

Avec l’évolution rapide des technologies cloud, de nombreuses entreprises cherchent à moderniser leurs plateformes d’intégration. Microsoft BizTalk Server montre aujourd’hui...
19 septembre 2023
Read this post in English
Retour d’expérience sur le Domain Driven Design

Le Domain Driven Design (DDD) est une méthodologie qui se concentre sur le métier (Domain). Elle entend faire respecter un principe simple : « tout concept métier doit être représenté dans le domaine (code) », du moins c’est ce que je pensais lorsque je m’y suis intéressé. Dans cet article, je vous propose de partager ce que j’ai appris au cours de mon exploration du DDD, en voyant ses concepts clés que sont le langage universel (Ubiquitous Language), les contextes délimités (Bounded Contexts), les agrégats (Aggregates), les racines d’agrégat (Aggregate Roots), les entités (Entity) et les objets de valeur (Value Objects).
Le langage universel – Ubiquitous Language
Définition du langage universel
Pour comprendre au mieux la problématique du métier, il est important que les développeurs et le métier partagent un langage commun, afin de réduire toute ambiguïté sur la compréhension du problème ou du besoin métier. C’est le langage universel (Ubiquitous Language). Voyons comment cela se manifeste sur une version simplifiée d’un site de e-commerce :
Ci-dessus, nous avons 3 objets représentant respectivement :
- Un produit « Product » vendu par le site
- Un élément du panier « ShoppingCartItem » qui représente la quantité d’un produit présente dans le panier
- Le panier « ShoppingCart » qui traduit l’intention d’achat et recense l’ensemble des produits
À ce stade, nous avons matérialisé des notions métier dans le code afin d’identifier leur nature et commencer à appréhender le comportement.
Le langage universel : une étape cruciale
C’est une étape cruciale qui, si elle est négligée, peut être source de frustration aussi bien pour le métier qui peut penser avoir été compris que pour les développeurs qui peuvent avoir anticipé certaines contraintes peut-être inutilement.
Il n’était pas rare de revenir sur les notions qui au départ semblaient claires, mais qui se sont affinées avec le temps. Le dialogue entre le métier et les développeurs est la clé.
C’est grâce à un langage universel clair que l’on peut identifier les contextes les plus pertinents pour chaque notion métier.
Les contextes délimités (Bounded Contexts)
Définition des contextes délimités
Si, au cours du cycle de vie du projet, certaines notions métier ont peu – voire pas – de sens dans un contexte, mais sont essentielles dans un autre, c’est peut-être le signe de la présence de contextes délimités. L’idée derrière ce concept est de regrouper des notions qui sont cohérentes dans la résolution d’un problème. Si nous reprenons notre exemple du site de e-commerce, nous pouvons dégager 3 contextes à partir des notions vues précédemment.
Analysons ensemble le découpage des contextes délimités :
- Le produit se retrouve dans le contexte « Catalogue Produit »
- « Elément du panier » voit son nom simplifié et est intégré au contexte « Panier d’achat »
- Enfin, le panier se transforme en commande et est intégré au contexte de « Gestion des commandes ».
Chaque contexte dédié est une solution à un problème. Cette solution peut être complète ou partielle. Le problème à résoudre est appelé sous-domaine (Sub-domain), et correspond à une partie de problématique du projet.
| Domaine | Sous domaine | Contexte dédié |
| Site de e-commerce | Gestion du catalogue produit | ProductCatalog |
| Gestion du panier | ShoppingCart | |
| Gestion des commandes | OrderManagement | |
| Gestion de la livraison | ShipmentManagement
OrderManagement |
Ici, les domaines dédiés « ProductCatalog », « ShoppingCart » et « ShipmentManagement » sont associés à un seul sous-domaine alors que « OrderManagement » est à cheval entre deux sous-domaines. Mais pourquoi ? Parce que le métier souhaite pouvoir livrer une commande à plusieurs adresses en fonction de contraintes propres au produit (scénario où il y a un échange de produits, ou scénario où il y a des délais de livraison différents liés à des contraintes de proximité avec la localisation du destinataire).
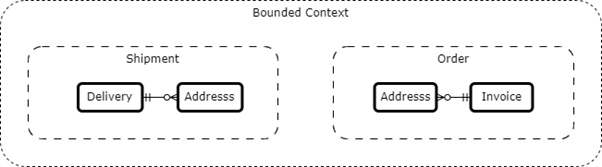
À NOTER : Il est fortement recommandé de maintenir une relation 1-1 entre le sous-domaine et le contexte dédié associé, dans le but de maintenir l’intelligibilité du projet.
Notez également que la notion de panier « ShoppingCart » correspond à un contexte dédié pour coller le mieux aux problématiques de gestion du panier (calcul de montant, ajout ou suppression d’élément dans le panier).
