

Le Machine Learning automatisé (ou AutoML) est une méthode d’optimisation des paramètres pour vos modèles de Machine Learning (ML). Il...
23 mai 2024
Utiliser Azure OpenAI, LangChain et Ragas pour la classification des documents confidentiels et la protection des données sensibles

Article co-écrit par Fawzi Rida, Elyes Yahyaoui et Mohssine Chebli
Dans le paysage complexe de la gestion de l’information au sein des entreprises, la politique de classification des données joue un rôle crucial. Cette politique définit les exigences pour la protection de l’information, assurant l’ordre, la cohérence et la conformité au sein des organisations.
Les entreprises sont différentes, et se distinguent avec leurs propres spécificités en matière de classification de données. Cependant, on trouve généralement quatre catégories de données :
- Données publiques
- Données internes et non publiques
- Données internes sensibles
- Données très sensibles
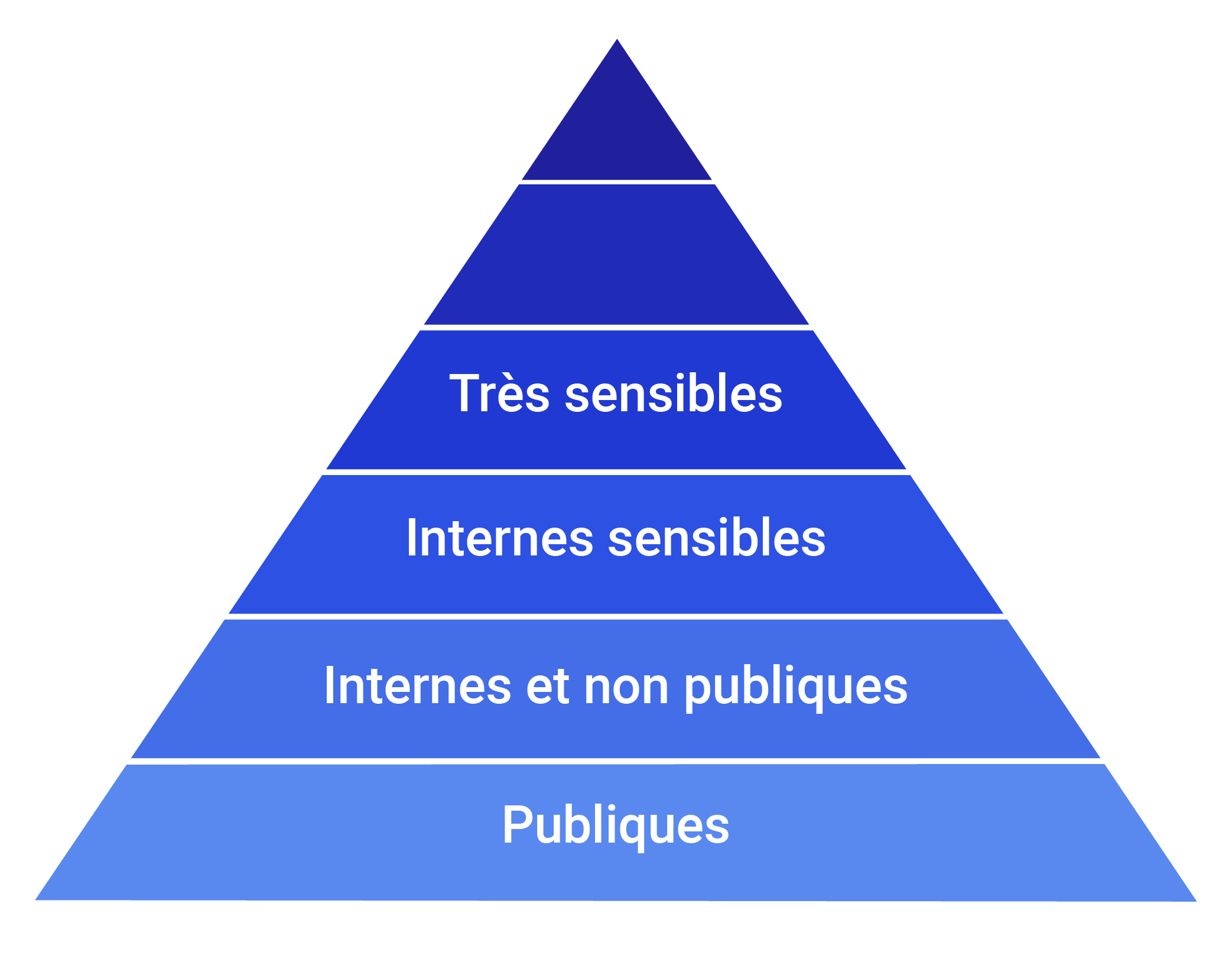
Pyramide de la confidentialité des données des entreprises
À titre d’exemple, l’OTAN utilise un système de six catégories allant de “TOP Secret Cosmic” à “Public”.
