

Comment RAJA Group a construit une plateforme data unifiée avec Microsoft Fabric – et comment Cellenza a contribué à écrire...
23 novembre 2021
Exploiter le Change Data Capture (CDC) avec Kafka et Azure Databricks (Partie 2/2)

Dans l’article précédent, nous avons défini l’architecture d’un projet vous permettant de reproduire presque en temps réel votre base de données SQL on-premises dans un environnement Azure et vu comment activer la fonctionnalité CDC sur notre base de données.
Nous allons maintenant faire remonter ces données vers un Azure Event Hub via Kafka/Kafka Connect en utilisant un connecteur Debezium.
Une fois ces données publiées dans l’Event Hub, nous utiliserons Azure Databricks pour consommer et traiter ces messages et au final, reproduire les tables de notre base SQL on-premise dans un Azure Data lake Gen 2.
Récapitulatif :
Partie I – Activation du CDC sur les tables SQL et mise en place de l’environnement Azure
- Enregistrer les changements de la bdd => CDC (SQL Server)
- Déploiement des ressources de l’environnement Cloud Azure
Partie II – Abonnement aux données CDC via Kafka et Debezium
- S’abonner à ces changements => Kafka et Debezium
- Stockage les messages => Azure Event Hub
- Consommation, traitement et stockage de ces messages => Azure Databricks/Data lake

Installation de Kafka et Kafka Connect
Pour remonter nos données CDC vers Azure Event Hub, nous utiliserons :
- Apache Kafka, un système de messagerie distribué, développé par LinkedIn il y a 10 ans.
- Kafka Connect, une extension de Kafka qui fournit une interface en entrée et en sortie de ce dernier.
Kafka et Kafka Connect nécessitent l’installation de plusieurs composants :
- Java : Java SE Development Kit 16 – Downloads (oracle.com)
- Zookeeper, qui est le gestionnaire de fichiers de Kafka, et Kafka : Apache Download Mirrors(13-2.8.0.tgz)
Vous pouvez renommer le répertoire kafka_2.13-2.8.0 en kafka et le placer où vous le souhaitez sur votre disque :

Nous allons ensuite pouvoir modifier les fichiers de configuration de Zookeeper, Kafka et Kafka Connect.
1. Zookeeper:
Pour configurer Zookeeper, ouvrez zookeeper.properties et ajoutez le path dans lequel il stockera ses logs et configurations :
dataDir=S:/kafka/data/zookeeper-data
Lançons maintenant Zookeeper en ligne de commande :
> cd S:\kafka\bin\windows > ./zookeeper-server-start.bat ../../config/zookeeper.properties
2. Kafka
Même chose que pour Zookeeper dans le fichier server.properties , ajoutons le path de logs :
log.dirs=S:/kafka/data/kafka-data
Lançons maintenant Kafka en ligne de commande :
> cd S:\kafka\bin\windows > ./kafka-server-start.bat ../../config/server.properties
3. Kafka Connect
Configurez le fichier connect-distributed.properties :
Modifiez les valeurs des paramètres bootstrap.servers et producer.sasl.jaas.config avec le nom et les connection string de Event Hubs que nous avons créées dans la première partie.
Puis lançons maintenant Kafka Connect en ligne de commande :
> cd S:\kafka\bin\windows >./connect-distributed ../../config/connect-distributed.properties
Kafka Connect workers standalone versus distributed mode :
Il existe 2 modes d’exécution de Kafka Connect : en mode autonome (standalone) ou en mode distribué :
- En mode standalone, un seul processus exécute tous les connecteurs. Il n’est pas tolérant aux pannes. Comme il n’utilise qu’un seul processus, il n’est pas scalable. Il est en général utilisé par les utilisateurs dans la phase de développement et de test.
- En mode distribué, plusieurs workers exécutent Kafka Connect. Dans ce mode, Kafka Connect est scalable et tolérant aux pannes. Il sera donc utilisé dans le déploiement en production avec un cluster de VM.
Pour capter les changement CDC de notre base de données, nous aurons besoin d’un connecteur supplémentaire : Debezium.
Associer le connecteur Debezium à Kafka pour gérer les données CDC
Debezium est un outil open source pour la capture de changement de données (CDC). Il est développé au-dessus de Kafka et va capturer et publier, enregistrement par enregistrement, les modifications (create, delete, update et les modifications de schéma) apportées dans une base de données sous forme de flux d’événements.
Debezium dispose d’une liste de connecteurs compatibles avec plusieurs systèmes de gestion de bases de données : MySQL, MongoDB, PostgreSQL, Oracle, SQL Server, etc.
Commençons par télécharger le connecteur dédié aux bases MS SQL :
Extrayez les fichiers et ajoutez les dans le folder : S:\kafka\libs
Configuration et création du connecteur
Après avoir placé le plugin Debezium MS SQL dans ce dossier libs et vérifié que nos services Zookeeper, Kafka et Kafka Connect sont toujours en cours d’exécution, nous allons pouvoir configurer et enregistrer auprès de Kafka Connect notre premier connecteur Debezium en utilisant une commande PowerShell :
Quelques précisions sur la configuration :
- « database.XX »: indiquer les informations relatives à votre base de données ;
- Le user : est le user SQL avec des droit db_datareader que nous avons créés dans la 1ère partie.
- « snapshot.mode »: vous avez différents modes pour MSSQL (cf. documentation ci-dessous), le mode initial vous permet de récupérer l’historique de la table ; puis de récupérer les modifications ultérieures enregistrées dans la table CDC.
- « transforms »: »Reroute » : permet de rediriger l’envoi des évènements vers le même topic (si vous avez une dizaine de tables, vous préférerez peut-être que les données soient renvoyées vers un seul topic et non 10).
⚠️ Attention : chaque namespace Event Hubs a une limite sur le nombre d’Event Hubs qu’il peut contenir (correspondant au nombre de topics), dictée par le niveau (tier). Pour un non-dedicated tier, un espace de noms Event Hubs peut avoir jusqu’à 10 topics Event Hub, chacune contenant 1 à 32 partitions. => Consulter la documentation sur les quotas et les limites d’Event Hubs.
Description de l’enveloppe CDC Debezium
L’enveloppe qui vous est renvoyée par le connecteur Debezium contient plusieurs éléments :
L’enveloppe se compose d’un schéma (en abrégé ici) et d’un payload, dans lequel on peut voir des propriétés before et after qui contiennent l’état de la ligne avant et après modification.
Elle indique également le type d’opération effectuée :
- ‘’r’’ ou read : lecture d’une ligne existante lors du snapshot initial de la table ;
- ‘’c’’ ou create : opération de création (vous remarquerez d’ailleurs que la propriété before dans le payload est null) ;
- ‘’d’’ ou delete : opération de suppression (dans le payload, la propriété after est null) ;
- ‘’u’’ ou update : opération de modification (dans le payload, vous pourrez voir les changements en comparant before et after).
Pour plus d’informations, n’hésitez pas à consulter la documentation technique Debezium.
Récupération des données CDC côté Azure Event Hub
Avec vos 3 services (Zookeeper, Kafka et Kafka Connect) et votre connecteur Debezium MSSQL, vous allez commencer à envoyer les enregistrements CDC dans le topic créé (le nom du topic est celui que vous avez indiqué dans le paramètre transforms.Reroute.topic.replacement de votre connecteur Debezium :

