

Dans la continuité des articles précédents sur la Kubernetes Gateway API, nous explorons aujourd’hui un aspect plus opérationnel de ce...
13 juin 2023
AKS et les conteneurs Sandbox

Dans ce nouvel article, nous allons parler des sandbox containers (ou conteneurs bac à sable, en version française), dans le contexte Azure Kubernetes Service (AKS).
Nous commencerons par présenter les concepts derrière les conteneurs de bac à sable, et pourquoi ils peuvent être nécessaires. Nous examinerons ensuite les solutions disponibles dans Kubernetes. Enfin, nous regarderons comment les technologies de conteneurs sandbox sont déployées et utilisées dans un cluster AKS.
Container sandboxing 101
Avant de comprendre les principes derrière les conteneurs sandbox, prenons un peu de recul et examinons les bases de l’architecture de conteneur.
L’idée derrière le conteneur est d’avoir une couche d’abstraction légère entre l’application et son hôte. Dans le monde de la virtualisation, nous avons l’hôte, l’hyperviseur et la machine virtuelle, qui hébergent ensuite le binaire de l’application.
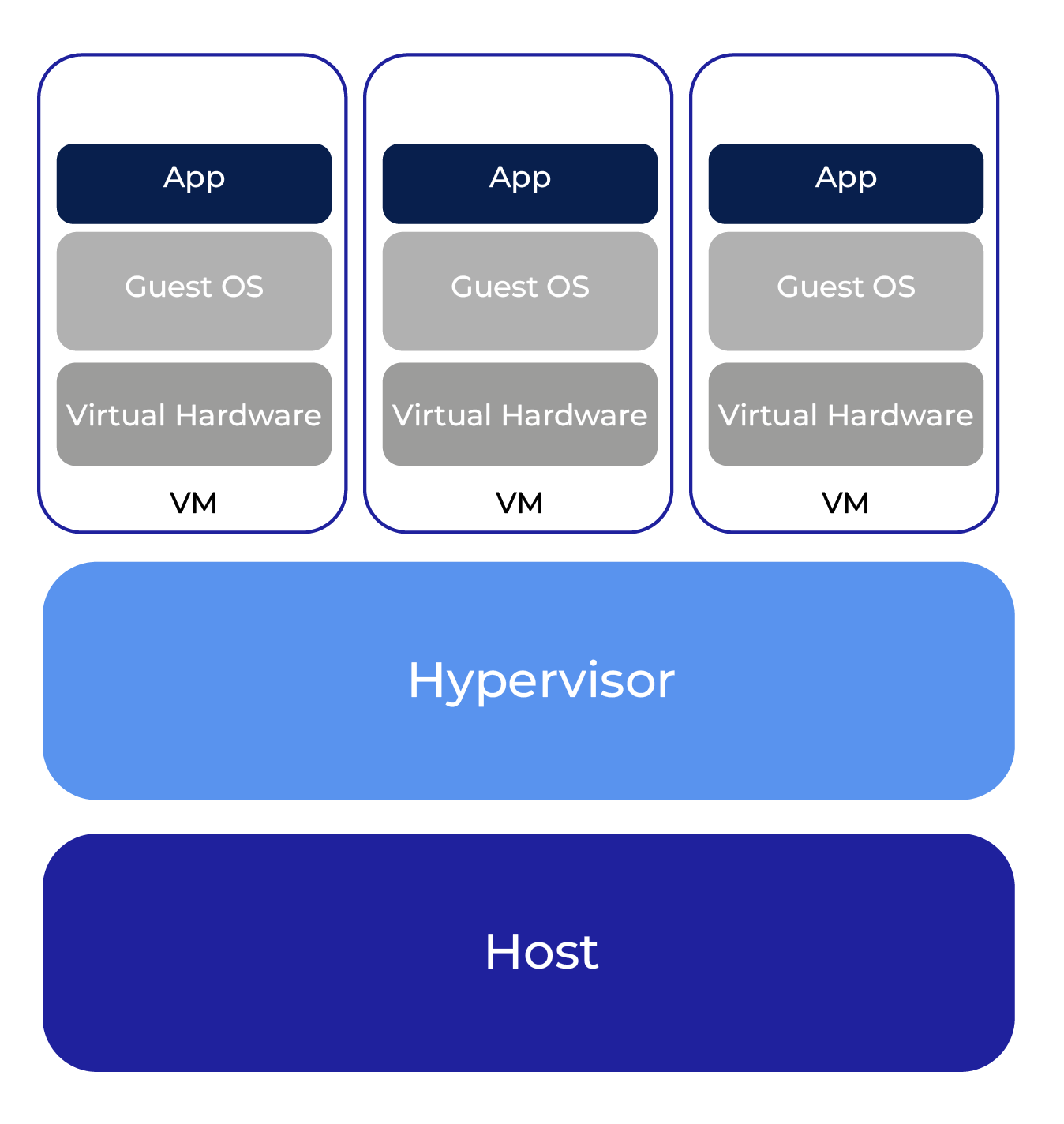
Dans le monde des conteneurs, l’hyperviseur disparait, et avec lui, la machine virtuelle, son hardware virtuel et son OS.

