

Comment RAJA Group a construit une plateforme data unifiée avec Microsoft Fabric – et comment Cellenza a contribué à écrire...
22 octobre 2020
Data Sec : traiter les données avec Azure Databricks en toute sécurité

Dans un précédent article, nous avons vu les points essentiels pour le stockage de la donnée, sur le Cloud Azure, en termes de sécurité. Nous allons désormais aborder la sécurité des données lorsque celles-ci sont traitées en utilisant Azure Databricks. Nous étudierons notamment les bonnes pratiques pour :
- Faire transiter les données de façon sécurisée d’un point de vue réseau ;
- Gérer les utilisateurs au niveau du workspace ;
- Contrôler l’accès à la donnée ;
- Préparer les phases d’audit.
Sécurité des données au niveau du réseau
Architecture de la plateforme Azure Databricks
Avant d’aborder la configuration réseau à adopter, il est nécessaire de rappeler comment est constituée l’architecture de Databricks.
Azure Databricks est une application managée qui comporte deux composants :
- Le « Control Plane » : il s’agit d’une couche de gestion hébergée au sein d’une souscription gérée par Microsoft dans Azure. Cette couche met à disposition plusieurs services : l’application web, la gestion des clusters, des jobs, etc. Chaque service a son propre mécanisme permettant d’isoler les traitements, les métadonnées et les ressources par l’intermédiaire d’un identifiant au workspace. Cet identifiant est ensuite utilisé pour l’exécution de chacune des requêtes.
- Le « Data Plane » : il s’agit d’un réseau virtuel créé au sein de la souscription Azure du client. Tous les clusters sont créés au sein de ce VNET et c’est également là qu’ont lieu tous les traitements de données.

Azure Databricks n’a pas vocation à stocker des données. Les données sont stockées dans différents services : Cosmos DB, Azure Synapse, Azure Data Lake Store, etc.
En revanche, un échange de données s’effectue lors du traitement de ces données. Azure Databricks chiffre les données en transit avec TLS (Transparent Layer Security).

Dans le mode de déploiement par défaut, la VNET du Data Plane et les groupes de sécurité (NSG) sont managés par Microsoft (même si les ressources sont provisionnées dans la souscription du client).
Dès lors, le client ne peut pas effectuer de changements sur ces ressources, pour éviter une mauvaise configuration de la part des utilisateurs.
Ce mode de déploiement permet de répondre aux besoins d’une partie des utilisateurs, mais certaines entreprises ont besoin de plus de contrôle sur la configuration des services, afin de respecter les politiques internes de sécurité et de gouvernance. Ils ont besoin de personnaliser la configuration pour, par exemple :
- Connecter les clusters Azure Databricks à d’autres services via des Service Endpoints ;
- Connecter les clusters Azure Databricks aux sources de données on-premise ;
- Restreindre le trafic sortant à des services Azure ou externes spécifiques ;
- Configurer des CIDR (Classless Inter-Domain Routing) spécifiques pour les clusters Azure Databricks ;
- Etc.
Bring Your Own VNET
Afin de pouvoir accéder à ce niveau de personnalisation, Azure Databricks permet le déploiement d’un workspace Azure Databricks dans un VNET managé par le client (avec une feature appelée Bring Your Own VNET ou VNET Injection).
Avec cette fonctionnalité, les règles de sécurité du workspace Azure Databricks sont gérées par le client, qui peut ajouter des règles (au-delà des règles de base nécessaires au bon fonctionnement du workspace).
On peut voir ci-dessous un exemple de cette architecture avec une connexion vers des sources de données on-premise :

