

Comment RAJA Group a construit une plateforme data unifiée avec Microsoft Fabric – et comment Cellenza a contribué à écrire...
13 septembre 2022
Read this post in English
Smart Business : repenser le business de votre entreprise avec l’IA, le Machine Learning et le Deep Learning

Le Deep Learning (DL), ou « apprentissage profond », fait partie des sujets les plus attrayants dans le monde de l’Intelligence Artificielle (IA). C’est un domaine intéressant qui, par ses résultats prometteurs, a pu attirer une grande attention des praticiens de l’IA.
Grâce à l’avancée du Big Data mettant à disposition une énorme quantité de stockage et de grande force de processing des données (due entre autres aux progrès des ressources de calculs – GPU & TPU), le Deep Learning est devenu omniprésent. Il est utilisé dans plusieurs domaines tels que la composition de musique, la création d’œuvres d’art, la reconnaissance des objets, le traitement du langage naturel, la recherche médicale, etc.
Le but principal de cet article est de présenter, comprendre et vulgariser le Deep Learning : quel est son fondement de base ? Qu’est-ce qui le différencie du Machine Learning classique ? Nous allons également détailler certaines architectures les plus connues et évoquer brièvement des best practices dans l’adoption des technologies IA au sein d’une entreprise.

Deep Learning / Machine Learning vs programmation traditionnelle
Avant de rentrer dans le vif du sujet, nous allons répondre à la question que beaucoup de gens se posent : qu’est-ce qui fait la différence entre un moteur de règles (programmation classique if-else) par rapport aux fameux Deep Learning (DL) & Machine Learning (ML) ?
Dans la programmation classique, dite « traditionnelle », on fait la combinaison des informations d’entrées (inputs) avec un ensemble défini de règles (des règles de gestion, par exemple) pour avoir le résultat escompté (outputs). Cependant, dans le Deep Learning/Machine Learning, on fournit les entrées et les sorties tandis que les règles sont déduites dans la phase d’entrainement (training) des modèles.

Qu’est-ce que le Deep Learning ?
Avant tout, le Deep Learning est un paradigme de Machine Learning (ML). Il se base sur l’utilisation des Réseaux de neurones (Neural Networks NN). Leur rôle est d’extraire automatiquement les caractéristiques (features) et patterns déduits des données brutes.
Qu’est-ce qu’un réseau de neurones artificiel ?
Un réseau de neurones est un ensemble de neurones, inspiré du fonctionnement du cerveau humain, pour extraire et apprendre des informations. Ces neurones peuvent être empilés les uns sur les autres, formant ainsi des couches, ce qui leur donne une certaine profondeur, d’où le terme de Deep Learning.
Ci-dessous une illustration d’un réseau de neurones, contenant deux couches cachées.
A noter : pour parler d’un réseau de neurones profond, il faut au moins trois couches cachées.

Qu’est-ce qu’un neurone artificiel ?
Un neurone artificiel, appelé aussi perceptron, est la plus petite unité dans un réseau de neurones. Ci-dessous une comparaison entre un neurone biologique vs un réseau de neurones artificiels.

Le perceptron se compose de :
- Couche d’entrée (xi = Inputs)
- Poids (wi)
- Somme (xi * wi)
- Fonction d’activation
- Output
Quelle est la date de conception du Deep Learning ?
Maintenant qu’on a une idée plus claire sur le Deep Learning, les réseaux de neurones et les perceptrons, est-ce que vous vous êtes posé la question de la date de leur conception ?
La première conception du fonctionnement des neurones remonte à 1943 et la première théorisation du Deep Learning date des années 1980, mais ce n’est que récemment que le Deep Learning est devenu utilisable, car il nécessite de grandes quantités de données et de calculs (GPU / TPU).

