

Comment RAJA Group a construit une plateforme data unifiée avec Microsoft Fabric – et comment Cellenza a contribué à écrire...
20 mars 2018
IA / Machine Learning : créer des agents intelligents (1/2)

Nous y voilà enfin ! Suite au premier article sur l’introduction au Machine Learning, que je vous invite à lire si ce n’est pas déjà fait, nous allons pouvoir répondre aux attentes de John Doe grâce aux deux fichiers csv qu’il nous a fournis. Pour ce faire, j’ai prévu de commencer par une présentation des bases : une analyse exploratoire des données, une matrice de corrélation puis l’application de quelques algorithmes de Machine Learning comme la régression linéaire et le KNN.
- Introduction : de la perception à l’action
- Créer un agent intelligent (1/2)
- Créer un agent intelligent (2/2)
- Les réseaux neuronaux : Skynet is back
- Comment évaluer et déployer son modèle dans Azure.
Prérequis :
Le code fourni tout au long de cet article sera exclusivement en Python. J’utiliserai un notebook Jupyter online fourni par Azure Machine Learning Studio disposant de toutes les dépendances déjà installées. Si vous souhaitez utiliser un autre éditeur de développement, il vous faudra installer Pandas et Sklearn :
pip install pandas pip install sklearn
Pour ceux qui ne souhaitent pas coder en Python, vous trouverez dans la section Bonus toute l’expérience Azure ML sous forme de workflow.
Bonnes pratiques :
Avant toute implémentation, il est important de se poser les bonnes questions, à savoir :
- Est-ce que, visuellement, mes données suivent une certaine logique ?
- Est-ce que ce type de distribution est connu (gaussienne, uniforme, etc.) ?
- Observe-t-on une structure graphique telle qu’une ligne droite, une courbe ou d’autres aspects connus (fonction exponentielle, sinusoïdale, etc.) ?
Toutes ces questions vous permettront d’accélérer considérablement votre analyse.
Tip 1 : Analyse Exploratoire de Données :
Elle s’appuie sur différentes approches de visualisation des données couplées aux notions statistiques. Il est ainsi possible de formuler très rapidement des hypothèses sur des « faits » représentés par vos données. Le principal avantage de cette analyse est qu’elle permet de vite constater la « structure interne » de notre jeu de données sans pour autant en dire long sur le « comment ». On pourra dès lors savoir si les données sont verbeuses ou non, s’il faut envisager de répéter l’expérience avec un autre jeu de données et d’autre part, de nous aider à sélectionner le modèle prédictif à mettre en place.
Tip 2 : Matrice de Corrélation :
Comme son nom l’indique, cette matrice permet d’étudier la « relation » qui peut exister entre deux variables de votre jeu de données de façon à ce que tous les couples possibles aient été testés. En d’autres termes, si vous avez N colonnes dans votre dataset, la matrice de corrélation aura N² cases dont chacune aura une valeur comprise entre -1 et 1. Le signe détermine le sens de variation :
- Signe positif (+) : les deux variables croissent ou décroissent ensemble ;
- Signe négatif (-) : la croissance de l’une entraîne la diminution de l’autre et inversement.
| Col A | Col B | Col C | |
| Col A | 1 | 0.46 | 0.003 |
| Col B | 0.46 | 1 | 0.20 |
| Col C | 0.003 | 0.20 | 1 |
(Exemple de matrice de corrélation)
Pour résumer, plus le coefficient de corrélation est proche de |1|, plus vos variables sont corrélées. Elles sont dites muettes (ou non corrélées) si le coefficient est proche de zéro. On pourra alors se passer de certaines variables qui n’agissent pas fortement sur notre variable d’intérêt.
Notre Jeu de données :
Comme promis, John Doe nous a fourni deux fichiers csv :
- Sells_2025_2026.csv : qui contient l’historique des ventes réalisées entre 2025 et 2026 ainsi que certaines informations supplémentaires du consommateur. On distingue notamment en colonnes :
- Âges : l’âge du consommateur
- Cities : la ville du consommateur
- Temp : la température du jour
- Treated : la probabilité qu’il soit sous traitement
- Date : la date de vente
- Marketing_2025_2026.csv : contient des informations sur la campagne marketing réalisée entre 2025 et 2026 pour promouvoir la fameuse boisson mémoria. On distingue notamment :
- Cities : la ville de promotion
- Tweets : le nombre de tweets publiés sur les réseaux
- Flyers : le nombre de flyers distribués dans les rues
En retour, il s’attend à ce que nous apportions des éléments de réponse sur la situation de ses ventes qu’il juge insatisfaisante.
C’est parti pour l’analyse des données !
Commençons par jeter un œil à notre fichier de ventes en affichant les 10 premières lignes du fichier.
Avec Azure ML :
Connectez-vous sur Azure ML Studio, importez le dataset et ouvrez le dans jupyter :
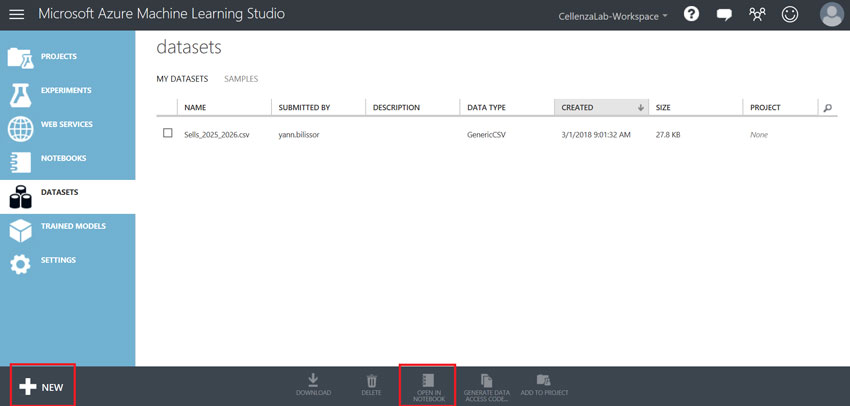
(Import du dataset dans Azure ML)
Dans le notebook jupyter, remplacer le code par celui-ci :
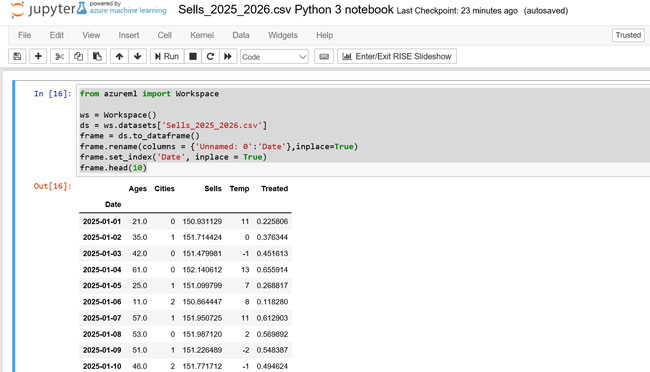
(Visualisation des 10 premières lignes du fichier)
Sans Azure ML :
Ouvrez votre éditeur préféré et entrer les lignes de code suivantes :
import pandas as pd ... filename = "YOUR FILE LOCATION" dataframe = pd.read_csv(filename,index_col=0) printf(dataframe.head(10))
Vous aurez remarqué que nous importons une bibliothèque appelée Pandas pour le chargement et la manipulation des données. Elle est très utilisée, voire incontournable en Python lorsqu’il s’agit de traiter de gros volumes de données.
Ensuite, on peut utiliser des notions de statistiques descriptives pour comprendre un peu mieux nos données. Pour ce faire, notre dataframe contient une méthode describe assez intéressante qui résume beaucoup d’informations dans une matrice :