Cette tâche de classification de documents est chronophage et peu stimulante ; elle est parfois gérée d’une manière artisanale avec une équipe dédiée. Il est donc crucial de l’automatiser afin de libérer ces équipes, et leur permettre ainsi de se concentrer sur des initiatives plus innovantes et intéressantes au sein de l’entreprise.
Par ailleurs, avec l’avènement du Règlement Général sur la Protection des Données (RGPD) depuis le 25 mars 20018, la définition des données personnelles est devenue plus stricte et précise. Cette réglementation impose des règles strictes aux entreprises pour la collecte, le traitement et le stockage des données personnelles, qu’elles soient identifiées directement ou indirectement.
Dans cet article, nous allons vous montrer comment classifier des documents d’entreprise avec un Large Langage Model (LLM – GPT3.5 Turbo), comment créer un chatbot, en se basant sur les articles de la CNIL, simplifiant l’accès et la compréhension des articles du RGPD. Enfin, nous allons voir comment évaluer ces systèmes type RETRIVAL AUGMENTED GENERATION (RAG).
Langchain
Qu’est-ce que LangChain?
LangChain est un framework open source conçu pour implémenter des applications exploitant les Large Langage Models (LLM). Ces derniers, résultant d’un apprentissage profond sur de vastes ensembles de données, sont capables de répondre aux requêtes des utilisateurs, comme répondre à des questions ou générer des images à partir de consignes textuelles. LangChain fournit un toolbox riche pour utiliser, personnaliser et améliorer la pertinence des informations générées par les LLM.
Cette plateforme simplifie chaque étape du cycle de vie des applications LLM :
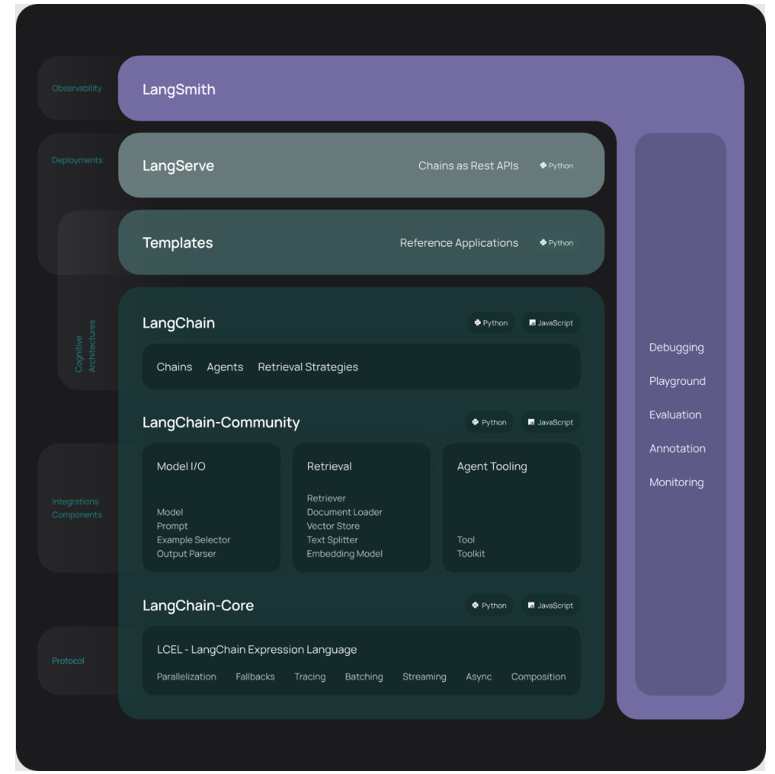
Développement : les blocs de construction fournis, et la possibilité d’utiliser des intégrations tierces et des modèles préétablis accélèrent le développement.
Mise en production : le composant LangSmith permet d’inspecter, surveiller et évaluer les chaînes, afin de pouvoir les optimiser en continu, et les déployer en toute confiance.
Déploiement : LangServe offre la possibilité de transformer n’importe quelle chaîne en une API.
Quels sont les composants essentiels de LangChain ?
Avec LangChain, il est possible d’élaborer des systèmes sensibles au contexte grâce aux modules suivants :
Interface LLM
LangChain fournit des APIs pour la connexion et l’interrogation des LLM, permettant ainsi l’interaction avec ces modèles publics et privés tels que GPT, Gemini et PaLM, en utilisant des appels d’APIs simples au lieu d’écrire un code complexe.
Modèles d’invite (Templates)
Ces modèles prédéfinis permettent aux développeurs de formater de manière cohérente et précise les requêtes destinées aux modèles d’IA. Ils peuvent être utilisés pour les chatbots, les étapes d’apprentissage, ou pour fournir des instructions spécifiques aux modèles de langage.