Type de carte graphique utilisé dans l’entrainement des réseaux de neurones
Deep Learning vs Machine Learning
Le Machine Learning est un bon moyen quand on a un petit dataset avec des données qui ont été soigneusement préparées, ou quand on veut rapidement avoir un modèle basique.
Les différences entre le Deep Learning et le Machine Learning sont nombreuses : le Deep Learning se base sur des réseaux de neurones, ce qui n’est pas le cas dans la plupart des algorithmes Machine Learning. De plus, l’étape feature extraction y est automatique, alors que le Machine Learning demande une intervention humaine pour la création des vecteurs de caractéristiques (descripteurs de données) représentants la data brute.
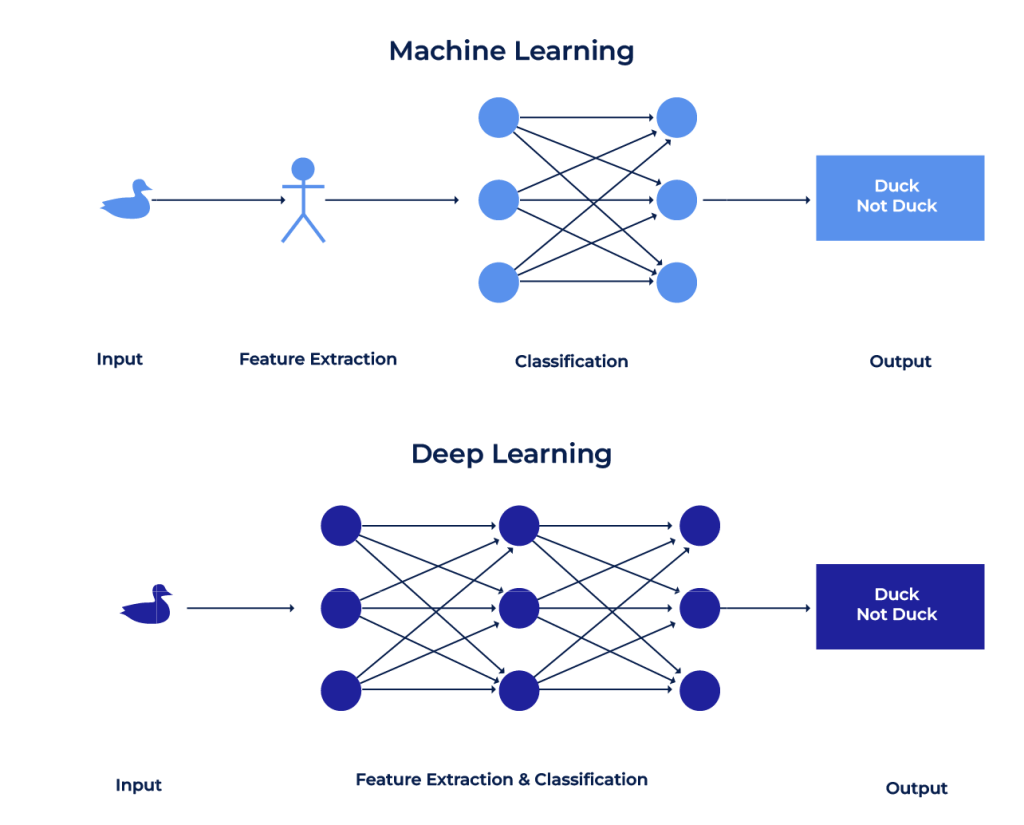
Quand on fait du Machine Learning (ML), on remarque que si le dataset est complexe, les algorithmes Machine Learning classiques peinent à extraire des informations pertinentes pour apprendre. Ce phénomène est connu sous le nom de « malédiction de la dimension » (curse of dimentionality). Afin d’y remédier, on a recours aux méthodes de réductions de dimensions telles que la PCA, LDA, ICA, etc.
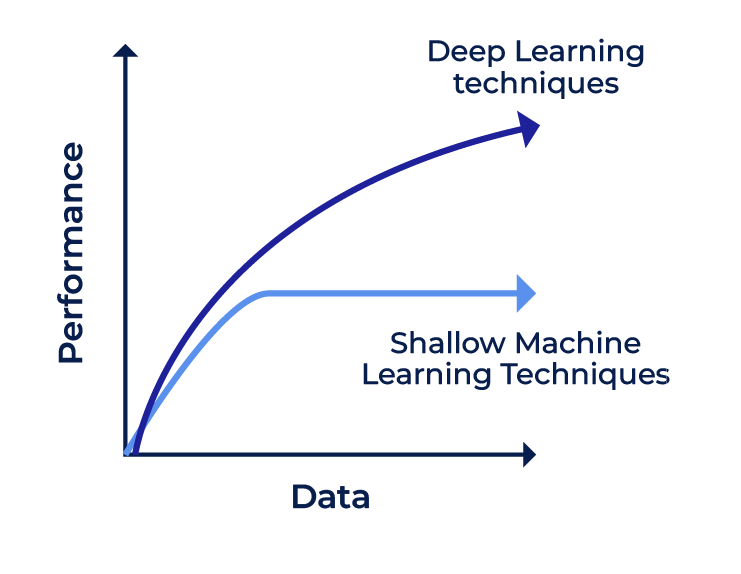
Observons ci-dessous une comparaison de la performance de précision entre Deep Learning et Machine Learning par rapport à la quantité de la data. Cette illustration n’est pas toujours vraie ; en réalité, il faut faire des expérimentations de plusieurs méthodes et algorithmes afin de choisir une solution finale, tout en faisant attention à la qualité des données, dont dépendent fortement les résultats.
Si vous souhaitez une introduction à l’Intelligence Artificielle et au Machine Learning, nous vous invitons à consulter les articles de notre CTO Yann Bilissor:
- Intelligence Artificielle / Machine Learning : de la perception à l’action
- IA / Machine Learning : créer des agents intelligents
Quels sont les types de réseaux de neurones ?
Convolutional neural networks (CNNs)
Les réseaux de neurones de convolutions (CNNs) sont utilisés généralement pour la vision par ordinateur et l’analyse d’image. Ils ont montré leur efficacité dans l’analyse et la modélisation des données spatiales telles que les images et vidéos en 2D ou 3D par rapport aux méthodes classiques (feature descriptors comme : SIFT, FAST, SURF, etc.) qui nécessitent l’intervention humaine pour une meilleure représentation de la donnée.
Un réseau CNN se forme d’une partie de convolution et d’une autre de classification. La partie de convolution a pour objectif d’extraire les caractéristiques de chaque image par l’application d’un ensemble de filtres sur l’intégralité de l’image et la partie de classification utilise les résultats des opérations de convolutions afin de mieux classifier l’image en entrée.
Il existe différentes architectures de réseaux CNNs comme :
- AlexNet
- VGGNet
- ResNet