(Statistique descriptive de nos données)
On peut constater que notre jeu de données possède 477 lignes, que la moyenne d’âge est de 43,98 ans et que chaque individu ayant acheté la boisson mémoria entre 2025 et 2026 a en moyenne 47% de chance d’avoir déjà été sous traitement, etc. Toutes ces mesures nous permettent déjà de faire germer des hypothèses que nous essayerons de vérifier par la suite.
Hypothèse 1 :
Je constate que la moyenne d’âge est d’environ 44 ans et que chaque individu de cet âge a moins d’une chance sur deux d’avoir été sous traitement. Mais lorsque l’on observe les 10 premières lignes du fichier, on se rend compte que 4 individus de plus de 50 ans ont plus d’une chance sur deux d’avoir été sous traitement. Devrais-je en déduire que l’âge de l’individu agit sur le fait qu’il ait été probablement malade ?
Vérifions cette hypothèse :
Pour vérifier cette hypothèse, nous pouvons visualiser par le biais d’un nuage de points, la probabilité d’avoir été sous traitement par rapport à l’âge.
Code à utiliser :
frame.plot.scatter(x = 'Ages',y = 'Treated')
Ce que l’on obtient :

(Nuage de points : traitement par rapport à l’âge)
Comme nous l’avons supposé précédemment, on constate effectivement que la probabilité d’avoir été sous traitement varie linéairement par rapport à l’âge. Notre hypothèse se confirme.
Hypothèse 2 :
Je constate également que les ventes représentées par la colonne Sells augmente lorsque l’âge augmente et idem avec la colonne Treated. Cela veut-il dire que les trois colonnes sont corrélées ?
Vérification de l’hypothèse 2 – Méthode 1 : Visualisation
Code :
frame.plot.scatter(x = 'Ages',y = 'Sells');
Ce que l’on obtient :