Ce qu’il faut retenir des contextes dédiés
Les contextes dédiés permettent de mieux appréhender le métier en faisant émerger les grandes problématiques du métier. Il est ainsi plus simple d’aborder le problème à résoudre et de limiter les effets.
Les entités (Entities) et les objets de valeur (Value Objects)
Entité
Une entité est une notion dans votre métier qui contient une identité claire et un cycle de vie dans le domaine. Son identité ne change jamais pendant son cycle de vie, mais ses attributs le peuvent. Sa principale responsabilité est de définir ce que sous-entend la phrase « Entité A et Entité B qui sont égales si … ». Cela se fait généralement en surchargeant la méthode Equals.
Le code ci-dessus définit les caractéristiques d’une entité et comment discerner les entités entre elles dans une classe abstraite.
Dans notre domaine, le produit a un cycle de vie qui se manifeste par le fait que son prix ou son nom peuvent changer. C’est pourquoi il semble être un bon candidat pour être une entité, car les entités sont des objets mutables.
Notez que le fait que laisser la responsabilité de l’égalité à la classe abstraite Entity simplifie la définition de la classe Product en enlevant le bruit sur l’identité et l’égalité de cette dernière.
Objet de valeur
Un objet de valeur décrit une notion métier qui n’est définie que par des caractéristiques ou son état. Il est utilisé comme un descripteur d’un concept ou d’un élément métier. Il n’a pas d’identité dans le domaine, car ses attributs sont son identité. Il est toujours utilisé dans un objet plus complexe, et donc compris dans un contexte particulier.
Ci-dessus on peut voir une proposition d’objet de valeur : la surcharge de l’égalité prend en compte tous les champs retournés par la méthode « GetAttributesToIncludeInEqualityCheck » en comparant les attributs de chaque objet de valeur. Le Hash de l’objet est également affecté par les attributs de l’objet.
L’objet de valeur est immutable, ce qui veut dire chargement se traduit par la création d’une nouvelle instance dans un état qui inclut les changements. Un bon exemple d’objet de valeur est « Money ».
Dans cette proposition de « Money », on peut voir que les champs « Value » et « Currency » sont pris en compte dans l’égalité de « Money ». On peut aussi noter que les méthodes qui impliquent un changement d’état génèrent une nouvelle instance de « Money ». De plus, la notion de « Currency » est déléguée dans un autre objet de valeur.
Entité et Objet de valeur : ce qu’il faut retenir
Finalement, l’identification des Entités et des Objets de valeur est assez simple. Le critère principal pour les différencier est de savoir si cet élément/concept est exclusivement identifiable par ses attributs. Si oui, c’est un objet de valeur. Sinon, une entité. Les objets de valeur contiennent une bonne partie des règles métier. Mettre en place les relations entre les entités et les objets de valeur permet de dégager les activités du domaine.
Les agrégats (Aggregates) et les racines d’agrégat (Aggregate Roots)
Les entités et les objets de valeur travaillent de concert pour former des relations complexes de règles dans le domaine. Lorsque l’on manipule des objets de domaine complexes, il peut être difficile de garantir la cohérence et la concurrence de ceux-ci lors de changement. L’exemple ci-dessous montre une représentation de la gestion des commandes. Si nous devions considérer toute cette collection d’objets comme un seul concept métier, cela serait très compliqué à maintenir en plus d’impacter les performances de l’application.
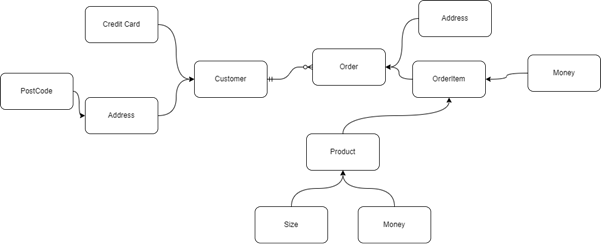
Dans cet exemple, la difficulté liée à cette représentation serait que le changement de l’adresse du compte client peut être modifié alors qu’une commande est en cours. Dès lors, on peut se demander si le changement doit être pris en compte immédiatement ou après que la commande en cours soit livrée.
L’agrégat est un amas d’objets associés que l’on traite comme un ensemble unitaire dans un le but de modifier des données. Chaque agrégat a une racine et un périmètre. Le périmètre définit ce qu’il y a dans l’agrégat et la racine est une entité unique qui est contenue dans l’agrégat qui sert de point d’entrée.
Eric Evans – Auteur de “Domain Driven Desing: Tackling Complexity in the Heart of Software
Essayons de comprendre cette définition au travers de notre précédent exemple. Nous pouvons identifier 3 amas :
- Le compte client (Customer), qui pourrait s’occuper de la gestion du compte client
- La commande (Order), qui s’occuperait de la gestion de commandes
- Le produit (Product), qui se concentrerait sur la gestion du catalogue produit

Chaque amas peut être manipulé comme un ensemble cohérent et concurrent, vis-à-vis de ses invariants, ses entités et objets de valeur.
