

Le Machine Learning automatisé (ou AutoML) est une méthode d’optimisation des paramètres pour vos modèles de Machine Learning (ML). Il...
20 février 2024
Read this post in English
Comment créer une voix personnalisée ? Retour d’expérience d’un expert

Custom Neural Voice (CNV) est un composant de la solution Azure Cognitive Services qui vous permet de générer une voix synthétique personnalisée pour vos applications. Il s’agit d’un outil de synthèse vocale qui vous aide à créer une voix très naturelle pour votre marque ou vos personnages en utilisant des échantillons de voix humaine comme matériau d’entraînement.
Je viens de finaliser un projet dans lequel j’ai créé une voix personnalisée. À cette occasion, j’ai découvert certaines fonctionnalités et rencontré des problèmes inattendus qui ne sont pas abordés dans la documentation officielle. C’est pourquoi je souhaite partager avec vous dans cet article quelques conseils pratiques.
Si l’aspect théorique est largement couvert par les ressources existantes, les recommandations de cette publication sont principalement tirées de ma propre expérience. J’espère qu’elles vous seront utiles.
C’est parti !
Enregistrement audio
Tout d’abord, il est essentiel de créer un jeu d’apprentissage équilibré. Notez qu’il est plus important de veiller à disposer de la bonne combinaison de types de phrases que de faire en sorte que le jeu d’entraînement corresponde exactement au domaine cible. Un dataset efficace comprend généralement les éléments suivants :
- Phrases déclaratives : 70-80 %
- Questions : 10-20 %, avec un nombre identique d’intonations montantes et descendantes (l’intonation montante est utilisée pour les questions de type oui/non, tandis que l’intonation descendante est fréquente dans les questions de type « qui, que, quoi »)
- Phrases exclamatives : 10-20 %
- Phrases/mots courts : 10 %
Vous pouvez utiliser ce guide pour générer votre dataset. Identifiez les phrases affirmatives par le code 00, les questions par le code 01 et les phrases exclamatives par le code 02.
Il est essentiel de comprendre que votre jeu d’entraînement ne doit pas nécessairement correspondre exactement au texte cible. Il est surtout très important de s’assurer que le jeu d’entraînement est aussi varié que possible. Par exemple, si vous prévoyez que l’artiste vocal devra prononcer des noms de villes uniques avec des prononciations peu courantes, comme Truchtersheim, Kingersheim ou Pfaffenhofen (qui sont de jolies villes alsaciennes), vous n’avez pas besoin de les inclure dans votre jeu d’entraînement. En revanche, vous pouvez prévoir de modifier votre langage SSML ultérieurement. Quelques exemples ne suffiront pas en effet à apprendre à votre modèle à prononcer certains mots correctement. Par ailleurs, vous risquez de perdre en performance si votre dataset ne comporte pas suffisamment de phrases exclamatives ou de phrases courtes.
Ensuite, il est très utile d’installer un écran dans la salle d’enregistrement. Si vous n’en avez pas, imprimez trois exemplaires de votre script : un pour vous, un pour l’artiste vocal et un pour l’ingénieur du son (à moins que ce ne soit vous). Le mieux est de créer un tableau Word avec trois colonnes : numéro, énoncé et statut (pour le suivi des phrases terminées). Pour parcourir plus facilement le script, vous pouvez alterner entre lignes ou colonnes ombrées dans le tableau.
Enfin, je recommande d’enregistrer tous les énoncés en une seule fois en veillant à faire des pauses régulièrement, plutôt que de sauvegarder des enregistrements partiels. Sur la base de mon expérience, je peux affirmer que la sauvegarde de plusieurs segments, entre 0 et 100, entre 100 et 200, etc., par exemple, n’améliore pas les performances. En réalité, cela prolonge la durée de la session d’enregistrement, ce qui peut poser problème si l’artiste vocal a un emploi du temps chargé. En cas d’erreurs, ne les corrigez pas sur-le-champ. Notez plutôt l’horodatage et corrigez-les ultérieurement lors de la phase de prétraitement. Il est préférable d’effectuer une seule exportation volumineuse, de façon à pouvoir repérer plus facilement les problèmes liés à vos notes. Veillez à faire de longues pauses (au moins 3 secondes) entre chaque énoncé, ce qui facilitera le montage lors de la phase de traitement.
Logiciel de montage audio : Adobe Audition ou Audacity ?
Il existe plusieurs solutions, comme Adobe Audition ou Audacity.
Voici une comparaison des deux :
Objectif et public :
- Audacity :
- Programme de montage audio open source et gratuit.
- Idéal pour les débutants, les amateurs et tous ceux qui ont besoin d’effectuer des tâches de montage audio simples.