Agents
Un agent est une chaîne spéciale qui guide le modèle de langage dans le choix de la meilleure séquence en réponse à une requête, en prenant en compte les informations de l’utilisateur, les outils disponibles et les étapes intermédiaires possibles.
Modules de récupération
LangChain facilite la création d’architectures de systèmes RAG en fournissant divers outils pour transformer, stocker, rechercher et récupérer des informations qui affinent les réponses des modèles de langage. Les développeurs peuvent ainsi créer des représentations sémantiques d’informations à l’aide d’intégrations de mots, et les stocker localement ou dans le Cloud.
Mémoire
LangChain permet aux développeurs d’incorporer des capacités de mémoire dans leurs systèmes de modèles de langage. Cela inclut des systèmes de mémoire simples qui retiennent les conversations récentes, ainsi que des structures de mémoire complexes qui analysent les messages historiques pour fournir les résultats les plus pertinents.
Rappels
Les rappels sont des codes que les développeurs insèrent dans leurs applications pour enregistrer, surveiller et diffuser des événements spécifiques dans les opérations de LangChain. Par exemple, cela permet de suivre quand une chaîne a été appelée pour la première fois, ou les erreurs rencontrées lors des opérations.
Comparaison entre Langchain, Semantic Kernel et AutoGen
LangChain est la plateforme la plus mature et populaire jusqu’à présent, mais d’autres alternatives existent, et selon le besoin spécifique de chaque application, on pourra opter pour ces dernières. Une étude comparative a été effectuée par Jane Huang, Data Scientist chez Microsoft, détaillant les spécificités de chaque framework. Ci-dessous nous vous présentons un récapitulatif qui résume cette étude :
| Caractéristiques | Langchain | Semantic Kernel | AutoGen |
| Date de release | Octobre 2022 | Mars 2023 | Octobre 2023 |
| Langages supportés | Python, JavaScript/TypeScript | C#, Java, Python | Python, C++ |
| Licence Open-source | MIT License | MIT License | Attribution 4.0 International, MIT license |
| Popularité | ★★★ (11.8K GitHub forks through Feb 20, 2024) | ★★ (2.5k GitHub forks through Feb 20, 2024) | ★★★ (3.0k GitHub forks through Feb 20, 2024 |
| Contributeurs | Harrison Chase and other 2200+ contributors | Microsoft and other
200+ contributors |
Microsoft and other
200+ contributors |
Source : Jane Huang Data Scientist At Microsoft
Etapes essentielles pour concevoir une application IA Générative se basant sur Langchain
Prompt Engineering :
| Prompt Types | Exemples | Explications |
| FewShots | Traduisez les phrases anglaises suivantes en français : « Hello » -> « Bonjour », « Goodbye » -> « Au revoir », « Thank you» -> « Merci ».
Traduisez maintenant : « Bonjour » |
Cette technique consiste à donner des exemples des outputs souhaités. |
| Chain Of Thought | Je suis allé au marché et j’ai acheté 10 pommes. J’ai donné 2 pommes au voisin et 2 au réparateur. Je suis ensuite allé acheter 5 pommes supplémentaires et j’en ai mangé 1. Combien de pommes me restait-il ?