Voici d’autres exemples de ce qu’on peut faire grâce à la VNET injection :
- Connectivité à des sources de données on-premises : il sera toutefois nécessaire de whitelister le trafic du « Control plane » Databricks à l’aide de la table de routage Azure UDR ;
- Routage du trafic sortant à l’aide de règles de pare-feu ;
- Configuration de Subnets Azure Databricks en tant que source dans les règles de pare-feu pour Azure Blob Storage, Azure Data Lake Store, Azure SQL Data Warehouse etc. Cette fonctionnalité nécessite Azure Service Endpoints.
Nous vous invitons également à consulter la documentation suivante :
- Documentation de Databricks sur la feature « Bring Your Own VNET » ;
- Documentation de Microsoft sur le déploiement de Azure Databricks dans votre réseau virtuel Azure « VNet injection ».
Gestion des utilisateurs
Gestion des droits des utilisateurs
Dans Azure Databricks, vous pouvez gérer les droits de vos utilisateurs du workspace à plusieurs niveaux :
- au niveau des répertoires ;
- au niveau des notebooks ;
- au niveau des clusters ;
- au niveau des tables ;
- au niveau des jobs.
Notons que l’espace Shared est à part : tous les utilisateurs ont accès à cet espace, quels que soient les droits qui ont été positionnés.
Il est donc conseillé de créer un répertoire au même niveau que Shared et Users dans lequel vous pourrez mettre les notebooks qui sont orchestrés.
Vous en trouverez ci-dessous un exemple avec le répertoire run :


Lier Azure Databricks à l’Azure AD avec SCIM
Azure Databricks supporte SCIM (System for Cross-domain Identity Management). Il s’agit de normes ouvertes pour automatiser le provisionnement des utilisateurs. Ainsi, il est possible de synchroniser votre workspace avec Azure Active Directory (AAD).
Vous pouvez facilement gérer les accès aux utilisateurs. De plus, lorsque l’utilisateur n’existe plus dans l’Azure AD, l’accès au workspace Azure Databricks n’est plus possible.
Pour cela, vous devez disposer d’un compte Azure AD Premium et être administrateur. Les étapes sont les suivantes :
- Créer, au niveau de l’Azure AD, une application d’entreprise permettant de faire le lien entre l’Azure AD et Databricks ;
- Affecter des utilisateurs et/ou groupes à l’application d’entreprise.
Si des utilisateurs ont déjà accès au workspace et font partie de l’Azure AD, ils seront automatiquement ajoutés à l’application d’entreprise. Sinon, ces comptes seront ignorés et ils continueront à avoir accès.
Pour consulter la procédure, nous vous invitons à vous référer à la documentation Microsoft.
A l’heure où nous écrivons cet article, cette fonctionnalité est en public preview.
Gestion des secrets avec les “secret scopes”
Un « secret scope » est une collection de secrets identifiée par un nom. Il existe deux types de « secret scope » :
- Azure Databricks ;
- Azure Key Vault.
Azure Databricks scope
Au sein de Azure Databricks, il est possible de créer des secrets scope afin d’y stocker un ou plusieurs secrets. Ces secrets sont stockés dans une base de données chiffrée.
Cela permet de ne pas utiliser des secrets en clair dans des notebooks.
L’utilisateur va uniquement faire référence au scope et au secret auquel il souhaite accéder, sans en voir le contenu.
Prenons l’exemple ci-dessous pour définir la configuration nécessaire à un point de montage dont nous parlerons ultérieurement :

