

Avec l’évolution rapide des technologies cloud, de nombreuses entreprises cherchent à moderniser leurs plateformes d’intégration. Microsoft BizTalk Server montre aujourd’hui...
14 septembre 2021
Comment bien écrire un pipeline en YAML ?

Dans un précédent article d’introduction à YAML Pipelines, nous vous avions présenté les fondamentaux des pipelines Azure DevOps en YAML. Nous avions vu comment créer un pipeline de build sans passer par l’éditeur classique et comment découper un workflow à l’aide des jobs et des stages.
La fonctionnalité « multi-stages pipelines » était alors en preview. Elle est maintenant passée en GA (Generally Available) : plus besoin d’activer quoi que ce soit pour en profiter.
Dans ce nouvel article consacré aux pipelines YAML, nous irons encore plus loin. Tout d’abord, nous verrons comment orchestrer le déploiement de notre code après le build et les tests. Puis, nous étudierons quelques fonctionnalités qui vont permettre de mutualiser des morceaux de fichiers YAML.
Les releases en YAML
Reprenons l’exemple de l’article précédent : nous avions mis en place un pipeline de build comportant deux étapes, Build et Test.
Maintenant que notre build fonctionne, nous voulons naturellement déployer notre site web.
Rappelons que la tâche d’un développeur est terminée lorsque son travail est en production et que tout fonctionne comme prévu ! 🙂
Nous pourrions évidemment le faire via un pipeline classique de release. Les build YAML, pour peu qu’elles produisent des artefacts, peuvent être utilisées comme sources pour les pipelines de release classique. Mais puisque cet article est consacré aux pipelines YAML, nous allons intégrer le déploiement directement dans notre pipeline de build YAML.
Dans l’article précédent, nous avions séparé le build et les tests à des fins de démonstration. En pratique, ces deux étapes sont souvent liées, soit dans un même job, soit dans deux jobs séparés. Commençons donc par les rassembler avant d’ajouter un stage de déploiement.

Et voilà : maintenant, lorsque nous mettons à jour notre site web et si notre modification passe les tests, une nouvelle version sera automatiquement déployée. Nous avons mis en place la livraison continue.
Ce type de workflow est parfaitement adapté pour une démonstration ou pour un projet simple, mais dans la réalité, il est rare d’avoir un seul environnement : et bien souvent un peu d’orchestration est nécessaire. Des testeurs doivent valider sur un environnement de QA (Quality Assurance), un product manager souhaite approuver les déploiements en prod, etc.
En ce qui concerne les multiples environnements, c’est relativement simple puisqu’il suffit d’ajouter des stages pour chaque environnement. Vous pouvez faire simplement des copier/coller puisqu’il s’agit d’un fichier texte, mais nous verrons un peu plus loin dans cet article une façon plus élégante de réaliser cette duplication.
Pour les approbations, il existe deux possibilités :
- Sur un « environnement »
- Sur une connexion de service
Pour l’instant, les approbations ne fonctionnent que sur le pré-déploiement. Complètement absentes au départ, elles permettent aujourd’hui l’utilisation des pipelines en YAML dans le cadre de déploiements complexes, plus proches de la réalité d’entreprise.
L’arrivée de ces approbations fût une grande avancée pour l’adoption des pipelines YAML comme standard pour les définitions de releases dans Azure DevOps.
Voyons maintenant comment ajouter une approbation de pré-déploiement sur notre stage.
Cas n°1 : Utilisation d’un environnement
Tout d’abord, il faut créer un environnement, que nous appellerons Web-test.
Les environnements se trouvent dans le menu « Pipelines » :

Puisque nous n’en avons pas, Azure DevOps nous invite à créer notre premier environnement :

Remarque : il n’est pas nécessaire de créer un environnement pour y faire référence. Azure Pipelines créera automatiquement un environnement référencé dans un pipeline s’il n’existe pas déjà. La création préalable nous permet de configurer directement l’approbation.
Donnons simplement un nom à notre environnement, sans ajouter de ressource :

Une fois notre environnement créé, nous pouvons lui ajouter un « Approval ».
Pour cela, il faut cliquer sur les trois petits points en haut à droite et choisir « Approvals and checks » dans la liste déroulante :

Le premier check proposé est justement celui qui nous intéresse, mais il en existe d’autres et la liste ne cesse de s’allonger.
Il manque encore certains checks que l’on trouve dans les pipelines classiques. Ils seront probablement ajoutés dans une prochaine version.