- Convient parfaitement aux créateurs de podcasts, aux musiciens et aux éducateurs disposant d’un budget limité.
- Adobe Audition :
- Station de travail audio professionnelle pour le mixage, la finition et le montage de précision.
- Destiné aux professionnels de la production audio, y compris les ingénieurs du son, les créateurs de podcasts et les monteurs vidéo.
- Avantageux pour les utilisateurs qui ont besoin de fonctionnalités avancées et d’une intégration avec d’autres applications Adobe Creative Cloud.
Interface utilisateur :
- Audacity :
- Interface simple et conviviale.
- Design éventuellement un peu dépassé pour certains.
- Présentation simple, facilitant la navigation pour les débutants.
- Adobe Audition :
- Interface moderne, élégante et personnalisable.
- Courbe d’apprentissage plus longue en raison de ses fonctionnalités de niveau professionnel.
- Espace de travail plus sophistiqué pouvant être adapté aux besoins de l’utilisateur.
Fonctionnalités :
- Audacity :
- Propose des outils de montage audio de base tels que couper, copier, coller et supprimer.
- Prend en charge l’audio multipiste et le traitement par lots.
- Propose une gamme d’effets et peut être complété par des plug-ins.
- Prend en charge de façon limitée les effets avancés et ne propose aucune prise en charge MIDI intégrée.
- Adobe Audition :
- Comprend un ensemble complet d’outils avec des fonctions avancées de montage, de mixage et de restauration audio.
- Permet d’afficher plusieurs pistes, formes d’ondes et spectres.
- Propose de puissants outils de réduction de bruit et de nettoyage audio.
- S’intègre avec d’autres applications et services Adobe.
Qualité audio et formats de fichiers :
- Audacity :
- Permet de gérer l’audio jusqu’à 32 bits/384 kHz.
- Prend en charge un large éventail de formats de fichiers, notamment WAV, AIFF, MP3 et OGG.
- Adobe Audition :
- Prend également en charge l’audio haute résolution jusqu’à 32 bits/192 kHz.
- Peut gérer davantage de formats de fichiers, et offre une meilleure compatibilité des formats pour une utilisation professionnelle.
Prix :
- Audacity :
- Téléchargement et utilisation entièrement gratuits.
- Aucun abonnement ou achat nécessaire.
- Adobe Audition :
- Disponible à partir d’un modèle d’abonnement dans le cadre du service Adobe Creative Cloud.
- Application de frais d’abonnement mensuels ou annuels.
- Essai gratuit, mais paiement requis pour poursuivre l’utilisation.
Assistance et ressources :
- Audacity :
- Logiciel open source bénéficiant d’un système d’assistance par la communauté.
- Possibilité pour les utilisateurs d’accéder à des forums, des manuels d’utilisation et des FAQ pour obtenir de l’aide.
- Adobe Audition :
- Assistance professionnelle fournie par Adobe.
- Accès à une multitude de tutoriels et de guides, ainsi qu’à une équipe d’assistance dédiée.
Audacity ou Adobe Audition ? Ma recommandation
Je recommande Audacity, mais pas uniquement parce qu’il est gratuit alors que l’autre solution est payante. Audacity propose en effet un ensemble de fonctions plus rationalisées, ce qui répond parfaitement à nos besoins puisque nous voulons uniquement avoir la possibilité de sélectionner un segment, de l’exporter et de le découper. La simplicité est souvent la clé du succès. Par ailleurs, la navigation parmi les pistes est plus simple dans Audacity, et il est possible de masquer les boîtes à outils dont vous n’avez pas besoin.
Le menu Fichier d’Audacity comprend également des options permettant de créer, d’ouvrir et d’enregistrer des projets Audacity, ainsi que d’importer et d’exporter des fichiers audio. Par exemple, la fonction d’exportation n’a pas de raccourci par défaut, ce qui vous permet d’en configurer un pour y avoir accès rapidement et accélérer ainsi considérablement votre workflow. J’ai utilisé aussi bien Adobe Audition qu’Audacity. Résultat : il m’a fallu 2 jours ouvrables pour réaliser toutes mes tâches avec Audacity contre 4 jours avec Adobe Audition alors que le volume de données était identique.
Détails du prix d’un projet d’enregistrement vocal
Voici les détails de mon projet :
- Type de modèle : Neural V5.2022.05
- Version du moteur : 2023.01.16.0
- Nombre d’heures de formation : 30,48
- Taille des données : 440 énoncés
- Prix : 1 584,27 $
Le prix peut varier en fonction de la version du moteur et du nombre d’heures de formation, mais cela vous donne une première indication. Après avoir terminé l’entraînement de votre modèle, vous pouvez mettre à niveau votre moteur sans frais supplémentaires. Au moment de la rédaction de cet article, la version la plus récente du moteur disponible était la version 2024.01.02.0.
