

Comment RAJA Group a construit une plateforme data unifiée avec Microsoft Fabric – et comment Cellenza a contribué à écrire...
28 septembre 2021
Combiner Transactionnel et Analytique : c’est maintenant possible !

Le HTAP (Hybrid Transactional/Analytical Processing) est un modèle de conception pour le traitement des données. Bien que ce terme ait fait son apparition dès 2014 dans le Gartner, son utilisation est assez récente dans l’écosystème Azure.
Distinguer deux charges de travail
Pour comprendre ce que signifie HTAP, il faut distinguer les deux types de charges de travail (workload) utilisées dans le traitement des données : transactionnelle (transactional) et analytique (analytic).
Pour ce faire, prenons un cas d’usage avec un site de vente en ligne :
- Différentes transactions ont lieu : créer/modifier/supprimer un compte client, passer une commande, faire un paiement, etc. Ces transactions sont sauvegardées dans une base de données.
C’est un stockage de données de type OLTP (Online Transaction Processing) qui est utilisé.
Quelques exemples de services OLTP dans Azure : Azure SQL Database, Azure Postgres, Azure Cosmos DB, etc.
è Il s’agit ici de charges de travail transactionnelles. - Afin de pouvoir prendre des décisions stratégiques, il est nécessaire d’analyser les données clients, ventes, stocks, etc. De manière classique, les données stockées dans la base de données transactionnelles vont être exportées pour alimenter une base de données de type OLAP (Online Analytical Processing).
Quelques exemples de services OLAP dans Azure : Dedicated SQL pools ou Databricks SQL.
è Dans ce cas-là, ce sont des charges de travail analytiques.
Pourquoi distinguer Transactionnel et Analytique ?
Dans le cas du transactionnel, les opérations doivent se faire très rapidement (de l’ordre de la milliseconde) et avec un grand nombre de requêtes en parallèle (plusieurs créations de compte, plusieurs commandes, etc.). Les opérations se font de manière « unitaire » : pour un client, pour une commande, etc.
Dans le cas de l’analytique, la temporalité n’est pas la même. Les temps de traitement n’ont pas besoin d’être aussi rapides et les volumes requêtés sont beaucoup plus importants puisque l’analyse se fera sur un ensemble de clients, un pays, une zone, etc.
Avantages d’un traitement hybride transactionnel/analytique
Pour plusieurs raisons (différences de schéma, performances, etc.), il n’est pas possible de faire de l’analytique sur des données transactionnelles. Il est donc nécessaire de mettre en place une architecture permettant d’exporter les mises à jour côté transactionnel pour alimenter le stockage analytique.
Ainsi, vous avez des données qui vont être dupliquées avec une architecture à maintenir pour vous assurer que l’analytique est aligné avec le transactionnel. Ce processus mettra un certain temps avant d’être synchronisé.
Comment faire pour réduire les coûts inhérents à cette architecture (traitement, maintenance, stockage, etc.) et les délais engendrés ?
Vous l’aurez compris, c’est là que le modèle HTAP fait son apparition !
Il présente donc deux avantages majeurs :
- Réduire la complexité d’une architecture pour synchroniser transactionnel avec analytique ;
- Réduire le temps entre les deux types de traitement de données.
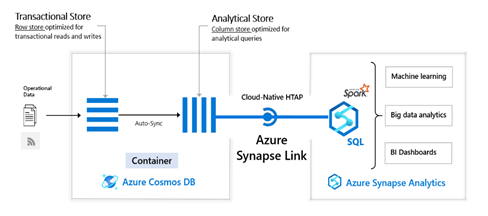
Azure Synapse Link
Azure Synapse Analytics met à votre disposition une fonctionnalité utilisant le modèle HTAP pour Cosmos DB : Azure Synapse Link.
Azure Cosmos DB fait partie de la famille OLTP et est une base de données NoSQL.
Elle est extrêmement efficace pour du transactionnel et très souvent utilisée dans le monde du retail, par exemple.
Si vous souhaitez faire de l’analytique à partir des données stockées dans votre base Cosmos DB, vous allez être amené à exporter les documents pour les charger ensuite dans un stockage dédié à l’analytique. L’export, l’import et la transformation des données pourront s’avérer complexes à mettre en place et à faire évoluer dans le temps. De plus, la bonne synchronisation des données peut s’avérer complexe.
La fonctionnalité Azure Synapse Link vous apporte une solution à ces problèmes.
Nous pouvons distinguer deux parties de Azure Synapse Link :
- La copie des données permettant de passer du transactionnel à l’analytique ;
- L’exploitation de ces données.
Copie des données
L’activation de la fonctionnalité Azure Synapse Link sur une base Azure Cosmos DB aura pour effet de créer une copie des données des différents conteneurs.
Il y a donc bien une copie… mais ce n’est pas vous qui la gérez ! La synchronisation se fait automatiquement. La copie permet également d’éviter les impacts en termes de performance sur la partie transactionnelle lors de l’exécution de la charge de travail analytique.
Et surtout, cette copie est stockée en mode colonne alors que l’original est stocké en mode ligne.
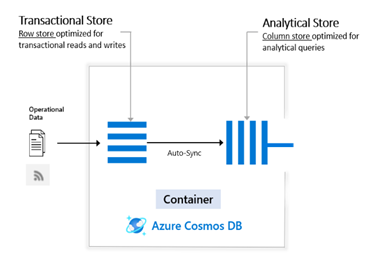
Classiquement, les données du monde relationnel sont stockées sur disque une ligne après l’autre.