Encore une fois, nous constatons que notre nuage de points est linéairement dispersé dans notre espace plan. On peut également noter que certains points dans le plan sont beaucoup plus éloignés que d’autres. Cela peut être considéré comme du bruit par rapport à la vérité. C’est comme un signal audio parasité par un bruit de fond indésirable.
Méthode 2 : Matrice Corrélation
Code :
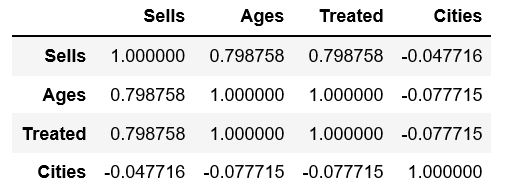
frame[['Sells','Ages','Treated']].corr()
Ce que l’on obtient :

(Matrice de corrélation )
Toutes les valeurs de cette matrice sont positives et très éloignées de zéro. Elles sont donc très fortement corrélées les unes aux autres. Le coefficient de corrélation varie de 0.7987 à 1.0.
Et la ville dans tout ça ?
Nous savons à présent que les colonnes Treated et Ages agissent fortement sur les ventes. Maintenant, nous souhaitons savoir si le lieu de vente agit également sur les ventes ?
Code :
On rajoute la colonne Cities dans le code précédent :
frame[['Sells','Ages','Treated','Cities']].corr()
Ce que l’on obtient :
On observe que le coefficient de corrélation entre la ville et les autres variables est quasi nul. Logiquement, la méthode géométrique (nuage de points) devrait confirmer cette assertion. Nous allons reprendre le code Python de visualisation des ventes et y intégrer la notion de ville. Chaque point dans le plan sera coloré en fonction de sa ville.
CITIES = {0:"Wakanda", 1:"Genosha", 2:"Krakoa"}
COLORS = {0:"#FF0000", 1:"#5CFF33", 2:"#334EFF"}
plotColor = [ COLORS[x] for x in frame.Cities]
frame.plot.scatter(x='Ages', y='Sells', c=plotColor)