Réfléchissons étape par étape. |
Cette technique consiste à décomposer des tâches complexes en sous-tâches plus simples, et à transmettre le résultat d’une sous-tâche en entrée de la suivante. |
| ReAct | Écrivez un poème sur le printemps. (Sortie : Un poème)
Réaction : C’est un bon début, mais pouvons-nous le rendre plus joyeux ? |
Cette technique implique que le modèle réagisse à ses propres résultats pour générer des réponses plus diverses et plus créatives. |
Le prompt engineering, ou « ingénierie de requête », est une méthode qui consiste à donner des directives détaillées aux modèles de traitement du langage naturel pour améliorer leur performance. En pratique, cette technique guide le modèle LLM de manière plus spécifique en fournissant des indications sur la nature de la tâche à réaliser et son contexte. Au lieu de laisser le modèle répondre de façon générique à une question, le prompt engineering permet d’orienter la réponse souhaitée. Le tableau ci-dessous récapitule les types des prompts qu’on peut utiliser pour optimiser la performance du LLM :
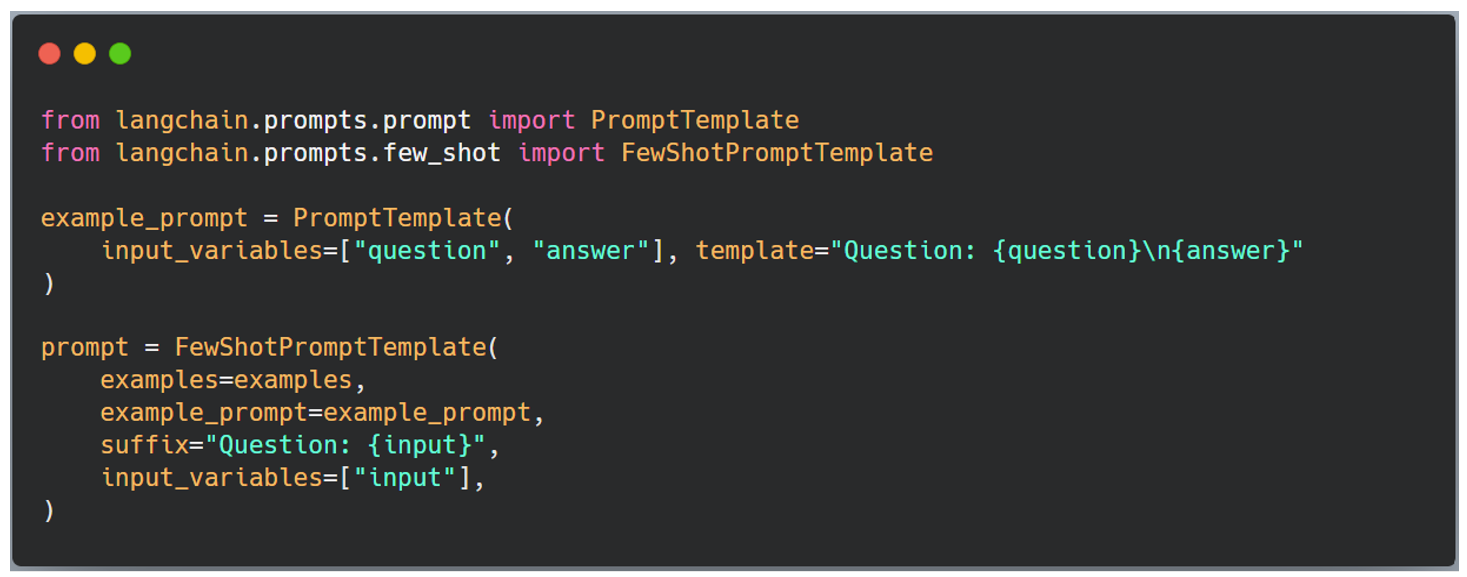
Le framework LangChain offre une implémentation de ces types de prompt engineering, le code ci-dessous permet d’utiliser la méthode Few Shots.
Text Splitting ou chunking
Le Chunking est une stratégie de division de texte en petits segments basés sur des motifs et structures linguistiques. Le chunking permet de ne pas dépasser la capacité maximale des tokens d’un LLM, ce qu’on appelle la contrainte du window contexte. Par exemple, la capacité maximale d’un GPT 3.5-trubo est de 4096 tokens. Le Chunking peut être réalisé par différentes méthodes, le tableau ci-dessous récapitule les méthodes de chunking classiques :
| Division | Avec Metadata | Description | |
| HTML | Caractères spécifiques à HTML | ✅ | Divise le texte en fonction des caractères spécifiques à HTML. Notamment, cela ajoute des informations pertinentes sur l’origine de ce fragment (basé sur le HTML). |
| Code | Caractères spécifiques au Code (Python, JS) | Divise le texte en fonction des caractères spécifiques aux langages de programmation. | |
| Caractère | Un caractère défini par l’utilisateur | Divise le texte en fonction d’un caractère défini par l’utilisateur. | |
| [Expérimental] Séparateur sémantique | Phrases | Divise d’abord sur les phrases. Puis combine celles qui sont similaires. |
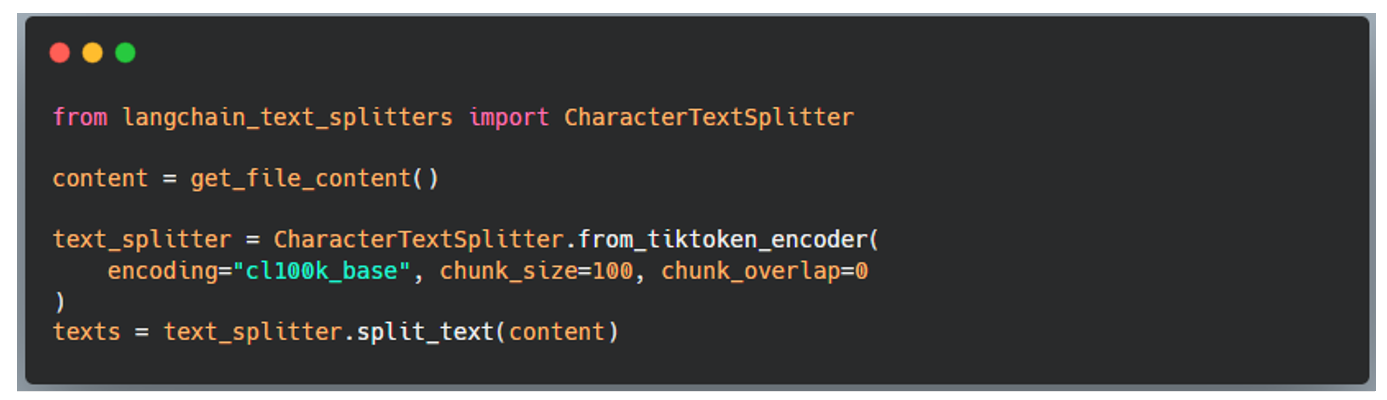
Langchain offre la possibilité d’utiliser plusieurs types de chunking. Par exemple, dans le code ci-dessous, on utilise le chunking par nombre de caractères fixé à 100 :
Tokenisation
La tokenisation consiste à diviser le texte des inputs et outputs en petites unités appelées tokens. Un token est équivalent à 4 caractères, et permet l’optimisation de la mémoire et les coûts computationnels. La tokenisation a un effet direct sur la qualité et la diversité des textes générés par les modèles LLM.
