

Comment RAJA Group a construit une plateforme data unifiée avec Microsoft Fabric – et comment Cellenza a contribué à écrire...
1 décembre 2022
Implémentation de la fonction Upsert/Merge avec les Azure Synapse et Data Factory Dataflows
Dans cet article, nous vous proposons de voir comment implémenter la fonction Upsert/Merge à l’aide de Mapping Data Flows disponibles dans Azure Synapse Analytics (ou Azure Data Factory) et des fichiers au format Delta lake. Il couvre l’ensemble des étapes de manière détaillée et présente les avantages de notre approche. Au-delà de l’aspect technique, nous espérons aussi vous convaincre des bénéfices que Data Flow peut apporter à vos projets analytics.

Icone d’Azure mapping data flow que nous appellerons simplement Data Flow pour la suite de cet article
Upsert : insertion d’enregistrements dans une table
Lorsque l’on souhaite insérer ou mettre à jour des enregistrements dans une table, l’upsert (concaténation d’update et insert) se montre particulièrement efficace. Cette opération est notamment incontournable pour la gestion des Slow Changing Dimensions (SCD de type 1 ou 2).

Exemple de SCD de type 1 : on tracke le dernier changement sur une table Products (ici date du 15/11/2022)
Notre problématique dans cet article est d’implémenter cette opération à partir des data flows Azure Synapse et à l’aide de tables Delta.
Data Flow pour vos flux ETL via une interface utilisateur
Les data flows sont un type d’activités appelées par des pipelines Synapse (ou Data Factory). Ils permettent d’appliquer des traitements de données de manière visuelle, le tout monitoré automatiquement par Azure. C’est un moyen de transformer des données avec Spark mais en low-code. Pour plus d’informations sur Data Flow et les nombreux avantages qu’il apporte, nous vous invitons à consulter la documentation de Microsoft.
Delta tables
Delta Lake est un format open source proposé par la société Databricks. Ce format permet notamment de garantir des transactions ACID et de tracer l’ensemble des changements faits par les utilisateurs. Delta Lake permet de faire des opérations d’insert, d’update mais également de delete : par ces caractéristiques, il permet les opérations d’upsert. Si vous souhaitez être pleinement convaincu par l’intérêt des Deltas tables pour vos projets data, je vous recommande vivement de lire ces articles :
S’agissant d’un projet open source, il existe un connecteur Delta Lake pour Mapping Data Flow. Ce connecteur peut être utilisé comme source ou récepteur.
Vous l’aurez compris, le format Delta Lake tables est idéal dans une architecture Lakehouse.
Le scénario
Nous souhaitons alimenter des tables Delta à partir de fichiers parquets. La solution doit permettre de suivre la création et la dernière modification des données. Pour cela, nous ajoutons deux champs :
- « Date de création » : alimenté avec le timestamp lors de la première ingestion
- « Date de modification » : mis à jour avec le timestamp lors de la modification
Nous allons prendre l’exemple d’un flux Products. Son schéma est le suivant :
- ProductCode : chaine de caractères représentant le code du produit
- RegionCode : chaine de caractères représentant le code de la région
- ProductName : chaine de caractères représentant le nom du produit
- ProductColor : chaine de caractères représentant la couleur du produit
La clé permettant d’identifier un produit est constituée de son code produit (ProductCode) et du code de la région (RegionCode).
Le flux initial est comme ci-dessous :

Table Products en entrée
Une fois traitée par Data Flow, la table sera créée sur le format suivant :

Table Products après ajout des champs techniques

Table Products après modification et avec les champs techniques. Une nouvelle ligne est insérée (en vert) et modification d’un enregistrement (en orange)
Opération d’Upsert avec Dataflow
Prérequis : initialisation des tables
Lors du premier chargement, puisque la table Delta n’a pas encore été créée, une étape d’initialisation est nécessaire.

