement créer votre wheel si celle-ci est gérée via « Poetry » ou « setuptools ».
Pour cela, il vous suffit de faire référence à votre wheel dans les resources du Bundle :

Définir une variable
Il existe trois méthodes pour définir la valeur d’une variable, classées par ordre de priorité :
- Passage de la valeur via une variable d’environnement « BUNDLE_VAR_[nom_variable] » lors de l’appel à « databricks bundle deploy »
- Spécification de la valeur dans la partie « target » -> « variables », c’est ce que nous avons fait dans cet article
- Spécification de la propriété « default » lors de la déclaration de la variable.
L’ordre de priorité permet d’écraser une valeur par une autre en fonction d’où elle a été définie. Ainsi, la valeur par défaut sera écrasée par la valeur dans le target, qui sera écrasé par la valeur de la variable d’environnement.
Traçabilité du job
Lors de l’utilisation des Bundle Databricks, vous allez probablement être amené à vous poser les questions suivantes :
- Depuis quand le job en production n’a pas été mis à jour ?
- Est-ce que le fix que j’ai poussé cette semaine est en production ?
- Quelle version est actuellement en production ?
Pour y répondre facilement, je vous conseille d’ajouter un tag à votre Job, dans les ressources de votre Bundle :
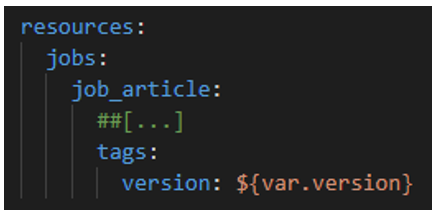
Pour cette variable « version », ajoutez la valeur par défaut « ${workspace.current_user.userName} ». Ainsi, si quelqu’un déploie le job localement, vous aurez le nom de la personne dans le tag du job :
Ensuite, modifiez votre pipeline CI/CD, et lors du lancement du script du « databricks bundle deploy » ajoutez cette variable d’environnement :
![]()
Cela permettra de mettre le BuildNumber de votre pipeline DevOps. Il faut savoir que ce numéro est unique et correspond à la date du jour où le pipeline a été lancé, suivie d’un nombre qui correspond au nombre de fois que le pipeline a été lancé ce jour.
Ainsi vous aurez un tag dans votre job qui vous indique le pipeline qui l’a déployé, lequel vous permet d’avoir le commit Git associé. Ainsi la traçabilité de votre Job est complètement gérée.
Pour aller plus loin
Dans cet article, nous avons vu comment utiliser les Databricks assets Bundle pour déployer vos différents jobs Databricks, et comment construire une CI/CD s’appuyant sur cette technologie.
Pour approfondir le sujet, je vous invite vers maintenant à lire notre précédent article qui explique comment construire proprement une CI/CD pour un projet Databricks qu’il vous suffira d’adapter pour incorporer les Bundle.