Tout comme dans les pipelines classiques, il est possible d’indiquer un ou plusieurs utilisateurs ou groupes. S’il y en a plusieurs, il faudra préciser si c’est l’un au moins, tous dans cet ordre ou dans n’importe quel ordre.

Pour pouvoir utiliser les environnements dans notre pipeline YAML, nous devons utiliser un type de job un peu spécial : un job de déploiement (ou « deployment » dans la syntaxe YAML).
Voici l’exemple en YAML :
Et le résultat dans l’écran de détail de l’exécution :

Le panneau d’approbation est légèrement différent mais on s’y retrouve facilement.

A noter : il n’est pas possible ici de reporter le déploiement. Il faudra ajouter un autre check de type « plage horaire » pour approuver en journée un déploiement à réaliser en dehors des périodes d’affluence par exemple.
Remarque sur les types de déploiements :
Nous avons spécifié un type simple de stratégie : runOnce. Dans cette stratégie, chaque job sera exécuté une seule fois sur notre environnement. Sachez qu’il en existe d’autres, comme la stratégie « rolling » qui permet de déployer en parallèle sur plusieurs VM d’un même environnement. Il s’agit de l’équivalent YAML des groupes de déploiement. Enfin, il existe la stratégie « canary » qui fonctionne pour les ressources de type Kubernetes et permet de router progressivement le trafic vers une nouvelle version.
Cas n° 2 : La connexion de service
Très souvent, lorsqu’on déploie sur Azure ou un autre fournisseur de service, on utilise des connexions de services. Celles-ci se configurent dans les paramètres du projet.

Elles disposent également de checks et d’approbations. C’est le cas depuis moins longtemps que les environnements, mais c’est plus sécurisé car les connexions de services disposent de leurs propres habilitations.

Pour le reste, la configuration est la même. L’approbation sera requise dès qu’une tâche souhaitera exploiter cette connexion de service.
Les templates en YAML
Les templates sont aux pipelines YAML ce que les groupes de tâches sont aux pipelines classiques. Mais en beaucoup mieux ! Nous allons voir pourquoi.
Les templates sont des fichiers auxquels on va pouvoir faire référence dans un pipeline YAML. Il s’agit également de fichiers YAML. Ils contiennent généralement un ensemble de paramètres et peuvent représenter un ensemble de tâches, de jobs ou même de stages. Lorsque vous faites appel à un template, vous n’avez alors qu’à indiquer le chemin du fichier ainsi que la valeur des différents paramètres.
Voyons un exemple avec notre définition de pipeline. Supposons que nous voulons déployer sur un environnement de test, puis sur un environnement de production. Plutôt que de copier-coller les lignes de code correspondant à l’exemple du cas n°1, voyons comment faire cela avec un template.
Tout d’abord, nous allons extraire les étapes de la release dans un fichier de template.
Utilisons maintenant une référence à notre template dans notre pipeline YAML :
Créons ensuite un nouvel environnement pour la production. Nous l’appellerons Web-prod et il sera également soumis à une approbation.

Pour finir, il nous suffit de faire un nouvel appel au template pour ajouter une release en production.

Simple et efficace n’est-ce pas ?!
La syntaxe template
La syntaxe template permet d’indiquer au compilateur un certain nombre d’opérations. Elle est notée ${{ expression }} et est interprétée avant l’exécution, lorsque le compilateur assemble les templates pour générer un fichier YAML final. C’est celui-ci qui sera alors exécuté.
Elle est principalement utilisée pour faire référence aux paramètres dans les templates, mais peut même s’utiliser en dehors du template lui-même.
Il est par exemple possible d’insérer des blocs conditionnels à l’aide de l’instruction if.
Supposons que nous ne voulons pas voir de stage prod si nous ne déployons pas la branche master. Nous pouvons supprimer le stage prod dans ce cas.

