

Dans la continuité des articles précédents sur la Kubernetes Gateway API, nous explorons aujourd’hui un aspect plus opérationnel de ce...
12 janvier 2021
Event Hubs : déjouer les pièges de la consommation

Maintenant que vous maîtrisez l’émission des messages et le paramétrage de l’Event Hubs dans une optique d’amélioration de la performance, je vous propose d’en savoir plus sur la consommation des messages sur Event Hubs.
Expiration des messages sur Event Hubs
Une problématique importante dans les projets web est que les utilisateurs sont souvent très impatients. Si leur navigateur ou leur application mobile ne leur a pas donné de réponse dans les 15 à 20 secondes, ils vont très certainement faire un rafraîchissement de leur page et créer de facto une nouvelle demande. Pour ce qui est de la demande précédente, l’instance de page qui l’a effectuée n’existe plus et le résultat ne sera jamais affiché.
Pour éviter de traiter inutilement des messages et perdre du temps, la mise en place d’un système d’expiration est envisageable : une solution simple mais extrêmement efficace.
Néanmoins, il faut se souvenir qu’un système d’expiration n’est peut-être pas adapté à n’importe quel contexte projet.
Voyons maintenant d’autres moyens d’améliorer les performances.
Partition group : ingestion des messages
Dans notre précédent article, nous avons vu les partition groups côté Event Hubs. Je vous propose maintenant d’étudier son pendant : l’implémentation qui va réaliser le traitement des messages.
L’Event Hubs s’arrête à la gestion des messages. L’ingestion et le traitement de chacun de ces messages doivent ensuite être réalisés spécifiquement pour votre projet en implémentant une méthode d’ingestion.
Cette méthode d’ingestion sera instanciée automatiquement pour chaque partition group de votre instance d’Event Hubs par l’Event Processor Host lorsque des messages devront être traités. Il n’y aura jamais plus d’instances que de partitions.
Par exemple :
- 2 partitions – 2 instances d’ingestion.
- 32 partitions – 32 instances d’ingestion.
Vu leur nombre assez faible, ces instances devront être suffisamment performantes pour traiter les messages le plus vite possible. En effet, si, par exemple, 1000 messages sont envoyés par seconde et qu’il y a 32 partitions, chaque instance devra donc traiter 31,5 messages par seconde.
Event Processor Host et paramétrage de l’ingestion
Présentation de L’Event Processor Host
Si vous utilisez des Azure Functions, cette partie étant automatique, une petite explication est nécessaire.
L’Event Processor Host est l’agent qui va instancier votre code source en X instances : une instance d’ingestion pour chaque partition.
L’Event Processor Host va aussi gérer les erreurs en relançant les messages dont l’instance n’a pas acquitté la fin de traitement normale.
Il va également gérer le dépilement, la lecture des messages, leur transfert à chacune de vos instance d’ingestion et surtout la gestion du checkpoint (le marque-page des messages).

Chaque instance d’injection va traiter un certain nombre de messages à la fois mais le traitement de ces messages doit être entièrement terminé pour pouvoir lancer une nouvelle instance, et donc le traitement du paquet de messages suivants. L’Event Processor Host va se baser sur la configuration définie dans votre fichier host.Json pour savoir combien de messages votre méthode peut ingérer à la fois (voir la section ci-après). Il faut configurer avec justesse le host.json pour limiter au maximum la latence.
Paramétrage de l’Event Processor Host :
1. Sous Visual studio ou VsCode, le fichier Host.json se trouve à la racine du projet. Il n’est pas modifiable autrement et sera mis à jour avec la livraison des binaires.

2. Si l’Azure function a été créé entièrement depuis le portail, il est modifiable via le menu App Files :

Par défaut, aucune configuration relative à l’Event Processor Host n’est présente. Ce sont des valeurs par défaut qui sont utilisées.
Voici les configurations spécifiques à l’Event Processor Host :

Voici un exemple avec la configuration ajoutée à un fichier host.json :
Une règle à connaître : il n’y a pas de règle magique. Pour trouver le bon réglage, il faut tester, modifier et tester, encore et encore et encore. Pour vous aider, voir la partie « Métriques et choix du paramétrage ».
Implémentation de l’ingestion
Les exemples à ne pas suivre
Selon la documentation Microsoft, le code implémenté peut ressembler à ceci :
Il existe par ailleurs sur Internet un nombre important de tutoriels qui véhiculent le même genre d’implémentation.
Sans doute l’aurez-vous deviné, je vous déconseille fortement de conserver ce type d’implémentation dans votre application en raison de la nature séquentielle du traitement, qui n’a par ailleurs pas de gestion d’erreurs.
Prenons un exemple :
- L’Event Hub possède 2 partitions.
- 200 messages envoyés.
- Ingestion séquentielle du code ci-dessus de la documentation Microsoft.
- Le traitement de chacun de ces messages est 1 Task.Delay de 1 seconde (une seconde pour faciliter les calculs et la représentation graphique).
Voici le résultat à l’aide des métriques (définies à la dernière section de l’article) :

