

Comment RAJA Group a construit une plateforme data unifiée avec Microsoft Fabric – et comment Cellenza a contribué à écrire...
15 juin 2023
Read this post in English
Permettre l’accès aux données grâce à l’API REST Databricks SQL

Lors de la mise en place d’une nouvelle plateforme de données, l’architecture Lakehouse est généralement la plus utilisée, car elle permet de servir plusieurs cas d’usage :
- Machine Learning
- Business Intelligence
- Partage de la donnée

Databricks SQL permet d’exposer les données pour servir des outils de BI tels que Power BI dans un écosystème Microsoft. Il utilise un SQL warehouse, une sorte de cluster Spark optimisé pour des charges de travail analytiques.
Afin de ne pas avoir à dupliquer les données, et de permettre un accès aux données via des API REST, Databricks a sorti en public preview l’accès à des API REST pour Databricks SQL.
Ainsi, des applications sont capables, via des APIs de requêtage, d’interroger les données stockées dans le Data Lake en passant par l’intermédiaire de Databricks SQL, soit un endpoint warehouse comme illustré dans le schéma ci-dessous.
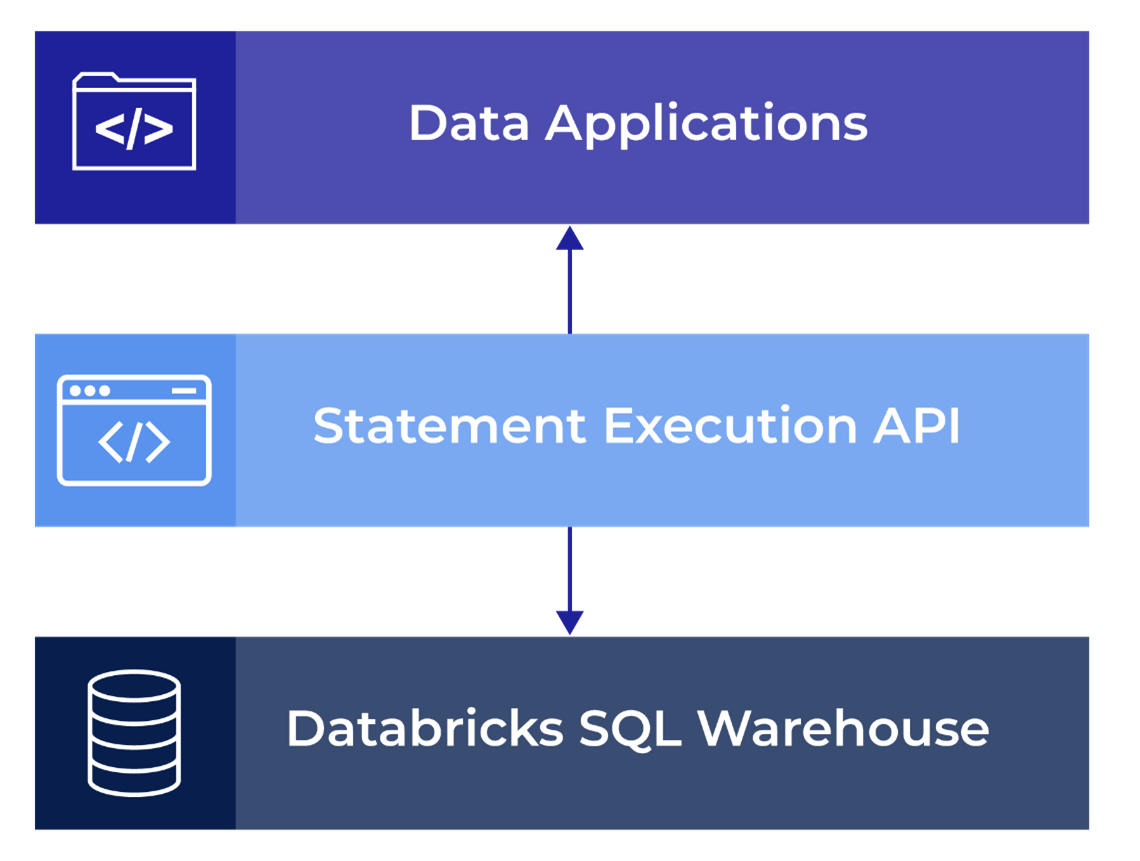
Actuellement, trois actions sont possibles à travers les APIs :
- Soumettre une requête SQL
- Annuler une requête
- Vérifier le statut d’une requête
Soumettre une requête SQL
La soumission d’une requête se fait via une action de POST avec le endpoint /sql/statements.