Le résultat ? La suppression de ces couches améliore drastiquement les performances.
En effet, le moteur de container seul, pour isoler les applications du noyau, est beaucoup léger que la stack de virtualisation complète. Cependant, parce qu’il y a beaucoup moins de couches, il y a aussi moins d’isolement. Le noyau est partagé, même s’il y a isolation au moyen de cgroups (control groups) et d’espace de noms.
De ce fait, pour les cas où un isolement supérieur est nécessaire, des solutions techniques ont été développées. Ces solutions sont généralement basées sur l’un des deux modèles suivants :
- Rule-based execution
- Machine-level Virtualization
L’approche Rule-based execution est utilisée en identifiant les syscall effectués par l’application, et en autorisant uniquement ceux qui sont requis depuis le conteneur vers le noyau de l’hôte partagé.
Parmi les solutions utilisant cette approche, on retrouve :
- seccomp ;
- SELinux ;
- AppArmor.
La virtualisation au niveau de la machine est probablement plus facile, car elle fournit une isolation via une machine virtuelle légère.

Toutefois, l’ajout de cette light-weight VM impact les performances du container sandbox, en raison de l’overhead de la virtualisation.
On notera, dans la catégorie machine-level virtualization, katacontainer, que nous regarderons plus en détail dans la suite.
Pour conclure avec les solutions de sandbox container, nous allons également mentionner gVisor.
gVisor agit comme un intermédiaire entre l’application et le noyau hôte. Il intercepte le syscall de l’application, et ne transmet que des appels limités au noyau hôte.

Voilà qui nous permet de conclure sur les différentes options pour les containers Sandbox. Dans la suite, nous laisserons de côté les solutions de type rule-based execution et nous intéresserons davantage sur gVisor et katacontainer, dans un contexte AKS.
Préparer les containers sandbox dans AKS
Maintenant que les bases sont posées, intéressons-nous à la mise en œuvre de containers sandbox dans AKS.
Que l’on considère gVisor ou katacontainer, nous devons installer des binaires sur les nodes Kubernetes. Évidemment, puisque que nous prenons un contexte Cloud managed Kubernetes, avec AKS, l’accès aux nodes est plus ou moins restreint.
En effet, les nodes pools sont gérés à travers des Azure Virtual Machine Scale Sets, gérés par le control plane AKS.
D’une part, se connecter directement à un node pour y installer un composant n’est pas supporté (comprendre par là qu’il s’agit d’une action réalisable, mais pouvant entrainer des effets de bord dans AKS, et qui n’est donc pas supportée, en cas d’incident, par Microsoft). D’autre part, par design, les instances d’un scale set sont potentiellement volatiles, et il n’est donc pas aisé de garantir la persistance d’un programme installé manuellement.
Toutefois, il y a un moyen, via un contrôleur Kubernetes, de garantir qu’un groupe de pods dispose d’une instance par node. C’est en effet le principe du daemon set qui permet de décrire une application de façon à ce qu’un pod soit toujours présent sur chacun des nodes du cluster.

Si l’on souhaite installer gVisor sur un cluster AKS, il est donc possible de s’appuyer sur daemon set qui installe les binaires sur chaque node.

Quelques prérequis sont nécessaires :
- Tout d’abord, pour installer un programme depuis uin container sur l’hôte, il est nécessaire d’utiliser un conteneur à privilège, afin de lui permettre un accès au stockage local des nodes.
- Ensuite, il faut modifier la configuration des nodes managés par AKS, plus spécifiquement la configuration de containerd. À noter : d’un point de vue Kubernetes, cette approche est tout à fait valide, donc a priori tout à fait valide sur AKS. Pourtant, cette action entraine une modification du fonctionnement par défaut du service AKS. On a donc ici un flou vis-à-vis du support Microsoft.
Un excellent article, écrit par Daniel Neumann sur son blog détaille la configuration de gVisor par cette approche. Nous regarderons cette approche dans la prochaine section.
Une autre façon de faire, cette fois-ci initiée par Microsoft, est l’usage de la technologie katacontainer. Les nodes basés sur la distribution Linux de Microsoft Mariner supportent en effet nativement cette solution de sandbox containers machine-level virtualization.
Dans ce cas, aucune installation sur les nodes n’est requise, puisque la solution est déjà installée, et nous permet de nous focaliser sur les aspects purement Kubernetes de création de sandbox containers.
Maintenant, si l’on regarde un peu plus l’architecture AKS, il est important de se rappeler que nous avons par défaut un node pool (appelé le default node pool, d’ailleurs). Jusqu’à récemment, il s’agissait forcément d’un node pool ubuntu, et il n’était donc pas possible d’utiliser katacontainer sur celui-ci.
Il semble que l’on dispose de plus de liberté aujourd’hui pour choisir l’OS Sku du default node pool, comme on peut le voir dans la documentation d’Azure Azure AKS :
Ou Terraform :