Puisque l’expression est évaluée à la compilation, ici le stage est totalement absent, comme s’il n’existait pas. C’est en réalité ce qui se passe. Le deuxième stage correspondant à la prod n’est pas inséré dans le YAML final qui sera exécuté.
On aurait aussi pu exécuter des templates différents en fonction de la branche en combinant plusieurs expressions if.
Partager les ressources
Les fichiers templates peuvent se trouver dans le même repo que le code source. Ils peuvent également se trouver dans un autre repo, voire dans un autre projet au sein de la même organisation.
C’est utile, par exemple, s’il existe un projet qui rassemble des ressources centralisées, développées par une équipe support et mise à disposition des équipes de dev.
Prenons l’exemple de notre template de release.
Si nous avons un autre projet qui déploie un site web de la même façon, nous pouvons extraire le template et le déposer dans un projet spécifique, distinct de nos deux sites web.
Nous utilisons alors une autre fonctionnalité des pipelines YAML : les ressources.
Elles permettent de définir des références à des ressources externes telles que :
- Des repo Git (Azure Repos) mais aussi GitHub ou GitLab à l’aide de connexions de services ;
- Des pipelines ;
- Des images Docker.
Le fait de définir une ressource de type repository dans notre pipeline va forcer celui-ci à extraire également ce repo.
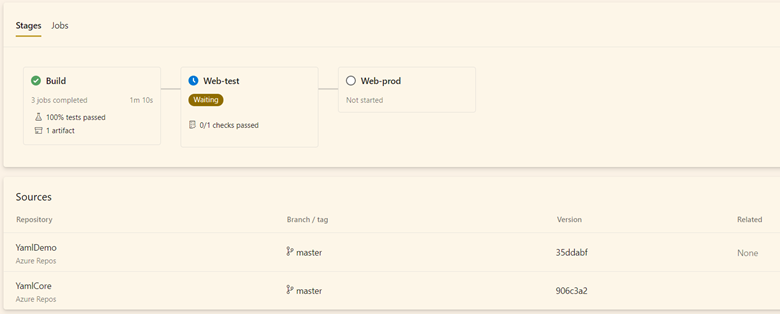
Les fichiers template sont alors accessibles pour la compilation du fichier YAML final.
Nous utilisons ici la ressource « repository » pour accéder aux templates. C’est également valable si vous avez besoin d’extraire plusieurs repos pour votre process de build ou release.
Par défaut, les différents repos sont extraits dans un sous-répertoire du nom de la ressource.
A propos du checkout : le checkout du repo dans lequel se trouve le YAML est automatique dans le cas d’un job classique et s’il est le seul repo utilisé. Dans le cas d’un deployment job, ou si on souhaite faire un checkout de plusieurs repos, il faudra préciser qu’on souhaite aussi télécharger le repo « self ».
Forcer un template
Forcer l’usage d’un template consiste à indiquer, dans le pipeline YAML, quel template doit nécessairement être référencé.
Cette fonctionnalité est principalement utilisée pour augmenter la sécurité en autorisant aux développeurs de passer uniquement les étapes nécessaires, tout en contrôlant le déroulement global du pipeline.
Pour cela, on va définir un squelette de pipeline dans le template, dans lequel on pourra décider d’exécuter un certain nombre de tâches de contrôle.
On utilisera ensuite le type des paramètres pour indiquer ce que les développeurs sont autorisés à injecter dans le template. En particulier, un paramètre peut être de type : step, liste de steps, job, liste de jobs, stage ou liste de stages.
En général, on autorisera plutôt une liste de steps ou éventuellement de jobs.
Voici un exemple de pipeline qui requiert le template main.yml auquel on aura seulement le droit de passer un ensemble de steps :
Dans notre exemple, des contrôles sont effectués sur la liste des steps. En particulier, on vérifie que la liste des steps de test n’est pas vide. Il s’agit là d’une situation qu’il serait facile de contourner mais l’objectif est ici d’illustrer un cas d’utilisation de cette fonctionnalité.
Ici, si je passe effectivement une étape de test, tout va bien :

Si je tente d’omettre les tests, mon build échoue et me rappelle à l’ordre :

En conjonction avec l’utilisation des templates forcés, il est possible d’ajouter sur vos environnements un contrôle de type « template requis ». Il ne sera alors pas possible d’utiliser un environnement dans un pipeline YAML si celui-ci ne référence pas le template indiqué.