Dataflow d’initialisation des tables

Paramétrage du derived column
Les champs techniques sont ajoutés via l’étape « derived columns » :
- CreatedDateTime : horodatage lors du traitement
- ModifiedDateTime : initialisation à « null »
Etape 1 : Paramétrage des sources
Voyons maintenant comment cette opération est mise en pratique avec Dataflow :
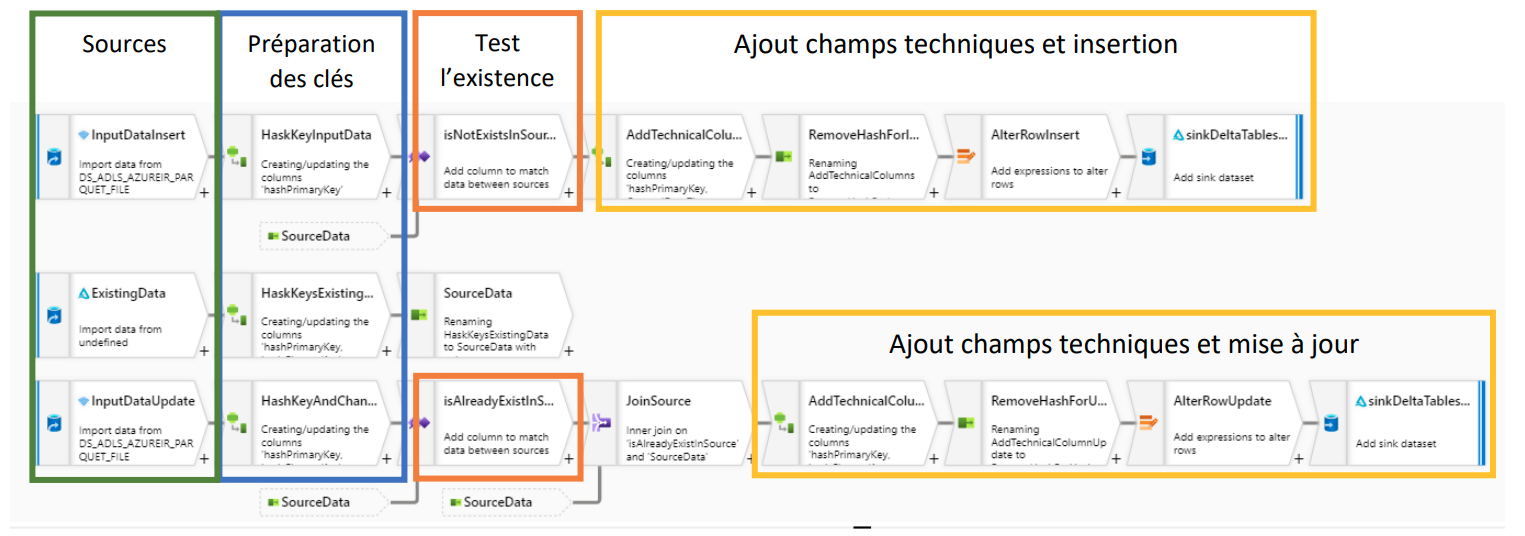
Les traitements peuvent être regroupés en étapes similaires
- Sources
- Préparation des clés
- Test de l’existence des lignes
- Ajout des champs techniques et insertion ou mise à jour
Etape 1 : les sources
Immédiatement, trois flux entrants et deux flux cibles ressortent de ce diagramme (et confirment que Data Flow est bien un outil très visuel).
Ces 3 flux initialisés par 3 sources se décomposent ainsi :
Il y a deux sources pour la data en entrée : les Inputs (données entrantes) :
- La donnée à insérer, qui est nouvelle et par conséquent absente du jeu de données existant. Dans le schéma, c’est la source intitulée « InputDataInsert ».
- La donnée modifiée et donc à mettre à jour dans le jeu de données existant : les « InputDataUpdate ».
Une source pour la donnée existante :
- La source « ExistingData » contient les données préalablement intégrées et transformées au format Delta.
Deux sources cibles : les données à insérer et à updater.
A noter : la donnée à modifier et à insérer provient du même dataset, dans notre cas un fichier parquet. La donnée existante est au format Delta Lake table.
Pour les paramétrages des sources Input et Update, il est recommandé d’utiliser un dataset aussi générique que possible.
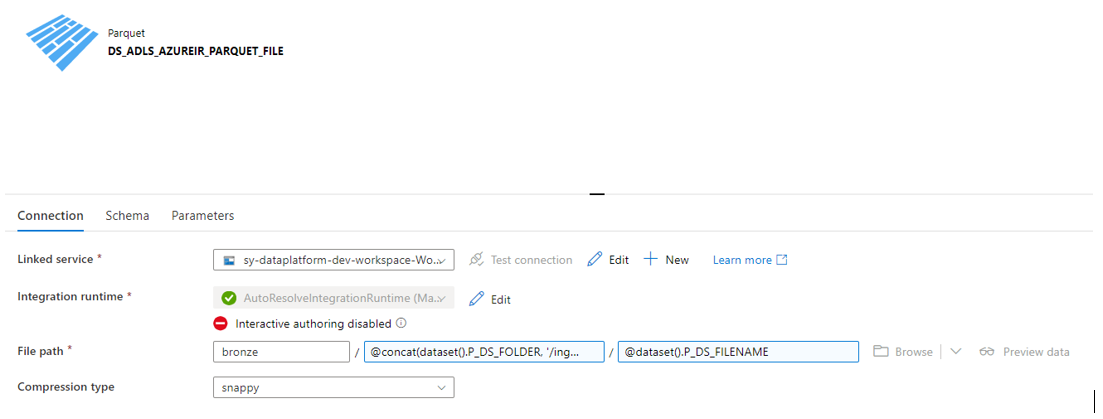
Dataset des fichiers parquets
Sélectionner également l’option « Allow schema drift » :

