

Avec l’évolution rapide des technologies cloud, de nombreuses entreprises cherchent à moderniser leurs plateformes d’intégration. Microsoft BizTalk Server montre aujourd’hui...
27 mai 2014
ASP.NET MVC vs SEO : Part 2 – le fichier robots.txt

Dans mon billet précédent consacré au SEO pour les sites en ASP.NET MVC, on a pu voir l’intérêt des balises META pour le référencement de sites internet. Encore une fois, cela n’est pas suffisant pour arriver en tête des moteurs de recherche (décidemment le référencement c’est dur 🙂 ) .
Cette fois-ci, nous allons étudier une nouvelle notion utile au SEO à savoir : l’utilisation des fichiers « Robots.txt » sur notre site MVC.
Le fichier Robot.txt : kezako ?
C’est une ressource accessible directement via le web que l’on retrouve sur la majorité des grands sites publics. Ils ne sont pas obligatoires et ne sont d’ailleurs pas présents lorsque vous initialisez un projet Web ASP.NET MVC par défaut dans Visual studio. Pour consulter le fichier « robots.txt » des sites internet (s’ils en ont un), il vous suffit en général d’aller sur un site web et d’ajouter à l’url « /robots.txt ».
Intérêt pour le SEO
Comme son nom l’indique, le fichier « robots.txt » sera exploité par les fameux robots de moteurs de recherche. Il est en général à la racine de votre site internet (cela dépend bien sur de votre implémentation) et surtout accessible via l’url http://www.votre-domaine.fr/robots.txt. Son principal objectif est d’empêcher l’indexation par les moteurs de recherche de certaines pages de votre site : vous disposez ainsi d’un instrument supplémentaire pour filtrer (et donc bloquer) des pages de votre site internet qui n’ont pas vocation à favoriser votre SEO. Le fichier robots.txt permet également d’indiquer aux robots des moteurs de recherche l’emplacement du « sitemap » de votre site (nous verrons le ‘sitemap’ dans mon prochain billet).
Implémentation avec ASP.NET MVC du robots.txt
En général, le fichier robots.txt est un fichier physique sur le serveur accessible en lecture seule. Il existe cependant plusieurs techniques pour mettre en place cette ressource sur un site ASP.NET MVC. Celle que je vais présenter ici passe par l’implémentation via un HttpHandler : nous allons générer dynamiquement le flux au format « texte » en sortie. Cette technique permet d’isoler en quelque sorte ce fichier du mécanisme MVC et Razor : le controller MVC ne rend donc pas une « view » via son mécanisme de routing, mais on rend simplement accessible en lecture une information via un canal annexe (le handler). L’intérêt de passer par cette technique est surtout de pouvoir générer dynamiquement des références à des pages de notre site au cas où l’on voudrait automatiser sa génération : on évite ainsi la mise à jour manuelle du fichier.
Pour cela, nous allons créer un dossier qu’on nommera « Helpers » dans notre solution VS et créer une classe RobotsHandler.cs qui implémentera l’interface IHttpHandler (où créer directement un ASP.NET Handler via l’interface en faisant un click droit sur le dossier ‘Helpers’ > Add > new Item > ASP.NET Handler).

Une fois l’interface implémentée, nous allons implémenter la génération du rendu du « robots.txt » via la méthode « ProcessRequest » :
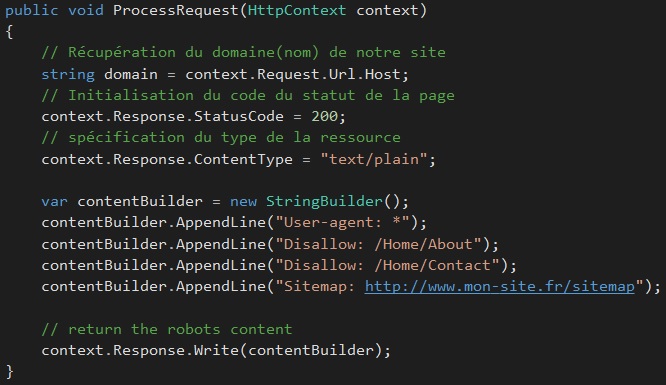
Le Fichier Robots.txt devra contenir en premier lieu une ligne pour le « User-agent » : on y spécifiera les moteurs ciblés (tous les moteurs de recherche par exemple). Pour les restrictions des pages : on utilisera la clé « Disallow« . Dans l’exemple ci-dessus, on bloque le scan par les robots des pages « About » et « Contact » de notre site : ces pages ne seront donc pas indexées (référencées). Pour bloquer l’accès de toutes les pages du site à tous les robots. Par exemple, on mettra la ligne suivante :
contentBuilder.AppendLine(« Disallow: / »);
Cela n’empêche cependant pas l’indexation du site par les moteurs de recherche : il faudra pour cela rajouter dans le header la meta suivante (comme vu dans le billet précédent) :
<meta name= »robots » content= »noindex » />
On peut également spécifier le chemin du Sitemap via la clé « Sitemap », comme le montre la figure au dessus.
Modification du web.config
Il faut modifier notre web.config pour faire fonctionner notre Handler :
Dans la section <system.webServer><handlers> du web.config, on rajoutera la ligne suivante pour enregistrer notre Handler :
<addname= »Robots » verb= »* » path= »/robots.txt » type= »DemoRobotTXTsitemapXML.Helpers.RobotsHandler » preCondition= »managedHandler« />
Dans le fichier RouteConfig (dossier App_Start), on va rajouter une ligne pour ignorer le mécanisme de « routing MVC ».
routes.IgnoreRoute(« robots.txt »);
Une fois, notre « Handler » implémenté, nous allons nous assurer que tout cela fonctionne en saisissant l’url http://www.mon-site.fr/robots.txt . Le résultat devrait ressembler à la figure ci-dessous :

Conclusion
Le fichier ‘robots.txt’ va permettre de mettre des restrictions aux robots d’indexation des moteurs de recherche sur des pages de notre site internet. Ce qui va potentiellement améliorer notre référencement en fonction de notre politique SEO : on pourra ainsi mettre en avant des pages plutôt que d’autres. Dans mon prochain billet qui viendra compléter celui ci, Je parlerai du fichier SiteMap.xml qui justement nous permettra de mettre en avant les pages que nous souhaitons voir indexées. A très bientôt 🙂
Ci dessous le lien github du code source de l’implémentation du fichier robots.txt :