Il existe différents types de tokenizers comme caractères, mots et sous-mots. A savoir que le modèle GTP4 repose sur Byte Pair Encoding (BPE) qui consiste à fusionner les paires de caractères les plus fréquentes. Dans l’exemple ci-dessous, le texte est transformé en tokens, et chaque token textuel est converti en un identifiant.


Embeddings
Les Embeddings sont des vecteurs de haute dimension qui capturent le sens sémantique des mots, des phrases ou même des documents entiers. Convertir un texte en embeddings permet aux modèles LLMs d’effectuer diverses tâches de traitement du langage naturel, telles que la génération de texte, l’analyse de sentiment, etc. Dans l’exemple ci-dessous, la phrase est transformée en vecteurs de haute dimension.

Les embeddings permettent de représenter les documents, les phrases ou les mots dans des espaces vectoriels où la distance est une mesure de proximité sémantique. Dans l’exemple ci-dessous, les mots « walked » et « walking » sont proches entre eux, et il en va de même pour « swam » et « swimming ».

LangChain permet d’instancier, et d’utiliser en inférence différents modèles d’embedding. Par exemple, ici on utilise le modèle d’embediding Ada qui a été déployé dans une ressource Azure OpenAI :

Vector Store : la pièce maîtresse dans un RAG
Le Vector Store est un type de base de données spécifique au stockage des données types vecteur. Une requête à ce type de base de données remonte les éléments les plus similaires qui matchent la requête demandée. Cette faculté est due aux algorithmes types Approximate Nearest Neighbor (ANN).
Ci-dessous, une architecture RAG où le Vectore Store est Azure AI Search :
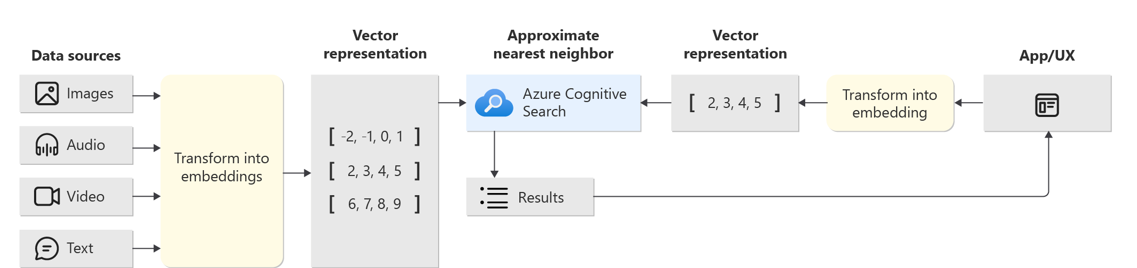
Le framework LangChain offre une implémentation pour intégrer facilement Azure AI Search :

Transformers
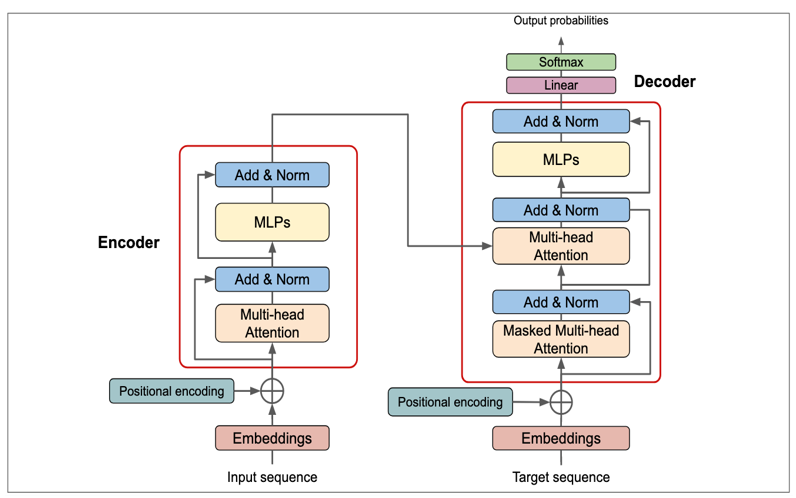
L’architecture des Transformers est une approche révolutionnaire dans le domaine du traitement du langage naturel (NLP). Cette architecture, développée par Google, se base sur le mécanisme d’attention proposé en 2017 dans la publication Attention Is All You Need. Les mécanismes d’attention permettent aux Transformers de capturer les relations entre les différentes parties d’une séquence. Ils fonctionnent en calculant l’importance de chaque élément de la séquence par rapport à tous les autres éléments, puis en utilisant ces poids pour pondérer les représentations lors de la génération des sorties.