Settings de la source InpuDataInsert
Pour la source ExistingData, afin d’utiliser les tables Delta, sélectionner le type de source « Inline » :
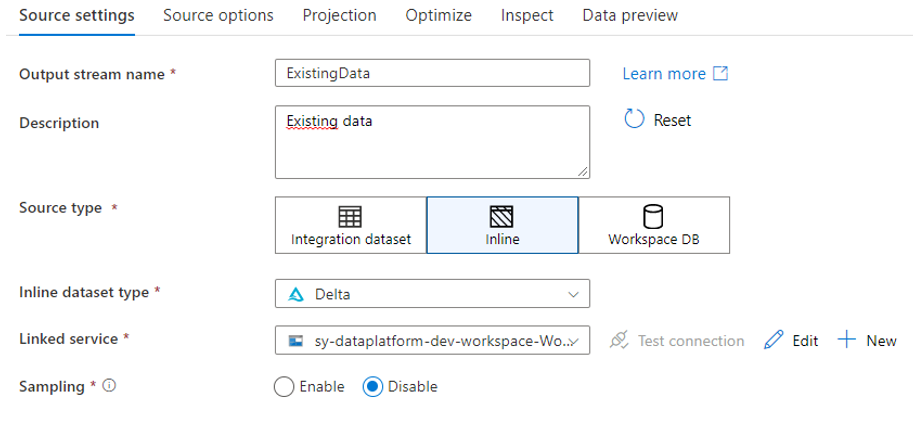
Settings de la source ExistingData
Etape 2 ajout de la clé de hashage

Etapes d’ajout des clés de hashage
Le principe : une liste de colonne est fournie à une fonction de hashage (ici la fonction « md5 »). Cette fonction va récupérer en inputs les valeurs de ces champs pour une ligne et va nous renvoyer une valeur unique.
- La valeur renvoyée est unique à cette combinaison de valeurs.
- La valeur renvoyée est toujours identique si la combinaison de valeurs est la même.
La colonne qui contient la valeur de hashage est ainsi ajoutée aux 3 sources.
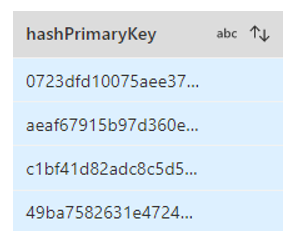
Exemple de valeurs renvoyées par la fonction de hashage
En pratique : nous ajoutons une étape de transformation « Derived column » à chacune de nos sources afin de les enrichir de deux nouvelles colonnes qui vont contenir les valeurs de hashage :

La colonne hashPrimaryKey renvoie une valeur seulement pour les colonnes clés de notre enregistrement. La liste des colonnes clés est donnée par le paramètre « $P_DF_PRIMARY_KEY ».
La colonne hashChangeKey renvoie une valeur pour les colonnes trackées, celles dont on souhaite suivre les changements. La liste des colonnes à suivre est donnée par le paramètre « $P_DF_CHANGE_KEY ».
Notons que la fonction « byNames » renvoie les valeurs contenues par les colonnes données en paramètres $P_DF_PRIMARY_KEY et $P_DF_CHANGE_KEY.
Md5 va finalement calculer une valeur de hashage pour chaque ligne.

