

Tous les ans, Les Echos et l’institut de statistiques Statista publient les résultats d’une enquête sur les entreprises à forte...
24 juin 2014
Retour sur NCrafts / Event Sourcing et données polyglottes

Ce billet de blog fait partie de la série consacrée à la conférence NCrafts qui s’est tenue à Paris le 16 Mai 2014.
La dernière session à laquelle j’ai assisté (celle de clôture), animée par Greg Young (@gregyoung), traitait des « problématiques de stockage de données.
Greg Young
 Greg Young est un consultant indépendant et entrepreneur en série. Il a 15 ans d’expériences variées en informatique de systèmes d’exploitation embarqués pour les systèmes d’entreprise. Il est un collaborateur régulier de InfoQ, conférencier et formateur à Skills Matter et également un conférencier bien connu des évènements internationaux.
Greg Young est un consultant indépendant et entrepreneur en série. Il a 15 ans d’expériences variées en informatique de systèmes d’exploitation embarqués pour les systèmes d’entreprise. Il est un collaborateur régulier de InfoQ, conférencier et formateur à Skills Matter et également un conférencier bien connu des évènements internationaux.
Il est l’inventeur du terme « CQRS » (requête de commande responsabilité ségrégation), repris depuis par la communauté. Greg est un consultant indépendant et entrepreneur en série. Il intervient aussi sur CQRS, DDD et d’autres sujets d’actualité sur codebetter.com.
Un de ses sujets de prédilection est l’Event Sourcing. Il s’agit d’un pattern de gestion du stockage de données.
La problématique
L’approche typique lorsqu’il s’agit de stocker des données est de maintenir l’état actuel des données en les mettant à jour, mais cette approche a quelques limites.
Tout d’abord une grande partie de l’historique est perdue. Et il est impossible de savoir à l’avance si ces données perdues auraient été utilisées plus tard ou non. C’est d’ailleurs la raison pour laquelle la journalisation (logs) existe.


Ci-dessus, il explique qu’avec le second modèle (basé sur la structure des données), on perd a priori l’information de l’élément supprimé, qui est pourtant visible dans le premier modèle (basé sur l’historique des évènements).
Deuxièmement, si on ne travaille qu’avec un seul mode de stockage, on se retrouve avec un modèle de données qui ne sera probablement pas optimisé pour toutes les situations.
Par exemple, pour un même ensemble de données on peut avoir besoin d’y accéder dans 2 contextes différents : un premier dans lequel une base de données de type graphe serait plus appropriée, un autre dans lequel le stockage en SQL ou en NoSQL de type document serait plus logique.
Dans quel cas une base de données Graphe serait plus appropriée qu’une base SQL ?
Une base de données de type graphe est une base dans laquelle le concept de table n’existe pas. Les données sont stockées dans une structure de type graphe. Chaque donnée correspond à un noeud et est liée aux autres données (noeuds) par des relations. Les noeuds et les relations peuvent avoir des attributs.
Physiquement chacun des noeuds possède un pointeur vers les noeuds auxquels il est associé. Même quand le nombre de noeuds augmente le coût de l’équivalent d’une jointure ne change pas.
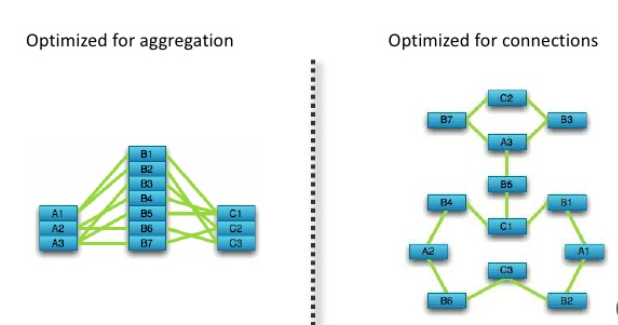
Une base de données relationnelle (au moins 3FN) est optimisée pour l’agrégation des données alors qu’une base de données graph est optimisée pour les relations entre ces données.
Les contextes d’accès à une base
Le contexte fonctionnel pour lequel on a besoin d’accéder à une base doit donc influer la nature de la base qu’on choisit.
En plus du contexte fonctionnel, il faut aussi tenir compte du fait que, dans une base de données, nous faisons beaucoup plus d’accès en lecture que d’accès en écriture. Ce qui est souvent le plus urgent à optimiser c’est la lecture. Et il ne faut pas exclure l’idée d’avoir une base de données dans laquelle on écrit et une autre dans laquelle on lit.
Greg Young évoque un troisième moyen de dissocier les contextes d’accès à une base (en plus du contexte fonctionnel et du contexte lecture/écriture). Qui est celui de l’âge de la donnée utilisée. Selon lui, une donnée n’est pas forcément lue/écrite de la même manière ou au même endroit, selon qu’elle soit récente ou très ancienne.
Il explique bien que chaque type de base doit être utilisé à bon escient, et qu’aucune base de données n’est parfaite (et cela vaut aussi pour les bases de données de type graphe…).

Un site comme Facebook par exemple, utilise une base de données de type graphe (développée par eux même). Mais il ne s’agit évidemment pas de la seule base qu’ils utilisent.
Le pattern d’Event Sourcing et une solution qui répond aux 2 problèmes évoqués précédemment (la perte d’information et l’optimisation du stockage par contexte d’utilisation).
L’Event Sourcing
Au lieu de stocker des objets qui sont mis à jours, on stocke les actions dans une base d’évènements. Ainsi on n’a aucune perte d’information. Et tout autre mode de stockage, dérive de cette basse d’évènement.
Les données de cet event store ne sont jamais modifiées et la seule opération effectuée dessus est l’ajout de lignes. De plus il y a plus de chance que notre modèle de données change (ajout de nouvelles relations, nouveaux type de données, nouveaux attributs, suppression d’attributs…), plutôt que notre modèle d’évènement.

La lecture de données se fait sur d’autres sources de données, qui sont, elles, “clientes” de l’Event Store. Ce qui nous permettrait de mettre un modèle spécifique et optimisé à chaque cas d’utilisation (c’est ce qu’il appelle les données polyglottes).
Le contenu de chacune des sources de données clientes est généré à partir de la liste des évènements. Et les accès en lecture se font sur les sources de données clientes.
La seule chose que ces bases clientes doivent implémenter c’est la possibilité de récupérer tous les évènements sur une plage de temps donnée. A partir de là, il est possible de convertir tous ces évènement en des données en données structurées dans la base cliente.

Cette nouvelle approche concernant le stockage des données m’a convaincu (d’autant plus que Mr Greg Young est un excellent speaker). Néanmoins, j’émettrais une réserve concernant le travail à faire pour chacune des bases clients afin de traduire les données provenant de la base d’évènements.