è En orange, les messages envoyés par un seul client : 200 messages ont été envoyés en 20 secondes sur l’Event Hubs.
è En vert, chaque fin de message en succès. On peut constater que seulement 2 messages sont traités par seconde (1 seconde par message et 1 message par instance).
è En bleu, le nombre de messages traités, cette métrique n’étant loggée qu’à la fin de chaque « batch » d’ingestion pour en indiquer la fin.
Les deux premiers batchs d’ingestions sont lancés par l’Event Processor Host pour traiter 2 puis 8 messages (1ère et 2ème instance).
L’Event Processor Host va alors attendre la fin de ces deux instances pour en lancer deux nouvelles avec les messages en attente. Les 3ème et 4ème instances traitent 18 et 19 messages.
Enfin, l’Event Processor Host va lancer deux dernières instances (5 et 6) pour traiter les 160 messages restants. Le temps de traitement complet est d’environ 1 minute 45, soit 105 secondes pour 200 évènements.
Vous l’aurez compris, avec cette implémentation, votre ingestion de messages va rapidement se transformer en goulot d’étranglement.
Parallélisme de l’ingestion : The Visual studio Way « à améliorer »
Il est indispensable d’implémenter un parallélisme pour l’ingestion. Pour cela, vous pouvez utiliser le code généré par Visual Studio avec un avertissement.
Pour garder un parallélisme, vous pouvez créer une méthode asynchrone comme ceci :
⚠️ Point de vigilance : Pour conserver un parallélisme, dans la boucle, la ligne appelant la méthode asynchrone ne doit pas présenter de await. Sinon, elle devient séquentielle. Le piège, c’est que Visual Studio souligne cette ligne en vert pour indiquer que nous aimerions sans doute utiliser un await.

En un clic, il nous propose même de résoudre pour nous ce problème potentiel. Mais en faisant cela, on vient de rendre le code synchrone et on retombe sur les problèmes de performances évoqués précédemment.
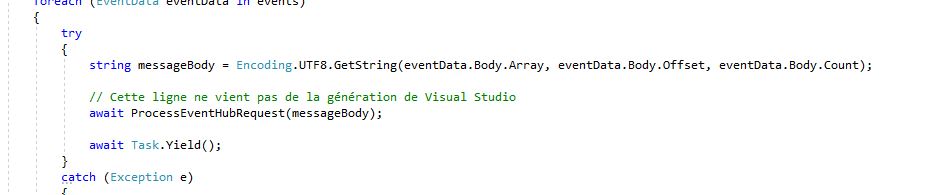
La manipulation est très tentante et même les experts aguerris manquent de se faire avoir régulièrement. Alors comment faire pour éviter de tomber dans ce piège ?
Parallélisme de l’ingestion : une méthode plus sécurisante
Le but recherché avec le parallélisme n’est pas de simplement lancer chaque tâche de manière asynchrone, mais vraiment de lancer le traitement de tous les messages sans attendre. Et le risque avec les async / await simples, est de se retrouver à lancer par inadvertance des tâches asynchrones mais qui attendent que la précédente soit terminée pour commencer.
On a tous connu un développeur peu au fait des await / async, trop pressé… ou en manque de caféine. C’est souvent nous-mêmes qui faisons des erreurs en modifiant le mauvais fichier, la mauvaise méthode, en allant trop vite.
Vous trouverez ci-dessous un exemple de code d’ingestion de messages que j’ai déjà implémenté de nombreuses fois avec succès et qui est purement asynchrone.
Je le préfère à celui de Visual Studio ou d’autres : il est moins susceptible d’être transformé en code séquentiel car il sépare bien le lancement des Tasks et l’attente de leur complétion.
Le but de l’implémentation est toujours de lancer l’exécution de tous les messages dans des threads séparés, tout en forçant l’utilisation d’une méthode asynchrone. Lorsque le lancement des tâches est effectué pour tous les messages du batch, on scrute les résultats.
A noter : la partie attente des résultats n’est pas obligatoire, mais est fortement recommandée. Les ressources du serveur qui exécute votre fonction sont limitées. Chaque thread lancé prend du temps processeur, de la mémoire, des slots TCP…