Une fois que ce travail de balisage a été fait, on peut assez facilement identifier la racine de chaque agrégat. Pour notre exemple, elles sont : Customer, Order et Product.
Les relations entre les agrégats sont matérialisées en référençant les Id des racines d’agrégat et non pas la référence des objets eux-mêmes. Cela dans le but de maintenir les limites de chaque agrégat et de limiter la taille du graphe d’objet à charger.

Les invariants d’un agrégat sont les règles qui garantissent la cohérence métier d’un agrégat. Lors du cycle de vie de l’agrégat, elles doivent toujours être vérifiées. Ce sont les règles de gestion appliquées à l’agrégat.
Voyons comment elles peuvent être définies dans le code :
« OrderItem » est un objet de valeur de l’agrégat « Order ». La commande garantit que le nombre d’articles ne dépasse pas la limite maximale. On peut noter que les articles de la commande ne sont modifiables en dehors de l’agrégat, cependant il est possible de les consulter via la propriété « Items ».
Qu’en est-il de l’ajout d’un produit avec une quantité négative ? Cela est contrôlé par les invariants de l’objet valeur « OrderItem » comme le montre le code suivant :
Conseils pratiques sur les agrégats
Les agrégats sont des concepts clés du domaine dont les modifications doivent faire l’objet d’une attention particulière. Les identifier fait appel à votre connaissance du métier. Voici quelques points identifiés par la pratique :
- Ne pas hésiter à faire des schémas pour comprendre les interactions entre les entités et les objets de valeur pour identifier vos agrégats.
- La racine de l’agrégat est une seule et unique entité de l’agrégat, mais son contexte peut avoir plusieurs agrégats.
- La racine de l’agrégat est le gardien de la cohérence et de la concurrence de l’agrégat. Les changements se font via ses méthodes qui contiennent et appliquent ses invariants.
- Privilégier les petits agrégats dans un premier temps, la transition vers des agrégats plus grands n’en sera que plus simple.
- L’agrégat est lu et persisté dans sa globalité.
La création d’objets complexes
Lors de la création d’un objet (entité ou objet de valeur), il faut privilégier le constructeur. Mais dans les cas d’objets complexes, il est recommandé d’utiliser le pattern « Factory » pour centraliser les règles de gestion au même endroit.
Ici, l’objet « Order » permet de créer une commande avec les items alors que dans la précédente implémentation, l’ajout d’éléments à la commande devait se faire dans un second temps.
Persistance et hydratation
La récupération et l’hydratation des agrégats peuvent se faire via le pattern « Repository » puisqu’il abstrait la persistance des agrégats du modèle. Il est très important de noter que la persistance d’un agrégat n’est jamais partielle. Le changement peut être partiel, mais l’agrégat doit être considéré comme une unité non dissociable de ses composants. Cela signifie que tout changement sur un agrégat passe par les phases suivantes :
- Récupération de l’agrégat
- Modification de l’agrégation
- Persistance l’agrégat
Ce processus peut parfois être lourd, c’est pourquoi il n’est recommandé que dans les cas de création et/ou de modification de l’agrégat. Pour la lecture seule, il est plus intéressant et moins coûteux de requêter directement la base de données en passant par des solutions plus optimisées pour la lecture (Vues ou procédure stockées en SQL en sont des exemples).
Pour aller plus loin sur le Domain Driven Design
Nous avons vu quelques concepts clés du Domain Driven Design (DDD) et comment ceux-ci sont appliqués dans notre code.
Les contextes dédiés nous permettent d’identifier les comportements importants de notre métier. Ces comportements se matérialisent par la mise en relation de blocs élémentaires : les Entités, objets identifiables par une identité et ayant un cycle de vie, et les objets de valeur, qui eux sont identifiables par tous leurs attributs et sont immutables.
Ces blocs élémentaires sont regroupés dans des amas appelés agrégats (Aggregates) où seule une Entité est définie comme étant la racine de l’agrégat (Aggregate Root). Les agrégats sont traités comme des ensembles unitaires impliquant ainsi que tout changement d’un de ses composants se fait via la racine de l’agrégat.
Tous ces concepts font partie des patterns Tactiques (Tactical patterns) du DDD pour mettre en place votre code base, mais il existe aussi les patterns stratégiques qui visent à identifier comment les contextes délimités communiquent entre eux souvent dans un système distribué. Un vaste sujet qui fera l’objet d’une prochaine publication.
Sources :
- Ouvrage “Domain Driven Desing, Tackling Complexity in the Heart of Software” d’Eric Evans
- Lien GitHub du code utilisé dans l’article