La commande est :
La création du scope se fait en utilisant Databricks CLI.
Il est nécessaire d’avoir au préalable configuré Databricks CLI pour pouvoir accéder au workspace.
Création du scope :
Ajout d’un secret au scope :
Une fois la commande lancée, le bloc-notes s’ouvre. Vous pouvez alors y mettre le secret (par exemple l’ID du client d’un service principal) puis enregistrer le document.
La commande suivante permet de lister les secrets créés au sein d’un scope :
Il existe 3 niveaux d’accès aux secrets, gérés au niveau du scope :
- « Manage » : autorise à modifier les droits, lire et écrire le secret scope ;
- « Write » : autorise à écrire et lire le secret scope ;
- « Read » : autorise à lire le secret scope.
Il est possible d’attribuer des droits à un groupe ou à un utilisateur sur un scope. Par exemple, pour attribuer un droit de niveau MANAGE à l’utilisateur John Doe :
Azure Key Vault scope
Dans ce cas, comme précédemment, le secret scope est créé au sein de Azure Databricks. En revanche, les secrets sont stockés au sein d’un Azure Key Vault.
Azure Databricks doit avoir les droits sur le Key Vault pour pouvoir y accéder.
Pour créer un Azure Key Vault scope, il n’est pas possible, au moment où nous écrivons ces lignes, de le créer en utilisant Databricks CLI.
Il faut passer par l’interface graphique de Azure Databricks en accédant à : https://<votre_instance_databricks>#secrets/createScope
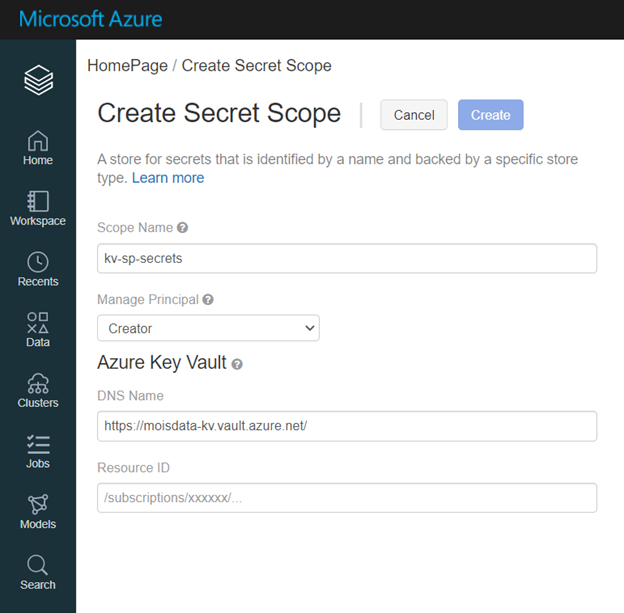
Pour remplir le champ « DNS Name » et « Resource ID », il faut aller dans les propriétés du Key Vault pour récupérer respectivement « Vault URI » et « Resource ID ».
Il est aussi possible de le faire en utilisant la CLI Databricks (ce qui permet d’automatiser le processus) :

