

Comment RAJA Group a construit une plateforme data unifiée avec Microsoft Fabric – et comment Cellenza a contribué à écrire...
3 novembre 2020
Power BI et Azure Databricks : une intégration simplifiée

Les Data Lakes ont une capacité unique d’ingestion de données structurées, semi-structurées et non structurées. Ils ont été depuis longtemps la technologie de choix pour ingérer d’importants volumes de données, en streaming ou batch, et débloquer des besoins de Data Science et de Machine Learning (ML) pour supporter l’innovation des métiers et répondre à leurs nouveaux besoins.
Bien que le Machine Learning est en passe de devenir indispensable à la compétitivité des entreprises, en permettant notamment de prédire des événements/comportements, le besoin d’analyse de l’existant reste primordial.
Ce besoin se traduit par une utilisation de la donnée plus classique, au travers d’outils d’analyse, de requêtes SQL et de Business Intelligence (BI).
Historiquement, cette capacité n’a pas été le fort des Data Lakes, que ce soit avec des technologies comme Hive, Impala ou Spark.
Plusieurs raisons peuvent expliquer cette situation :
- Le manque de capacités transactionnelles pour lancer les analyses (que se passe-t-il si le fichier lu est supprimé ?) ;
- Le manque de qualité dans les données (par exemple : un job insère une chaine de caractères au lieu d’un entier, rendant la table illisible) ;
- Le manque de fiabilité dans les endpoints JDBC (avec un SPOF sur le thrift serveur) ;
- Des lenteurs dans le connecteur JDBC qui stream les données trop lentement ;
- Une lenteur dans le moteur d’exécution exécuté sur la JVM ;
- De mauvaises stratégies de scheduling pour partager les ressources lors de requêtes concurrentes ;
- Un accès à la donnée ralenti, particulièrement avec le faible débit (throughput) des blob storages des cloud providers ;
- L’absence d’index sur les champs régulièrement requêtés ;
- Un challenges dû au format de stockage sous-jacent (trop de petits fichiers, mauvaises partitions, etc.) ;
- Etc.
Toutes ces problématiques peuvent rendre l’expérience utilisateur sur les outils de Business Intelligence (Tableau, PowerBI, Looker, Redash…) décevante.
C’est pourquoi de nombreuses entreprises ont eu le réflexe d’ajouter une couche de serving type Datawarehouse, mais cela complexifie fondamentalement les architectures :
- Les informations sont dupliquées et il est nécessaire de mettre en place des flux de synchronisation et des flux réseaux ;
- La sécurité doit également être dupliquée ;
- La donnée se retrouve verrouillée dans un format propriétaire ;
- La seule façon d’accéder à cette donnée est de passer par le Data Warehouse ;
- Les données commencent à naviguer entre le Data Warehouse (SQL/BI) et Data Lake (SQL, data processing, python, ML/AI features, streaming, semi/non structuré…), créant un workflow impossible à maintenir et synchroniser.
Un bon exemple de cela est une problématique RGPD : comment tracer un linéale propre pour qu’une donnée cliente soit supprimée de l’intégralité des systèmes, des données brutes jusqu’aux features des modèles de Machine Learning ?
La plateforme de Databricks permet de surmonter ces difficultés à travers une approche « Lake House » regroupant le meilleur du monde de la Data Lake et du Data Warehouse.
Pour simplifier l’intégration avec les outils BI, un connecteur Databricks natif sur PowerBI est maintenant disponible, et c’est ce que nous allons tester.
Connecter Databricks depuis Power BI
Jusqu’ici, pour se connecter à Databricks depuis Microsoft Power BI, on utilisait le connecteur générique de Spark :
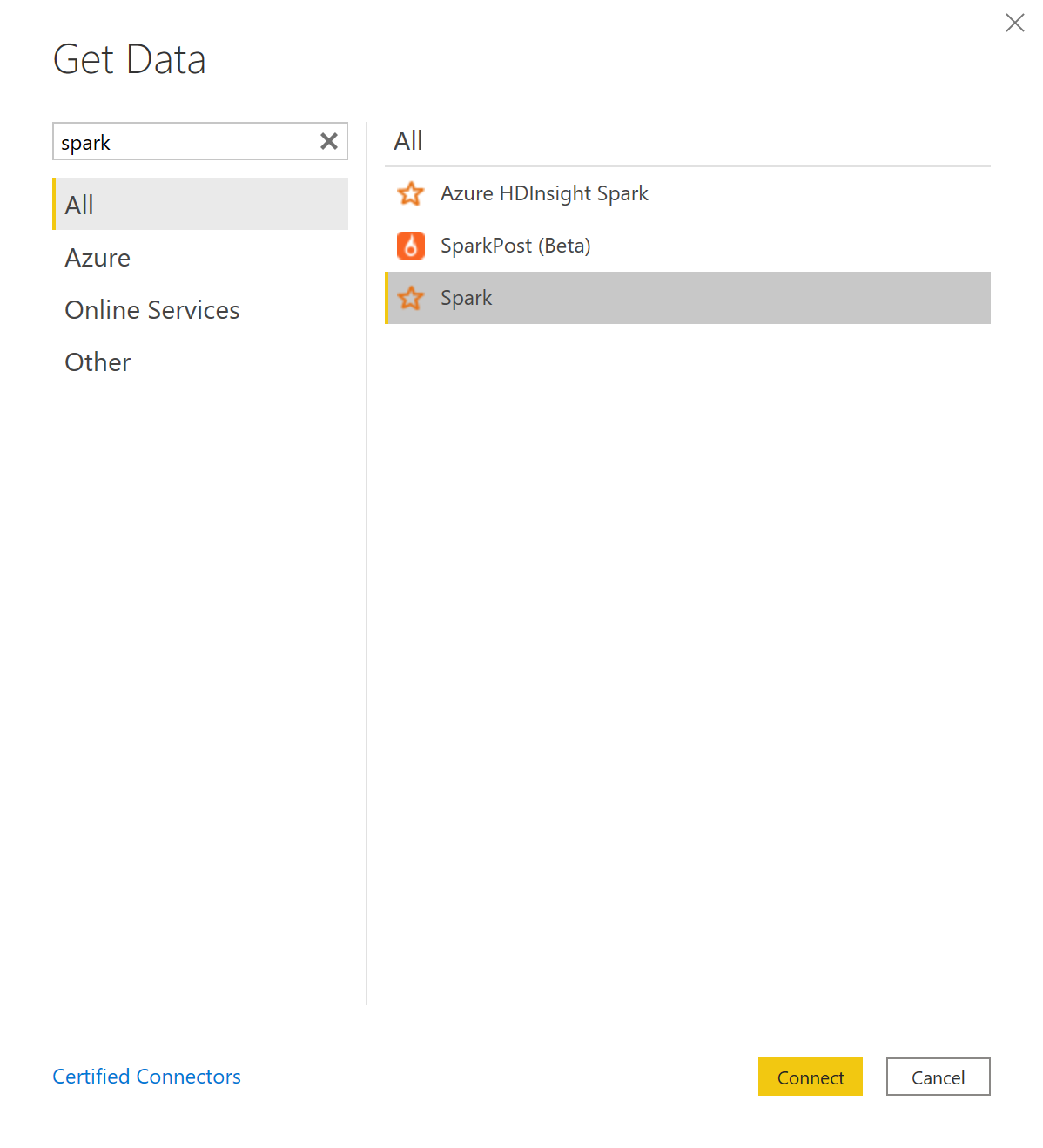
Depuis septembre 2020, le nouveau connecteur Databricks développé spécifiquement pour Power BI par Databricks et Microsoft est disponible en Public Preview :