Prenons un exemple d’exécution avec 200 messages :
- L’Event Hubs possède 2 partitions.
- 200 messages envoyés (comme pour le traitement séquentiel).
- Ingestion parallèle du code recommandé ci-dessus.
- Le traitement de chacun de ces messages est 1 Task.Delay de 1 seconde (1 seconde pour faciliter les calculs et la représentation graphique).
Voici le résultat à l’aide des métriques (définies à la dernière section de l’article) :

On constate à présent que la courbe des messages traités suit celle des messages envoyés avec un peu plus d’une seconde de délai, ce qui correspond au temps de traitement. On ne peut donc pas faire mieux.
è On peut également constater que les messages de fin de batch suivent une courbe similaire.
L’envoi a pris une vingtaine de secondes mais le traitement à peine plus.
Métriques et choix du paramétrage d’Event Hubs
Maintenant que les clients envoient les messages le plus vite possible et que l’implémentation d’ingestion des messages est parallélisée, quel paramétrage de partitions et de nombre de messages traités choisir ?
Encore une fois, il n’existe pas de règle magique. Il va falloir mesurer pour vous aider à faire votre choix. Application Insights est l’outil parfait pour vous y aider. Pour effectuer la mesure, dans le code source du projet gitHub, vous trouverez un exemple de code qui va créer des custom metrics dans App Insights. Pour un maximum d’informations, vous pouvez ajouter un custom metric à la fin du batch d’ingestion :
Et un custom metric à la fin du traitement unitaire de messages :
Un simple log au moment de l’envoi du message par le client peut aussi vous être utile :
Voici une requête Kusto permettant de récupérer les métriques après exécution (il faut compter entre 2 et 5 minutes pour qu’elles apparaissent) :
A titre d’information, c’est avec cette requête que les graphiques utilisés dans cet article ont été créés, afin de montrer l’intérêt de la parallélisation.
Voici une requête Kusto un peu plus complexe permettant de représenter graphiquement la répartition du temps de traitement total par intervalle de temps de traitement.
On obtient un graphique similaire à celui-ci (sans rapport avec les exemples donnés ci-dessus) :

Pensez, lors de vos tests, qu’il est nécessaire que le temps de traitement de chacun de vos messages représente un délai raisonnable, en utilisant – dans la méthode ProcessEventHubRequest – un Task.Delay(xxx) où xxx est le nombre de millisecondes d’attente.
Avec un peu de pratique, vous pourrez très rapidement surveiller le délai d’attente, le nombre de message traités et les temps de traitements individuels.
Les métriques sont précises, très peu coûteuses en temps de traitement et quasiment en temps réel. Conservez ces métriques dans vos environnements de prod. Vous pourrez constituer de jolis dashboards avec les requêtes Kusto. N’hésitez pas à rajouter le plus tôt possible des métriques spécifiques à votre métier (pays, marque, version utilisée, etc.) Vos tableaux de bord seront non seulement utiles aux opérationnels pour suivre la bonne exécution, mais aussi à des utilisateurs du marketing ou du commerce. Présentez-leur une fois des dashboards : ils vous les réclameront immédiatement et ce sera autant de travail en moins pour leur compiler des données en fin de semaine ou de mois !
Vous pouvez également utiliser ces requêtes pour générer des alertes et prévenir si les temps de traitement sont trop importants ou si le nombre de requêtes dépasse des seuils.
Ainsi, par exemple, vous ne serez plus pris au dépourvu si, après un post d’une influenceuse, votre site web est submergé de requêtes : le marketing pourra réagir avec un message de bienvenue, la gestion des stocks pourra se préparer à passer une commande… Les possibilités sont infinies et ne seront plus dépendantes de la technique.
Je vous invite à consulter, sur le projet Git DemoEventHubIngestion associé à cet article, une implémentation fonctionnelle du code source parallélisée avec les métriques ci-dessus.
Event Hubs : à vous de jouer !
Event Hubs est un outil puissant, à la fois performant et robuste, à condition de le maîtriser et d’en éviter les pièges.
Après la lecture de ces deux articles, fruits de plusieurs mois de travail (au cours desquels beaucoup de cheveux ont été arrachés, de nombreux cris poussés et des malédictions prononcées) vous devriez à présent tout savoir – ou presque – sur l’optimisation des Event Hubs. Que vous utilisiez Event Hubs pour la première fois ou depuis des mois, vous êtes désormais en mesure de surmonter les principaux écueils, d’identifier les éléments difficiles à
N’hésitez pas à demander plus d’informations sur un point technique qui vous aurait semblé trop rapide. Je vous invite également à laisser un commentaire si des articles plus poussés sur l’optimisation et la mise en place de métriques vous intéressent.