L’architecture des Transformers se compose principalement de plusieurs éléments :
Encodeur
L’encodeur prend en entrée une séquence de tokens (par exemple des mots) et la transforme en une série de représentations intermédiaires. Ces dernières capturent des informations à différents niveaux d’abstraction sur la séquence. Pour ce faire, l’encodeur utilise des mécanismes d’attention qui permettent à chaque position dans la séquence de prendre en compte les autres positions lors de la génération de ces représentations.
Décodeur
Le décodeur prend en entrée la représentation intermédiaire générée par l’encodeur, ainsi que la séquence cible, et produit une prédiction. Comme l’encodeur, le décodeur utilise également des mécanismes d’attention.
Multi-Head Attention
Le mécanisme de Multi-Head Attention étend le concept d’attention en permettant au modèle d’apprendre différentes représentations attentionnelles en parallèle. Au lieu d’avoir une seule tête d’attention, le modèle en a plusieurs. Chaque tête d’attention est une pondération différente des relations entre les éléments de la séquence. En utilisant plusieurs têtes d’attention, le modèle peut apprendre à capturer différentes nuances et relations dans les données, ce qui améliore sa capacité à comprendre et à générer du texte de manière plus précise.
Masked Multi-Head Attention
Identique au Multi-Head Attention, la différence est l’ajout d’un masque qui va forcer la partie Décodeur à se focaliser uniquement sur les tokens présents, et ne pas accéder aux tokens futurs (contrairement à la partie Encodeur, où l’attention est calculée sur toutes les paires de tokens ), d’où vient la nature autorégressive des Décodeurs.
Couches résiduelles et normalisation de couche
Pour faciliter l’entraînement de réseaux de neurones profonds, les Transformers utilisent des couches résiduelles qui permettent à l’information de contourner certaines couches du réseau. De plus, la normalisation de couche est utilisée pour stabiliser et accélérer l’apprentissage en normalisant les activations de chaque couche.
Positional Encoding
Les Transformers n’ont pas de notion intrinsèque d’ordre dans les séquences. Pour prendre en compte la position des éléments dans la séquence, ils utilisent donc un encodage de position qui est ajouté aux Embeddings des mots. Cela permet au modèle de distinguer l’ordre des éléments dans la séquence.
Si vous êtes intéressé par la partie Deep Learning on vous invite à consulter notre article « Smart Business : repenser le business de votre entreprise avec l’IA, le Machine Learning et le Deep Learning ».
Il existe des modèles LLM avec l’architecture :
- encoder-decoder comme BART (Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension)
- encoder only comme BERT (Bidirectional Encoder Representations from Transformers)
- et decoder only comme GPT (Generative Pre-trained Transformer)
En tant qu’ingénieur IA, vous n’allez pas vous « embêter » à implémenter toute l’architecture des Transformers, mais plutôt consommer une API qui a été conçue et préparée à l’utilisation. Ci-dessous un exemple avec Langchain et Azure OpenAI :

RAG Evaluation avec Ragas
Ragas est un framework permettant l’évaluation des LLMs ainsi que les systèmes RAG. Le terme “RAG” désigne une classe d’applications de modèles LLM qui utilisent des données externes pour enrichir leur contexte. Bien qu’il existe des outils pour construire les RAG, évaluer et quantifier leurs performances peut être difficile. C’est là que Ragas intervient.