Pour fonctionner, Kafka Connect crée par défaut 3 topics de configuration (connect-cluster-configs, connect-cluster-offsets, connect-cluster-status) – à ne pas supprimer donc !
Une fois les connecteurs lancés et connectés au Event Hub, vous pouvez lancer une requête directement depuis Event Hub pour consulter les messages contenant les enveloppes CDC et consulter le trafic généré :

Pour aller plus loin : https://docs.microsoft.com/en-us/azure/event-hubs/event-hubs-kafka-connect-debezium
Traitement des données CDC dans Azure Databricks
Nos données CDC sont donc remontées dans notre Event Hub et prêtes à être consommées et traitées pour reproduire nos tables dans le Data Lake.
Pour cela nous allons utiliser Azure Databricks, avec lequel nous allons :
- Récupérer les messages de l’EventHub et stocker les payloads des enveloppes Debezium que nous avons vues précédemment ;
- Traiter les payloads pour récupérer les informations de modifications par table et recréer les tables qui seront stockées dans un Azure Datalake Gen2.
Consommation des données brutes CDC contenues dans l’Event Hub
Commençons par créer une chaîne de connexion avec le nom du Event Hub et sa shared access key (« RootManageSharedAccessKey » du Event Hub).
Il est recommandé de stocker la shared access key dans un Azure Key Vault en tant que secret et de récupérer le secret à l’aide de Databricks Utility comme montré dans l’extrait de code suivant :
Un dictionnaire de configuration de l’Event Hub va contenir la propriété de chaîne de connexion et les autres configurations nécessaires. Ce dictionnaire de configuration requiert que la propriété de chaîne de connexion soit chiffrée :
pyspark
Lire les évènements à partir du Event Hub grâce à l’API de streaming Pyspark
Maintenant que nous avons configuré avec succès le dictionnaire de configuration du Event Hub, nous allons utiliser l’API readStream de streaming structuré pour lire les événements depuis Event Hub, en ne sélectionnant que la colonne qui contient nos données CDC (« body »), comme indiqué dans l’extrait de code suivant :
Vous pouvez visualiser le flux consommé :
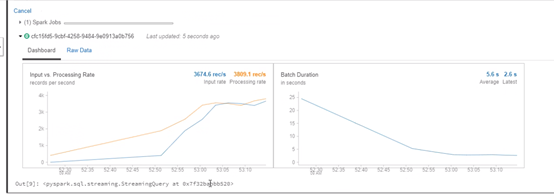
Nous allons stocker les données de ce streaming dans notre conteneur bronze de notre Datalake au format Delta :
Traitement des données brutes CDC contenues dans Event Hub
Récupérons les données que nous venons de stocker lors de la consommation du Event Hub :
Nous allons maintenant formater la partie payload / after de l’enveloppe CDC Debezium :
Lors de la phase d’initialisation, nous allons uniquement récupérer de l’enveloppe CDC Debezium les données du champ « after » pour lesquelles l’operation était “r” (read = données présentes au moment de l’activation du CDC) :
La partie update sera gérée en utilisant un MERGE qui est une fonctionnalité de Delta.
Nos tables SQL sont désormais stockées dans notre container bronze de notre Azure Datalake !
Pour automatiser le lancement de ce process, vous pouvez créer un job dans Azure Databricks et planifier à l’avance l’exécution automatique de ce notebook :

Nous avons activé la fonctionnalité de Change Data Capture (CDC) pour capter les modifications réalisées sur les tables d’une base de données SQL.
Puis nous avons remonté ces données CDC grâce à Kafka/Kafka Connect et le connecteur Debezium vers un Azure Event Hubs.
Enfin, nous avons consommé et traité ces données CDC grâce à Azure Databricks pour reproduire les tables et leurs modifications dans un Azure Data lake Gen 2.
Vous savez désormais comment propager en quasiment temps réel les modifications d’une table SQL on-premise vers un environnement Cloud !