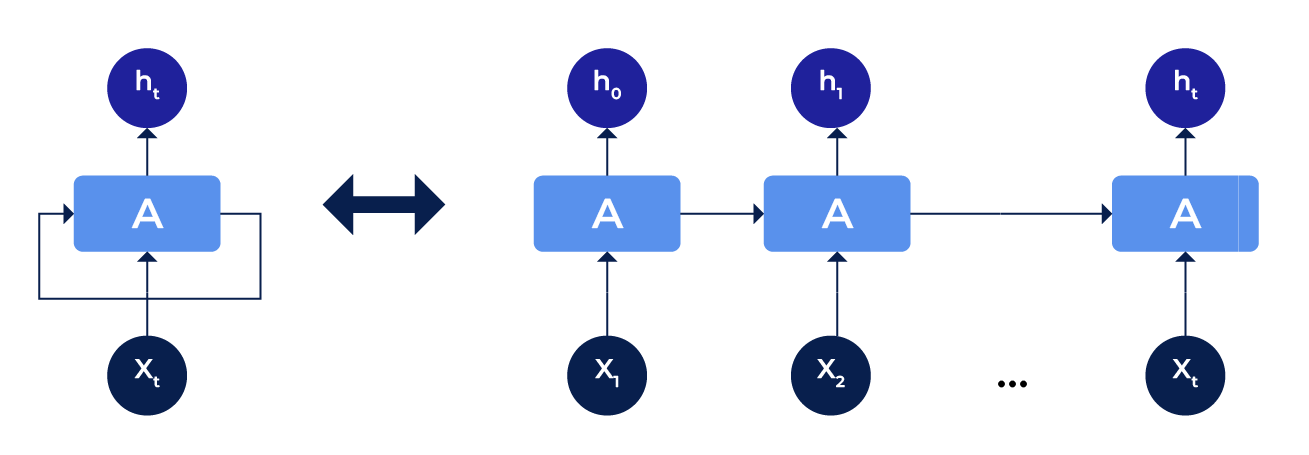
Recurrent neural networks (RNNs)
Les réseaux de neurones récurrents (RNNs) sont utilisés principalement pour la modélisation des données séquentielles comme le texte, l’audio, les séries temporelles, etc. Ils sont souvent utilisés dans des tâches d’analyse du texte (NLP).
Les réseaux de neurones classiques ont été conçus pour des points de données qui sont indépendants les uns des autres. Cependant, si nous avons des données en séquence, où un point dépend du point précédent, les NN classiques ne vont pas réussir à extraire la bonne information. De ce fait, les RNNs ont été créés pour incorporer les dépendances entre ces points de données. Ils ont une faculté de « mémorisation » qui les aide à stocker les états ou les informations des entrées précédentes pour générer la prochaine sortie de la séquence.
Il existe différentes architectures de réseaux RNNs comme :
- Bidirectional recurrent neural networks (BRNN)
- Gated Recurrent Units (GRU)
- Long Short-Term Memory (LSTM)