Regardons de plus près les ajouts du nouveau connecteur par rapport à l’ancien.
Drivers
Le connecteur Spark utilise un driver ODBC développé par Simba. C’est un driver générique, peu optimisé pour travailler avec Azure Databricks. Il inclut des meta data dont Databricks n’a pas besoin, ce qui surcharge inutilement les requêtes.
A l’inverse, le connecteur Databricks fonctionne avec un driver propriétaire développé par Databricks et Microsoft : il est donc optimisé pour ce produit.
Les meta data présentes dans les requêtes ont été épurées afin d’être le plus proche possible du temps de réponse du cluster. Les échanges de données entre le cluster et PowerBI ont également été améliorés.
Une connexion simplifiée
Pour se connecter au cluster Databricks, avec l’ancien connecteur, on doit construire soi- même l’url à partir de la chaîne ODBC du cluster. Cela ne simplifie pas le process.
Avec le connecteur Databricks, cette partie est simplifiée : il suffit de copier/coller les informations.
Authentification
Le nouveau connecteur propose l’authentification Azure Active Directory, ce qui est un énorme bénéfice pour la plate-forme Data sur Azure. Ainsi, on n’est plus obligé de générer un jeton Databricks : il suffit de paramétrer les accès qu’on veut donner à son user AD.
Le gain en termes de sécurité est important : on peut désormais contrôler exactement ce que l’utilisateur voit depuis Power BI en jouant avec les droits d’accès de l’utilisateur.
Eco-système global
Le connecteur Databricks s’inscrit dans une évolution plus globale de la plate-forme Data : il est conçu pour être utilisé avec Spark 3.0. Le but est de bénéficier des avantages de celui-ci, c’est à dire du moteur Delta Engine.
Le connecteur Spark est employé avec les versions antérieures de Databricks, qui ne profitent pas de ces ajouts.
Connecteur Databricks vs Spark : application pratique
Pour notre test, nous avons créé une table de petite taille contenant des statistiques sur le COVID aux Etats-Unis, afin d’évaluer l’interconnexion entre Databricks et Power BI.
La configuration appliquée est la suivante :
Connecteur Spark : Runtime 6.6 avec Apache Spark 2.4.5 et Scala 2.11
Connecteur Databricks : Runtime 7.3 avec Apache Spark 3.0.1 et Scala 2.12
Les types de driver et de worker sont identiques pour les deux tests.
Pour la connexion au cluster, nous avons construit nous-mêmes l’url. Nous avons utilisé les valeurs présentes dans la configuration du cluster :