Les valeurs de hashage obtenues après l’étape derived column
Etape 3 : identification des enregistrements à insérer et à mettre à jour par comparaison des clés de hashage
Après avoir créé ces champs techniques, nous allons les comparer. Par conséquent, les colonnes de hashage des données à insérer et à modifier sont mises en balance par rapport à la source existante. Deux flux de traitements différents sont appliqués selon que les données sont à modifier ou à insérer :
- Flux pour les données à Insérer:
InputDataInsert est comparé à « ExistingData » dans l’étape « isNotExistsInSource ». Les clés qui existent dans les deux jeux de données sont des données à modifier et non à insérer. Elles doivent donc être exclues de ces traitements.
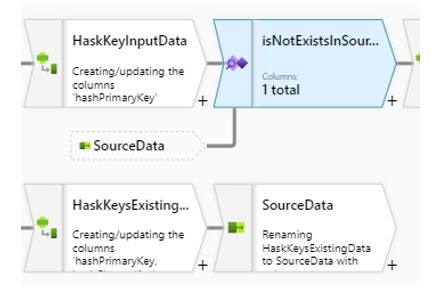
Etape de comparaison entre « InputDataInsert » et « ExistingData »
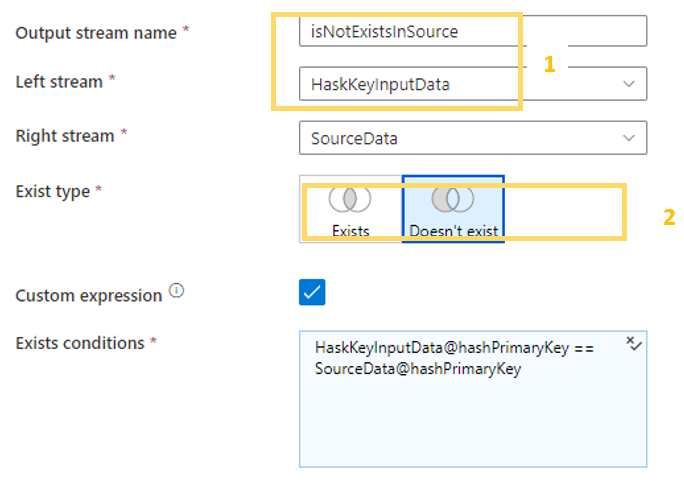
Paramétrage de existsHashKey
- Le choix du Exist type en « doesn’t exist » est l’équivalent de la clause « Where not exists » en SQL.
- Le paramètre « Custom expression » doit être sélectionné. Les lignes de HashKeyInputData qui existent dans SourceData sont exclues.
- Flux pour les données à modifier :
InputDataUpdatet est comparé à « ExistingData » dans l’étape « existHashKeyUpdate », les clés qui existent dans les deux jeux de données sont des données à modifier et doivent par conséquent être conservées.

- Le choix du Exist type en « Exists » est l’équivalent de la clause « Where exists » en SQL.
- Le paramètre « Custom expression » doit être sélectionné. Les lignes de InputDataInsert qui existent dans ExistingData sont exclues.
Ainsi, dans notre scénario :
Note : le mode debug et l’onglet data preview disponibles dans Data Flow permettent de contrôler les développements sur un échantillon de données. L’ensemble des captures d’écrans qui suit provient de ce mode.
Les données à insérer :

Ligne à insérer après l’étape d’identification (visible dans l’étape isNotExistsInSource)
Les données à updater :

Données à updater après identification (visibles dans l’étape isAlreadyExistInSource)
Etape 4 : Préparation de la structure des données à insérer

Etapes d’ajout, de suppression des colonnes et de marquage des données
Les enregistrements à insérer doivent avoir le même schéma que la table cible : ajout des colonnes techniques et suppression des champs des hashage.
Ajout des champs techniques :
Une fois que les données à insérer ont été identifiées et isolées, les champs « Date de création » et « Date de modification » peuvent leur être ajoutés via une étape derived columns :

- CreatedDateTime : horodatage lors du traitement
- ModifiedDateTime : initialisation à « null »
Chacun des champs est typé comme attendu par la table d’arrivée.
Suppression des champs de hashage :
Les colonnes de hashage utilisées pour l’identification des données à insérer peuvent être supprimées via une étape de « select » :

Un rule-based mapping est utilisé pour filtrer dynamiquement les colonnes

Seules les colonnes de hashages sont filtrées
Une fois que les nouvelles données ont la bonne structure, l’étape « alter row » va permettre d’indiquer la politique d’insertion de ces données dans la cible. Ainsi, chacun des enregistrements va être marqué comme « insert » afin de les distinguer d’update.