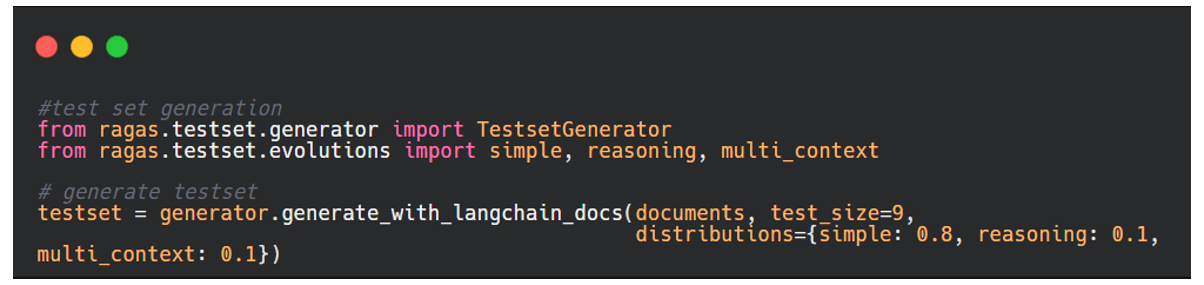
Initialement, on prépare un dataframe de test constitué des colonnes suivantes : questions, réponses générées par le RAG, les bonnes réponses souhaitées (ce qu’on appelle ground_truth) et les contextes qui servent en principe à générer les bonnes réponses. Ragas offre la possibilité de générer les questions d’une manière automatique à partir d’un set de documents. À l’aide de Ragas, on peut aussi personnaliser le nombre des questions, et leur distribution.
Le code ci-dessus permet de générer un dataframe de test comme celui-ci :
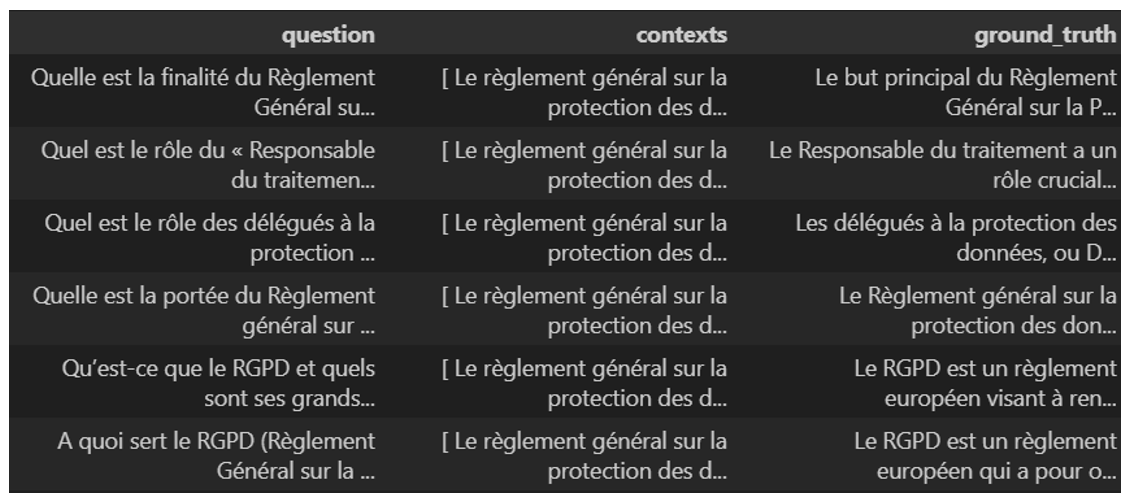
Il est recommandé d’alimenter la colonne ground_truth d’une manière manuelle à l’aide de l’expertise du métier.
Pour faire l’évaluation, il faut convertir le dataframe en type dataset, et utiliser la classe evaluate, comme dans le code ci-dessous.

Ci-dessous, un exemple d’un extrait des résultats de l’évaluation :

Nous avons utilisé quatre métriques d’évaluation :
- Faithfulness : mesure la cohérence factuelle de la réponse au contexte en fonction de la question.
- Context_precision : mesure la pertinence du contexte récupéré par rapport à la question, transmettant la qualité du pipeline de récupération.
- Answer_relevancy : mesure la pertinence de la réponse par rapport à la question.
- Context_recall : mesure la capacité du récupérateur à récupérer toutes les informations nécessaires pour répondre à la question.
Architecture technique simplifiée
Pour la mise en place de ce système, nous avons démarré petit :
- une ressource Azure OpenAI pour utiliser les modèles embeddings (Ada) et LLM (GPT 3.5 turbo).
- un blob storage pour classifier nos documents (ça peut être un autre service de stockage ADLS, SharePoint, etc.), chunking des documents avec Azure AI Search, et stockage des embeddings dans la partie Vector Store.
- Developpement avec Python, création UI avec Streamlit, gestion des dépendances avec Poetry et Packaging avec Docker pour la création d’une image Docker du projet. Cette image est stockée dans un Azure Container Registry, et ensuite utilisée par Azure WebApp pour déployer l’application web. L’intégration de cette application peut être aussi faite sur un canal Teams avec le Service Azure Bot.