Le phénomène de croissance des ventes par rapport à l’âge et aux traitements se fait indépendamment des villes. Cela confirme les résultats obtenus précédemment. Vous pouvez vous entraîner à le faire avec la température pour estimer si ce paramètre est utile dans le modèle.
Ainsi, après avoir déterminé que finalement certaines des variables explicatives variaient linéairement entre elles d’une part, et donc sur ma variable d’intérêt d’autre part, nous savons ce qu’il nous reste à faire : déterminer cette droite autour de laquelle gravite l’ensemble des points du plan.
Le Machine Learning
La première phase d’analyse nous a permis de déterminer quel type d’algorithme de Machine Learning appliquer pour comprendre nos données et d’en prédire la valeur au cours de différentes expériences. Examinons à présent les résultats d’une régression linéaire sur notre dataset :
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
#if you are using Azure ML notebook
#otherwise read your csv file as shown below
def ReadFromAzure():
from azureml import Workspace
ws = Workspace()
ds = ws.datasets['Sells_2025_2026.csv']
frame = ds.to_dataframe()
frame.rename(columns = {'Unnamed: 0':'Date'},inplace=True)
frame.set_index('Date', inplace = True)
return frame
def ReadFromLocal(filename="YOUR FILE LOCATION"):
frame = pd.read_csv(filename,index_col=0)
#adapt according to your situation
frame = ReadFromAzure()
#select features to use for prediction
X = frame[['Ages','Treated','Temp','Cities']].as_matrix()
Y = frame.Sells.as_matrix().reshape(len(frame.Ages), 1)
#split data between train and test set using builtin function
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.33 , random_state=42)
#create linear regression class
#and fit it using train data
model = LinearRegression()
model = model.fit(X_train, Y_train)
#Evaluate the model
score = model.score(X_test,Y_test)
scores = cross_val_score(model, X_test, Y_test, cv=10)
print("Coefficients: {0}".format(model.coef_))
print("Intercept: {0}".format(model.intercept_))
print("Cross validation score: {:.2f}%".format(score * 100))
print("K-folds Cross validation score mean : {:.2f}%".format(scores.mean() * 100))
Le code est assez simple. Au départ, on charge le dataset selon qu’on soit sur Azure ou en local, on sélectionne les 4 variables explicatives (Xi) et une variable d’intérêt (Yi) puis on sépare notre jeu de données en deux sous-ensembles pour obtenir respectivement la phase d’apprentissage et la phase de tests (~33%). On entraîne ensuite notre modèle et on effectue les deux tests de validation que je vous ai présentés dans l’article précédent.
Si on exécute ce code, on obtient comme résultat :
- Coefficients : [[ 0.01778888, 0.00019128, 0.00154601, 0.0124099 ]]
- Intercept : [150.81517953]
- Cross validation score : 68.81%
- K-folds Cross validation score mean : 63.60%
Interprétation des résultats
Les premiers résultats sont plutôt bons, les deux méthodes de validation ont donné un coefficient de détermination qui exprime positivement la variabilité entre les données apprises et les données prédites. Pour faire simple, notre modèle prédictif est fiable à 69% sur les 33% de données qui lui ont été retirées et même lorsque l’on effectue une sélection aléatoire de 10 groupes et qu’on les teste les uns à la suite des autres, on obtient en moyenne environ 64%. Ce modèle peut être encore amélioré, nous verrons comment dans le prochain chapitre.
La pente et le biais de notre fonction sont donc :
a = model.coef_ # [[0.01778888, 0.00019128, 0.00154601, 0.0124099]] b = model.intercept_ #[150.81517953]
Vérification des résultats
Testons notre modèle en lui demandant de prédire l’ensemble des ventes à partir des colonnes Âges et Treated modèle.
Code :
Rajouter les lignes de code suivantes dans votre notebook ou éditeur :
predictions = model.predict(X)
plt.scatter(x = frame.Ages,y=frame.Sells, c = 'pink')
plt.plot(frame.Ages,predictions,c = 'blue', linewidth=3.0)
plt.xlabel("Ages")
plt.ylabel("Sells")
plt.legend(handles=[mpatches.Patch(color='pink',label ='Real value'), mpatches.Patch(color='blue',label ='Prediction')])
plt.show()
Ce que l’on obtient :
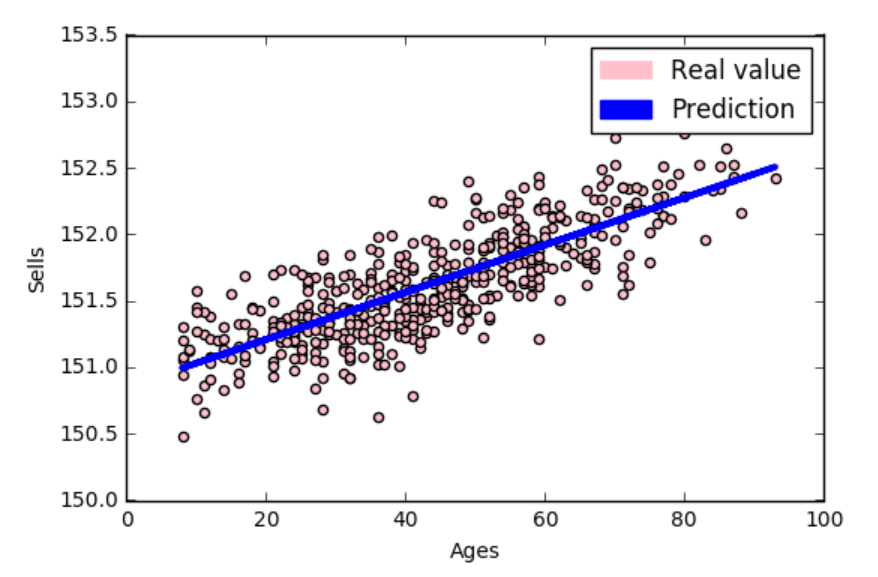
Notre agent se débrouille plutôt pas mal. La droite qu’il a trouvé représente assez bien les données et surtout n’apprend pas du bruit.
Bonus :
Pour ceux qui sont réfractaires aux codes ou qui veulent aller très vite, vous pouvez recréer ce modèle à l’aide de l’outil de visualisation dans Azure ML Studio. Créez une nouvelle expérience et utiliser le dataset que vous avez importé précédemment :

Ce qu’il faut retenir :
Pour vous :
- L’analyse exploratoire des données est très importante pour observer globalement vos données.
- La matrice de corrélation permet d’ignorer les variables muettes et aide à sélectionner un modèle prédictif.
- La validation croisée permet de quantifier la véracité du modèle.
- L’algorithme est important mais la compréhension du contexte l’est encore plus.
Pour John Doe :
- L’âge du consommateur influe fortement sur la probabilité d’avoir été sous traitement.
- L’âge du consommateur agit également sur le montant des ventes.
- Le lieu de vente n’a aucune influence sur les ventes.
Conclusion
Au terme de cet article plutôt dense en informations, nous avons mieux compris nos données grâce à la visualisation d’une part et à la corrélation d’autre part. Ensuite, nous avons appliqué une régression linéaire pour déterminer la fonction de distribution des ventes par rapport à l’âge du consommateur, au fait qu’il ait été sous traitement ou pas, à la température du jour et enfin à sa ville d’appartenance.
Dans le prochain article, nous allons nous attaquer au second jeu de données et essayer d’autres algorithmes pour confronter les modèles.