Vous pouvez ensuite accéder, par l’intermédiaire du scope, aux secrets stockés dans votre Azure Key Vault.
Accès au scope via les groupes
Maintenant que nous avons vu comment créer des secret scopes, définissons maintenant quel groupe aura accès ou non à un secret scope.
Accès à la donnée
Configurations réseau pour un accès sécurisé à la donnée
Dans le cadre de la configuration réseau, il est recommandé d’utiliser une connectivité entre la VNET dans laquelle Azure Databricks est déployé, et les services de données Azure garantissant que le trafic ne sorte pas du “backbone” Azure.
Il existe deux options qu’on peut recommander comme bonnes pratiques : l’utilisation de Azure Private Link ou des Azure VNET Service Endpoints.
Chacune de ces options comporte ses propres avantages et inconvénients (et supporte uniquement certains service Azure Data). Pour approfondir le sujet, nous vous invitons à consulter le billet du blog Databricks traitant cette thématique.
Si l’on choisit le Service Endpoints pour accéder à ADLS Gen2, il est possible de configurer des règles dans le firewall du service ADLS Gen2 afin de permettre l’accès aux données uniquement à partir de certains VNET.
Connexion aux sources de données
Il existe de nombreuses sources de données pouvant être utilisées avec Azure Databricks : Azure SQL, Cosmos DB, Azure Synapse, etc.
Dans cet article, nous allons traiter uniquement l’accès aux données à partir d’un ADLS Gen2.
Il existe 3 moyens d’accéder aux données :
- Accès via un service principal :
- Avec un point de montage sur DBFS,
- Accès direct via un service principal.
- Accès avec une access key du storage account ADLS Gen2 ;
- Credential passthrough.
Nous allons voir en quoi consiste chacun de ces moyens d’accès et dans quels cas les utiliser.
Notons que dans le cas d’un accès à un compte de stockage (et non un ADLS2), vous avez uniquement besoin de l’access key. Ce cas spécifique ne sera pas traité ici).
Accès aux données via un service principal
Accès via un point de montage
Le point de montage consiste à créer un chemin d’accès vers un conteneur et des répertoires d’un Azure Data Lake Store.
Les étapes sont les suivantes :
- Création d’un service principal au niveau de Azure Active Directory ;
- Accorder les droits au service principal sur l’ADLS au niveau des RBAC et au niveau des ACLs (pour en savoir plus, découvrez notre précédent article) ;
- Création du point de montage dans Azure Databricks.
L’accès au Data Lake se fait facilement via le point de montage.
En revanche, l’inconvénient est que tous les utilisateurs du workspace peuvent accéder à ce point de montage. Il n’est en effet pas possible de mettre des restrictions d’accès sur un point de montage.
Vous retrouverez l’intégralité de la procédure dans la documentation Microsoft.
Vous pouvez lister les points de montage disponibles :
Voici enfin la commande à exécuter pour supprimer un point de montage :
Accès direct avec service principal et OAuth 2.0
Il est possible d’accéder directement au Data Lake en donnant aux utilisateurs concernés une délégation d’accès au Service Principal.
Dans un premier temps, il faut configurer les variables d’environnement :
Ensuite, il est possible d’accéder directement au Data Lake :
Nous avons vu précédemment que l’accès aux secrets était géré par des droits. Un utilisateur n’ayant pas le droit d’accéder aux secrets contenant les credentials du service principal (client ID et client secret) ne sera pas en mesure d’exécuter la commande et ne pourra pas accéder aux données.
Accès avec une access key du storage account ADLS Gen2
Avec les API DataFrame ou DataSet, il suffit d’ajouter les clés d’accès à la configuration Spark de votre notebook (via un secret, bien sûr !) :
Dès lors, vous pouvez lire ou écrire via les API :
Dans le cas des API RDD, il faut spécifier les clés d’accès dans la configuration Hadoop :
Dans ce dernier cas, l’inconvénient est que les clés d’accès seront accessibles à tous les utilisateurs du cluster. En effet, on utilise :
qui est une configuration globale au niveau du cluster. Dans le cas de l’API Data Frame, on a utilisé spark.conf qui est au niveau de la session.
Méthode du credential passthrough
Cette méthode permet aux utilisateurs de s’authentifier sur les services ADLS (Gen1 ou Gen2) en utilisant la même identité Azure AD que celles qu’ils utilisent pour s’identifier sur Azure Databricks. Quand on lance une commande sur Azure Databricks, l’accès aux données est fait avec l’identité de l’utilisateur et est géré directement via les rôles et les ACLs existants sur ADLS2.
Cette méthode d’accès se fait donc sans utiliser de services principaux. Elle comporte toutefois quelques limitations quant aux commandes pouvant être exécutées et aux features supportées .
La configuration se fait au niveau du cluster :

ACLs sur les tables
Les approches précédentes permettent une gestion de l’accès aux données sur ADLS. Il est aussi possible d’utiliser des ACLs sur les tables crées sur Azure Databricks et de gérer l’accès aux données à ce niveau.
Dans ce scénario, le cluster possède un service principal permettant d’accéder aux données ADLS de toutes les tables, et les ACLs côté Azure Databricks, qui permettent de restreindre l’accès aux tables à des utilisateurs ou groupes d’utilisateurs.
Les Tables ACLs permettent de gérer les accès aux tables. Une configuration au niveau du cluster garantit l’application des ACLs. Cette fonctionnalité est limitée aux commandes SQL et/ou Python : l’utilisation des clusters avec Table Access Controls restreint donc l’utilisation des autres APIs.

Audit des accès aux données
Il est possible d’activer l’accès aux logs Azure Databricks, afin de monitorer de façon détaillée les activités des utilisateurs sur la plateforme.
Ces logs peuvent ensuite être analysés, par exemple avec Azure Log Analytics.
Des bonnes pratiques à appliquer
Nous venons d’étudier les bonnes pratiques à utiliser en termes de sécurité lors de l’utilisation de Azure Databricks pour traiter les données.
N’oublions pas qu’une sécurité efficace passe nécessairement par une application combinée de chacune de ces bonnes pratiques.
✍️ Cet article a été co-rédigé par nos experts data : Donatien Tessier (Cellenza) et Arduino Cascella (Solutions Architect Databricks)