L’intégralité de la première ligne avec tous ses champs est stockée, puis vient la ligne 2, la ligne 3, etc.

Dans le monde analytique, les données sont souvent stockées en colonne : dans l’ordre, c’est la colonne « ID » qui est stockée, puis la colonne « Product Name » et ainsi de suite :

Le stockage en colonne permet de compresser les données. Par exemple, la colonne « Product Category » contient la valeur « Equipment » pour les lignes 2 et 3. Plutôt que de stocker deux fois la même valeur, il est possible d’indexer cette valeur. Ainsi, la valeur « Equipment » pourra être liée à la ligne 2 et à la ligne 3. Dans certains cas de valeurs se répétant souvent, cela permet de réduire considérablement le volume, limiter les entrée/sorties (I/O) et de fait, accélérer les requêtes.
Après avoir vu la première partie d’Azure Synapse Link, voyons maintenant comment il est possible d’interroger cette version analytique des données.
Exploitation des données
L’exploitation des données se fait par l’intermédiaire d’Azure Synapse Analytics (pour approfondir le sujet, nous vous invitons à lire notre précédent article sur Azure Synapse Analytics)
Au sein d’Azure Synapse Analytics, deux moyens sont mis à votre disposition :
- Spark pool
- Serverless SQL pools
Spark pool
Voici un exemple d’interrogation d’un conteneur « Customer » du compte Cosmos DB « AdventureWorksSQL » :

Serverless SQL pool
Voici un exemple d’interrogation avec Serverless SQL pool :

Autres exemples de mise en place du HTAP
Bien sûr, l’aventure ne s’arrête pas là : même si le temps s’est réduit entre les parties transactionnelle et analytique, vous aurez besoin de faire des transformations et de réorganiser les données à travers un modèle de données sémantique.
Azure Synapse Link n’est pas le seul exemple de mise en place du HTAP. En voici d’autres :
- https://channel9.msdn.com/Shows/Data-Exposed/How-Azure-SQL-Enables-Real-time-Operational-Analytics-HTAP-Part-1
- Postgres Hyperscale
- Etc.
Vous avez des questions sur la mise en place du HTAP ? Vous utilisez déjà Azure Synapse Link ? N’hésitez pas à nous laisser un commentaire !