Pour cette action, il faut :
- L’URL du workspace Databricks cible
- L’authentification se fait via un Personal Access Token (PAT) (pour en savoir plus, nous vous invitons à consulter la documentation Microsoft « Manage storage access tokens »).
- La requête à exécuter
- L’identifiant du SQL warehouse

L’appel de l’API va avoir pour effet de démarrer le warehouse si ce n’est pas encore le cas.
En réponse à l’appel, il est fort probable de ne pas avoir le résultat de la requête, mais uniquement de récupérer l’identifiant de la requête « statement_id », ainsi que le statut de la requête à « PENDING ».
Exemple de réponse :
{
"statement_id": "01ed9a50-c9c9-178e-9be7-0ab52bc998b0",
"status": { "state": "PENDING" }
}
Annuler une requête
Lorsqu’une requête est en cours d’exécution, il est possible de l’annuler en utilisant l’identifiant de cette requête ainsi que le PAT. Il s’agit d’un POST sur le endpoint « /sql/statements/<statement_id>/cancel ».
Vérifier le statut d’une requête
Une fois que l’exécution d’une requête a été émise, vous pouvez consulter son statut avec une action GET sur le endpoint « /sql/statements/<statement_id> ».
Exemple de requête :
GET /api/2.0/sql/statements/01ed9a50-c9c9-178e-9be7-0ab52bc998b0 HTTP/1.1 Host: <your_HOST> Authorization: Bearer <your_access_token>
Exemple de réponse :

Lorsque la requête est en succès (cf. statut en 1), une propriété « schema » (cf. 2) présente le format du résultat de la requête en mentionnant le nombre de colonnes retournées par la requête ainsi que pour chaque colonne, le nom, le type, la position dans la réponse en commençant par zéro, et des informations complémentaires en fonction du type de données (précision, échelle, par exemple).
La propriété « result » contient des informations sur le résultat d’exécution de la requête. Parmi ces informations, la propriété « row_count » contient le nombre de lignes retournées par la requête et la propriété « data_array » est un tableau de tableaux. Chaque ligne de résultat est stockée dans un tableau à l’intérieur du tableau « data_array ».
Projet de démonstration
En partant du projet de churn disponible sur dbdemos.ai, nous avons créé un projet de démonstration.
Le but de ce projet de démonstration est d’exposer des données à travers un frontend.
L’architecture est donc la suivante :

Le backend permet de lancer l’exécution de la requête puis de vérifier le statut régulièrement jusqu’à la fin de la celle-ci.
Le frontend affiche 3 visuels :
- Un histogramme présentant l’évolution des revenus par mois
- Un camembert présentant les clients à risque en fonction du canal : mobile, application web, montre, etc.
- Un tableau présentant le nombre de commandes par pays et par plateforme

Nous nous sommes inspirés des dashboards présents dans le projet de churn. Par exemple pour le camembert :

Nous avons dû adapter les requêtes permettant d’afficher ces visuels. Databricks SQL permet d’obtenir des visuels en s’appuyant sur des résultats de requête :

Le frontend n’a pas les mêmes capacités. Il a donc fallu déporter la charge en exposant une requête qui « prémâche » le travail. Dans cet exemple, il a fallu écrire une requête qui calcule le pourcentage par canal.
Les expert.es Cellenza qui ont travaillé sur ce backend/frontend, ont également mis en place une fonctionnalité de rafraichissement des données par l’intermédiaire du bouton bleu situé à droite de chacun des titres des visuels :
![]()
Ainsi, la requête est de nouveau exécutée et le visuel mis à jour. Par ailleurs, il est possible de rafraîchir l’intégralité des visuels avec un bouton principal.
API REST SQL : l’essentiel à retenir
Les API REST SQL sont une solution intéressante pour exposer des données via un frontend, par exemple. En revanche, il y a quelques limitations comme le nombre d’accès concurrents à un SQL Warehouse, qui est limité à 10 requêtes simultanées. Pour cette limitation, il est possible de rajouter des clusters pour augmenter le nombre d’accès concurrents, mais cela a bien évidemment un coût.
De plus, le volume de données à interroger doit être raisonnable. Il ne s’agit pas de requêter des tables à fortes volumétries.
D’un point de vue authentification, il est, pour l’instant, possible d’utiliser uniquement un Personal Access Token (PAT). Il est donc impossible de transmettre l’identité de l’utilisateur pour, par exemple, appliquer des RLS (Row Level Security) ou CLS (Column Level Security).
Vous souhaitez être accompagné sur vos projets Data ? Contactez-nous !