Symbole + qui marque les données à insérer

Les enregistrements à insérer sont marqués comme à « insérer »
Finalement, les données sont insérées dans la table Delta cible. Il faut veiller à ne cocher que le paramètre « allow insert » afin de ne faire que de l’insert dans ce sink (source cible).
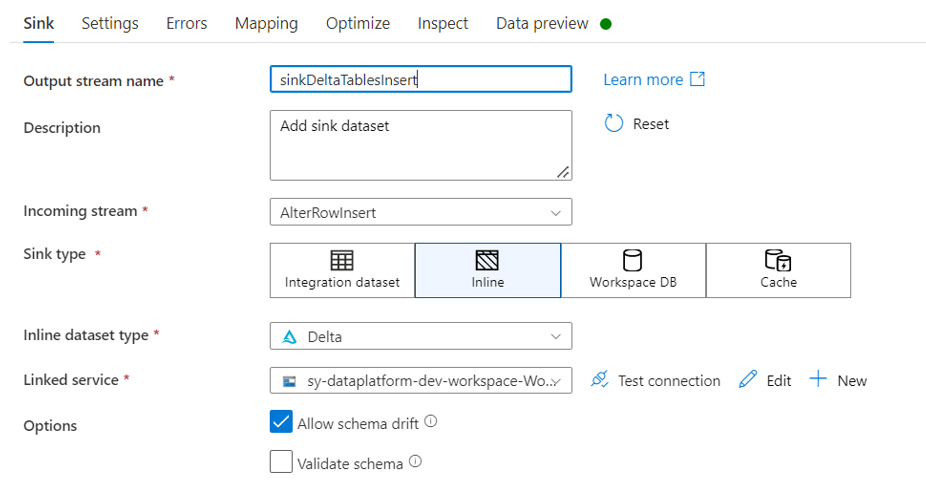
Sink de type Inline et dataset de type delta
Etape 5 : Mise à jour des champs pour InputDataUpdate et modification des champs techniques
En parallèle des étapes d’insertion, un second flux va permettre le traitement des données à updater.
Les champs techniques doivent-être ajoutés dans le dataset d’update :
- CreatedDateTime : Récupéré depuis le dataset existant
- ModifiedDateTime : horodatage lors du traitement
Afin de récupérer la date de la première insertion depuis le dataset existant, un inner join sur la hash primary key est effectué.

Paramétrage du inner join pour récupérer la CreatedDate
Les autres champs techniques sont alimentés via une étape derived column :

Suppression des champs de hashage :
Les colonnes de hashage utilisées pour l’identification des données à insérer peuvent être supprimées via une étape de « select » :

A l’instar du flux d’insertion, un rule-based mapping est utilisé pour filtrer dynamiquement les colonnes
Également dans le flux d’update, une fois que les nouvelles données ont la bonne structure, l’étape « alter row » va permettre d’indiquer la politique d’insertion de ces données dans la cible. Ici les enregistrements vont être marqués comme « update ».

Les enregistrements à insérer sont marqués comme à « Updater »
Update de la source cible/récepteur :
Veillez à bien sélectionner « Allow update », pour ne faire que des opérations d’update.
P_DF_PRIMARYKEY : indique la liste de colonnes nécessaires pour l’update

⚠️ Important : une fois l’ensemble des étapes réalisées et avant de valider le développement, il peut être pertinent de faire un nettoyage des différentes étapes (par exemple pour enlever les projections de schéma).
Schéma de InputDataInsert projeté qui doit être nettoyé en cliquant sur le bouton « reset schema »
Pour aller plus loin
Les opérations de merge sont un élément essentiel des solutions analytiques. Bien qu’il existe d’autres possibilités d’implémentation, celle proposée par cet article via l’utilisation de Mapping Data Flow (disponible via Synapse Pipeline ou Data Factory) et de tables Delta offre l’avantage d’être générique, low-code et facilement réutilisable. La solution proposée peut également être étendue pour prendre en compte les SCD de type 2 ou la suppression des enregistrements concernés. Nous sommes pleinement convaincus qu’elle pourra être utile à vos projets data !