Une fois l’url renseignée, nous avons le choix de connexion avec Azure Active Directory :
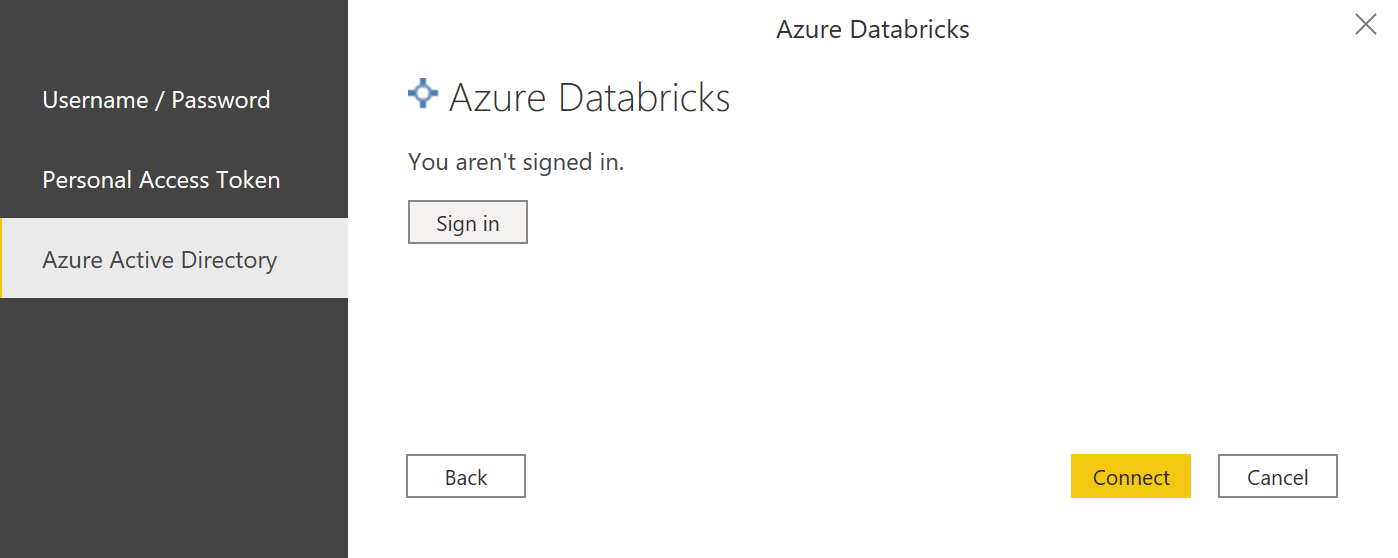
En cliquant sur le bouton « Sign in », on peut s’authentifier grâce à la fenêtre de connexion login MicrosoftOnline :

Une fois l’authentification réussie, on peut se connecter au cluster :

La liste des tables disponibles se présente un peu différemment par rapport au connecteur Spark. Le nom de la base de données est visible :

Pour le test, on effectue les opérations de se connecter en direct query, faire des refresh, créer une requête d’agrégation, puis effectuer un import des datas.
Les avantages d’utilisation du connecteur Databricks
Le test que nous venons de réaliser montre de nombreux avantages à utiliser le connecteur Databricks :
- Gain de temps considérable pour l’affichage des données en preview d’une table : 7 secondes pour afficher avec l’ancien connecteur contre 2 secondes pour afficher avec le nouveau.
- Chargement de la table pour créer un rapport sans requête particulière : gain d’environ 50% du temps de chargement des données (20 secondes pour l’ancien connecteur contre 10 secondes pour le nouveau).
- Léger gain de temps pour un refresh du rapport sur une requête contenant des agrégations : le rafraîchissement dure 3 secondes de moins qu’au premier chargement avec le nouveau connecteur par rapport au premier chargement. Le temps de refresh n’a pas changé avec l’ancien connecteur.
- Simplicité de la connexion avec Azure Active Directory.
Plus de fluidité, plus de performance
Deux gros bénéfices sont au rendez-vous pour le connecteur Databricks : la fluidité de l’expérience utilisateur et l’augmentation des performances.
Avec le nouveau connecteur Power BI et surtout l’intégration Azure Active Directory, Databricks simplifie l’expérience utilisateur pour les analystes et les administrateurs de Azure Databricks.
Le connecteur étant encore en preview, gageons que d’ici sa sortie en Generally Available (GA) nous pourrons constater une hausse des performances.
Enfin, Databricks a annoncé l’acquisition de l’outil de visualisation Redash. Cela laisse présager l’évolution de cette expérience pour la rendre plus adaptée pour les analystes SQL.
Si vous êtes curieux de ce qu’est Redash, rendez-vous dans notre prochain article pour un tour du propriétaire !! 😃
✍️ Cet article a été co-rédigé par Larysa Sudas (Cellenza) et Quentin Ambard (Databricks)