Formulaire d’admission
Il est important de noter que vous devez tout d’abord remplir le formulaire d’admission pour pouvoir bénéficier d’un accès. Avant de soumettre toutes les informations nécessaires au projet, il est conseillé de consulter la norme d’intelligence artificielle responsable de Microsoft. Cette ressource vous aidera à affiner la description et le scénario de votre projet afin de respecter les pratiques responsables en matière d’intelligence artificielle.
Préparation audio
La procédure est relativement simple et peut être détaillée de la façon suivante :
- Commencez par créer un document de type bloc-notes qui répertorie tous les énoncés, ainsi que les identifiants correspondants.
- Utilisez systématiquement cette liste en sélectionnant chaque énoncé un par un. Exportez l’énoncé, puis enregistrez le fichier correspondant en utilisant son identifiant unique comme nom de fichier. Une fois le fichier enregistré, supprimez l’énoncé du bloc-notes pour suivre votre progression.
- Avant de commencer, déterminez la taille idéale des fichiers des énoncés pour garantir une certaine cohérence.
- Utilisez le même niveau de zoom tout au long de votre travail. Une fois que vous avez commencé, évitez d’effectuer des zooms avant ou arrière. Cela vous aidera à vous habituer à la chronologie. Vous pourrez ainsi ajouter plus facilement et plus précisément les 100 à 200 millisecondes de silence nécessaires après chaque énoncé.
Voici à quoi ressemble un jeu d’entraînement équilibré :
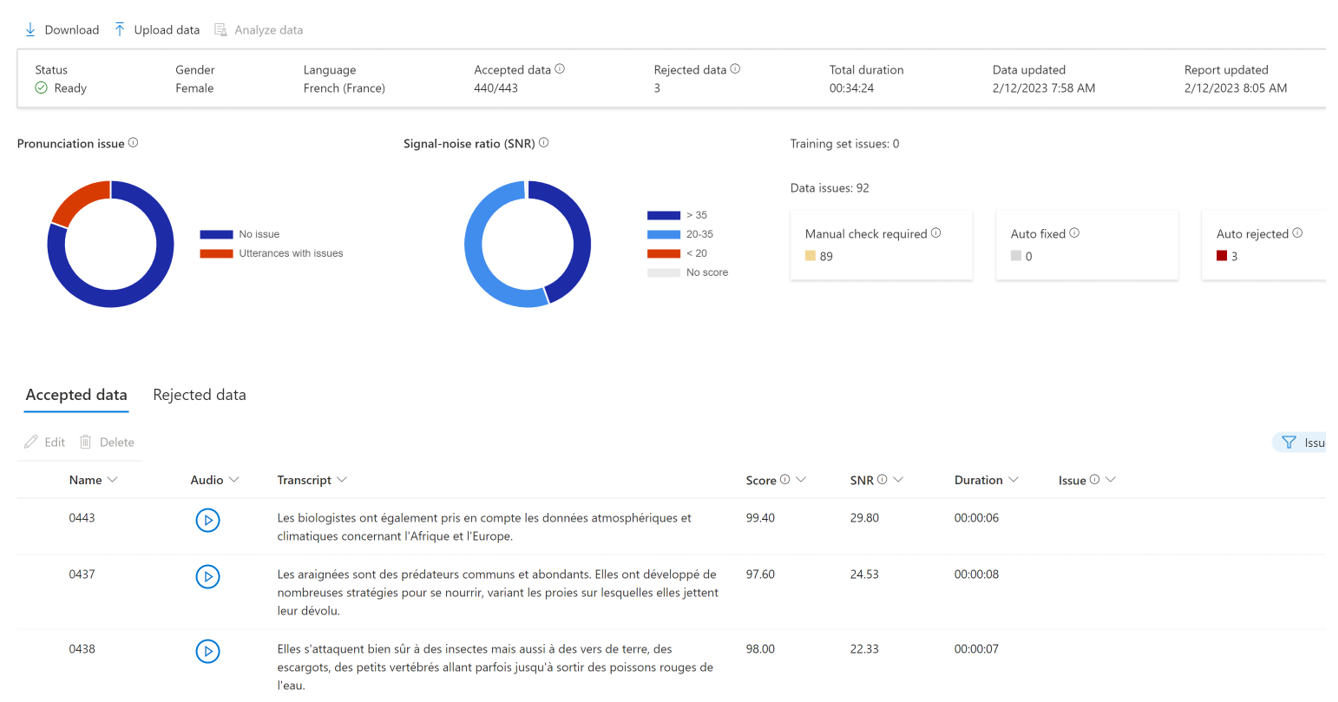
Comme vous le voyez, malgré certaines difficultés techniques, le studio est en mesure de corriger tous les énoncés problématiques. Un score de qualité est attribué à chaque énoncé, ce qui permet de disposer d’un précieux indicateur pour affiner le processus d’enregistrement et évaluer l’intégrité globale des données.