On remarquera d’ailleurs la différence entre la cli Azure avec la valeur AzureLinux, que l’on ne retrouve pas dans la documentation du provider azurerm, ni dans la documentation ARM/AzAPIProvider :

On notera également, du fait de son statut encore en preview, qu’il est requis d’activer la fonctionnalité sur le provider Microsoft.ContainerService :
az feature register --namespace "Microsoft.ContainerService" --name "KataVMIsolationPreview" |
Et pour finir, la nécessité de spécifier l’usage du workload runtime avec la valeur KataMshVmIsolation. Dans le cas contraire, le runtime n’est pas disponible.
À noter : le provider Terraform semble laisser penser qu’il est possible d’user du runtime kata puisque l’on peut choisir la valeur qui nous intéresse dès le default node pool. À valider donc !

Dans le cas de katacontainer, on peut créer un node pool compatible avec la commande suivante :
az aks nodepool add --cluster-name <AKS_Cluster_Name> --resource-group <AKS_Resource_Group> --name <Node_Pool_Name> --os-sku mariner --workload-runtime KataMshvVmIsolation --node-vm-size <VM_Size> |
Dans le cas de gVisor, on peut sélectionner le type de node pool que l’on souhaite, puisqu’il s’agit dans ce cas d’une customisation au niveau de l’hôte. Il n’y a donc pas de restriction à ce niveau.
Passons à présent aux derniers détails, plus centrés sur le plan Kubernetes
Utiliser des conteneurs Sandbox avec gVisor dans AKS
Dans le cas de gVisor, on commencera par regarder le statut de nos nodes. On notera l’usage de taints et de labels, qui seront un prérequis pour nous assurer du positionnement des pods utilisant des conteneurs sandbox :
Connaissant ces informations, nous pouvons définir notre daemonset pour gVisor :
La partie intéressante ici concerne le scheduling, avec la tolération qui coïncide avec notre node gVisor gvisor=true:NoSchedule. On utilise également nodeSelector avec agentpool: npgvisor, afin de nous assurer que les pods du daemonset s’exécuteront uniquement sur ce node pool. Concernant l’image du container, on s’est inspiré ici de l’article de blog de Daniel Neumann, comme évoqué plus en amont.
En quelques mots, l’installation de gVisor nous impose d’installer runc sur les nodes, et de modifier la configuration de containerd en conséquence. Vous trouverez plus de détails pour l’installation de gVisor dans la documentation de la solution.
Quand le daemonset est schédulé, voici ce que nous observons :
En regardant dans le portail, nous pouvons noter quel pod vit sur quel node :

Et nous pouvons donc définir tout d’abord une runtime class :
Enfin, un pod qui utilisera cette runtime class. On prêtera attention à l’usage des tolerations et NodeSelector dans le manifest du pod :
À titre de comparaison, créons un autre pod, avec la runtime class par defaut, c’est à dire sans gVisor :
En regardant la version de kernel des deux différents pods, on observe bien des versions différentes, ce qui valide l’isolation de kernel vis-à-vis de l’hôte :
Ce qui valide bien l’isolation du kernel dans les containers sandbox.,
Voilà qui conclut notre test sur gVisor. Comme nous avons pu le voir, la configuration n’est pas triviale, et nous n’avons pas détaillé la création de l’image du container utilisé pour installer gVisor.
Passons à présent à katacontainer.
Conteneurs sandbox dans AKS avec katacontainer
La configuration de containers sandbox avec katacontainer est beaucoup plus simple. Dans la mesure où nous avons déjà la technologie disponible sur les nodes Mariner, il nous suffit simplement de schéduler un pod avec la bonne runtime class. Regardons les classes disponibles :
La classe que nous allons utiliser est Kata-sh-vm-isolation :
Nous pouvons donc préparer un manifest de pod pour utiliser cette classe :
Si l’on compare la version de kernel de ce pod avec un autre pod utilisant la classe par défaut :
On observe bien la différence de kernel. D’ailleurs, si l’on utilise le sku ubuntu pour le default node pool, on obtiendra encore une autre version, par rapport à un node pool avec le sku Mariner.
Conteneurs Sandbox sur AKS : ce qu’il faut retenir
La bonne nouvelle, c’est l’arrivée des containers sandbox sur AKS, par l’intermédiaire des node pool Mariner. À noter : l’installation via daemonset reste possible mais conserve son flou vis-à-vis du support.
On notera aussi, comme l’indique la documentation Azure, qu’il y a un certain nombre de limites pour utiliser le sandbox container, notamment le support des CSI drivers.
Vous souhaitez en savoir plus sur le sujet ou être accompagné.e par un expert ? Contactez-nous !