La gestion des clés de ressource est assurée par Key Vault, mais on peut utiliser Azure Managed Identity qui va encore nous simplifier cette partie de gestion des clés. Azure Devops est utilisé pour assurer une CI/CD efficace, App Insight pour analyser les logs de notre application, ConsosDB si jamais on a envie de garder l’historisation des conversations et le contenu des documents. Enfin, Azure Functions pour faire des pipelines d’ingestion de documents, d’orchestration et update du Vector Store.

Aller plus loin
On peut aller encore plus loin en adoptant une architecture type Zero-Trust, en rajoutant une couche de sécurité se basant sur des vnets, subnets, private links et firewall comme ci-dessous :
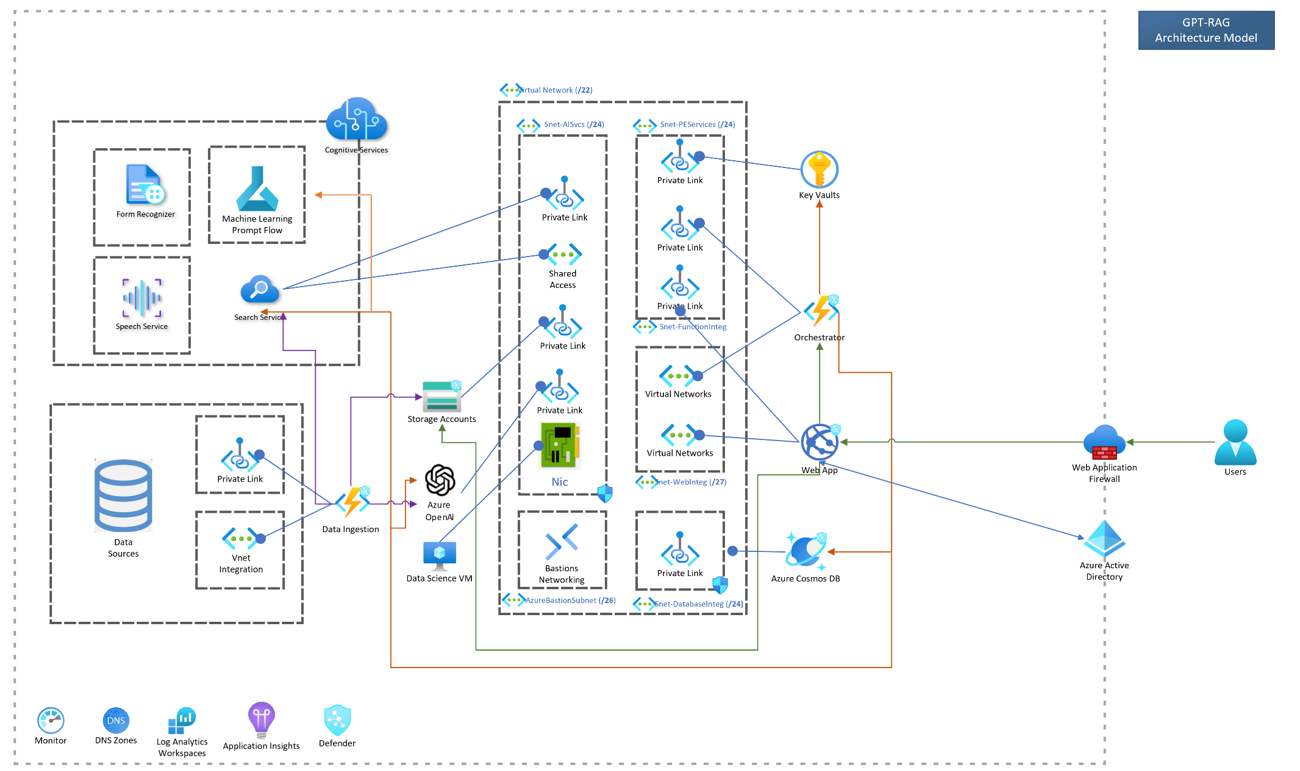
Ce qu’il faut retenir sur la classification des données
- La classification des données est une tâche critique dans l’entreprise, qui est parfois gérée d’une manière artisanale.
- Le RGPD est la responsabilité de tout le monde, et pas uniquement des juristes ou du DPO. Même un développeur doit connaître un minimum les enjeux liés à cette réglementation.
- LangChain est un framework de développement pour les applications IA Générative.
- Faire des applications GenIA c’est bien, les évaluer c’est mieux !
- Démarrer petit pour une meilleure maîtrise FinOPS du projet.
Si vous êtes intéressé par plus de contenus sur la sécurité dans le domaine de l’Intelligence Artificielle on vous conseille vivement à consulter ces articles rédigés par nos experts :
- Smart Business / MLSecOps : comment la sécurité doit-elle accompagner les projets de Machine Learning ?
- Sécurité de l’IA : sécuriser les données pendant le traitement et le stockage