Interruption automatique
La maintenance des points de terminaison peut s’avérer coûteuse, c’est pourquoi certaines entreprises font le choix de ne faire fonctionner les leurs que pendant les heures de bureau. Au lieu de gérer ce processus manuellement, il peut être plus efficace de l’automatiser. Dans mon projet initial, j’ai envisagé de mettre en place une tâche Power Automate pour activer le bouton d’interruption. Cependant, j’ai découvert qu’il existait désormais une fonction d’interruption/de reprise accessible depuis l’API REST. Par exemple, vous pouvez configurer une fonction Azure programmable et capable de faire au moins 30 % d’économies. Sachez toutefois que s’il est possible d’intégrer des points de terminaison vocaux personnalisés dans vos réseaux virtuels, l’API conçue pour l’interruption/la reprise des modèles vocaux ne prend actuellement pas en charge les points de terminaison privés.
Comparaison avec Azure Personal Voice
Vous connaissez peut-être déjà Azure Personal Voice, une fonction de pointe qui permet de reproduire votre voix ou celle des utilisateurs de votre application en quelques secondes seulement grâce à l’IA. En fournissant un échantillon vocal d’une minute seulement en tant que message audio, vous pouvez exploiter cette technologie pour générer une voix dans l’une des plus de 90 langues prises en charge, tout en couvrant une centaine de paramètres régionaux.
Cette approche soulève toutefois une question : pourquoi dans ce cas choisir Azure Custom Neural Voice ? Bien qu’il s’agisse de l’option la plus coûteuse, que son entraînement prenne plus de temps et qu’elle implique d’importants efforts, elle présente des avantages indéniables. Nous vous proposons ci-dessous une comparaison des deux services afin de mettre en évidence leurs avantages.
Personal Voice s’adresse aux entreprises qui souhaitent développer une application permettant à leurs utilisateurs de générer et d’utiliser leur propre voix dans l’application. Les cas d’utilisation sont limités et décrits dans une note de transparence. Selon les prévisions, plus de 1 000 voix personnelles devraient être prises en charge à l’avenir. Les données d’entraînement pour Personal Voice doivent respecter un code de conduite, et le processus d’entraînement ne nécessite qu’un échantillon de voix humaine d’une minute. Le processus d’entraînement est rapide, puisqu’il prend moins de cinq secondes, et la qualité vocale obtenue est décrite comme naturelle. Personal Voice prend également en charge des fonctions multilingues, avec une centaine de langues détectées automatiquement. Personal Voice est accessible à partir d’une démonstration disponible sur Speech Studio au moment de l’inscription, mais l’accès à l’API est limité aux clients éligibles avec des cas d’utilisation approuvés.
Quant à la solution Custom Neural Voice, elle est conçue pour des scénarios professionnels, tels que les voix de marques et de personnages utilisées par les chatbots ou lors de la lecture de contenu audio. Les cas d’utilisation sont également limités, comme l’indique la note de transparence. Contrairement à Personal Voice, Customer Neural Voice nécessite une quantité importante de données d’entraînement, ce qui implique d’avoir recours à un studio professionnel pour l’enregistrement. La solution a besoin de 300 à 2 000 énoncés, ce qui correspond environ à une durée de voix humaine comprise entre 30 minutes et 3 heures respectivement. Le temps d’entraînement est nettement plus long (entre 20 et 40 heures de calcul environ), mais la qualité de la voix est très naturelle. Professional Voice prend également en charge plusieurs langues, et nécessite la sélection de la fonctionnalité « Neural – cross lingual » pour entraîner un modèle qui parle une langue différente des données d’entraînement. Cependant, vous ne pouvez entraîner et déployer un modèle CNV Pro qu’une fois l’accès approuvé, ce qui dépend de critères d’éligibilité et d’utilisation. Pour y avoir accès, vous devez remplir un formulaire d’admission.
En résumé, Personal Voice offre un moyen simple et rapide de générer une voix naturelle à partir d’une seule minute de données vocales, ce qui en fait la solution idéale pour une utilisation personnelle par les entreprises au sein d’applications. Professional Voice, en revanche, est conçu pour des applications plus professionnelles, à usage plus large, nécessitant un dataset plus important et une durée d’entraînement plus longue, ce qui lui permet de proposer une qualité vocale très naturelle adaptée aux besoins vocaux de niveau professionnel.
Vous avez besoin d’aide pour vos projets d’intelligence artificielle ? Contactez-nous !