Pour des déploiements Cloud, par exemple sur Azure, il est possible de mettre ce type de check sur les connexions de services. De ce fait, bien qu’il soit possible de modifier le pipeline pour ne pas utiliser l’environnement, il sera nécessaire de passer par une connexion de services. On peut alors vérifier que le pipeline qui tente de faire usage de cette connexion de service fait bien référence au template souhaité.
Dans le cas contraire, le contrôle échoue :

Une solution souple à bien sécuriser
Nous venons de voir quelques fonctionnalités assez avancées des pipelines YAML. L’utilisation des templates et des expressions permet un fort niveau de réutilisation du code. Il est possible de partager des définitions de pipelines avec plusieurs projets, ce qui n’est pas possible avec les groupes de tâches.
Il est si facile de créer des pipelines très complexes que Microsoft a dû imposer certaines limites dans l’utilisation des templates, telles qu’un nombre maximal de caractères dans les expressions ou une limitation du nombre de templates référencés (pour en savoir plus, nous vous invitons à consulter la documentation Microsoft).
La grande souplesse que présente ce type de pipeline s’accompagne d’un plus grand risque au niveau sécurité. Contrairement aux pipelines classiques qui étaient plutôt du ressort de personnes spécifiques, différentes des développeurs, on cherche cette fois à donner le plus d’autonomie possible à l’équipe de développement.
Il est donc important, dans les environnements critiques ou lorsqu’un contrôle est nécessaire, de penser à activer les checks et de mettre en place de la revue de code.
Il est possible par exemple d’ajouter automatiquement des reviewers spécifiques dans les PR (Pull Requests) lorsque les fichiers YAML sont modifiés.
Il existe encore quelques fonctionnalités ou propriétés des pipelines classiques qui n’existent pas dans les pipelines en YAML mais ceux-ci apportent déjà tellement de possibilités supplémentaires qu’il serait dommage de ne pas s’y intéresser.
Certes les pipelines classiques sont plus faciles à prendre en main au début, mais les pipelines en YAML offrent plus de souplesse, en particulier grâce au langage de templating et au versionning de code dans Git. Il est par exemple possible d’avoir une version spécifique à une branche de code, ce qui est très pratique dans le cas d’une montée de version par exemple.
Si vous hésitez encore à franchir le pas ou si vous ne voulez pas avoir trop de YAML à écrire, sachez enfin qu’il est possible de récupérer le YAML des pipelines classiques pour les copier/coller dans un fichier. C’est plus facile pour les pipelines de build que de release, mais cela reste possible tâche par tâche (https://devblogs.microsoft.com/devops/replacing-view-yaml/).






Bonjour,
J’aimerais savoir qui génère le code source pour toutes les entreprises?
D’avance merci,
Bien cordialement,
LAMBS Thomas
lambsthomas1@gmail.com
Bonjour Thomas,
Le code source des applications est poussé sur un repo par les équipes de développements.
Le code YAML des pipelines peut être écrit par ces mêmes équipes si elles se sentent à l’aise. Il est aussi possible que ce soit à la charge d’équipes DevOps lorsque les entreprises en ont.
Cela dépend du contexte, du nombre d’équipes. Souvent c’est lié à la taille de l’entreprise. Les petites structures ont tendance à reposer sur de petites équipes à tout faire. Les plus grosses entreprises ont des niveaux de sécurité plus élevés qui imposent un découpage des responsabilités. La gestion des pipelines et de la sécurité / compliance est alors généralement à la charge d’équipes centrales. Ces équipes mettent à disposition des ressources (templates YAML, connexions de services…) pour les équipes de dev.