Generative Adversarial Networks (GANs)
Les Réseaux antagonistes génératifs (réseaux adverses génératifs) font partie des algorithmes non supervisés. L’utilisation de ces réseaux de neurones est différente et ils ne sont pas utilisés pour l’analyse de données classique telle que la classification, où l’on essaye de discriminer au mieux les classes de données. Les GANs, pour une classe de données, cherchent à générer des données similaires.
Concrètement, l’architecture des GANs est composée de deux réseaux de neurones en compétition. Le Générateur génère de nouvelles données, et le Discriminateur tente de détecter si les données produites sont originales ou créées par son « adversaire » le générateur.
Il existe différentes architectures de réseaux GANs telles que :
- CycleGAN
- StyleGAN
- DiscoGAN

Transformers
Les Transformers sont les « rockstars » actuelles du Deep Learning. Ils ont réussi à remplacer les réseaux de neurones récurrents RNN (LSTM & GRU) dans le traitement du langage naturel. De plus, ils sont maintenant utilisés pour la vision par ordinateur et vont peut-être remplacer définitivement les réseaux de neurones de convolutions (CNN).
Créé en 2017, un transformer est un réseau de neurones de type séquence à séquence (seq2seq), contenant une partie Encodeur et une autre Décodeur et se basant sur l’auto attention (self-attention). Ce type de réseau n’exige pas que les données séquentielles soient ordonnées, ce qui le rend parallélisable et beaucoup plus rapide à l’entrainement, par rapport aux RNNs classiques.
Il existe différentes architectures des Transformers comme :
- BERT
- GPT-3
- RoBERTA

Deep Learning et Machine Learning pour votre business et votre organisation
Bien exploités, le Deep Learning et le Machine Learning peuvent être des accélérateurs de modernisation de votre business. Ils nous permettent d’avoir une meilleure vision et nous permettent d’identifier de nouvelles opportunités.
Avec le Deep Learning/Machine Learning, on peut accélérer certaines tâches répétitives et ennuyeuses pour les employés. En même temps, une assistance par l’Intelligence Artificielle permet la réduction du taux d’erreur, donne plus de confiance aux utilisateurs et renforce l’expérience client.
Utiliser de l’IA dans son business ou son organisation ne veut pas dire se passer des personnes pour léguer un total contrôle à une application. On est bien loin de cela ! Néanmoins, on peut utiliser l’IA comme une assistance pour effectuer notre travail au mieux et surtout pour nous concentrer et nous focaliser sur le cœur du business et les points les plus critiques.
A l’heure actuelle, une entreprise peut facilement adopter des solutions IA, surtout avec les multiples produits offerts par les plus grands Cloud providers comme Microsoft Azure Cloud, Amazon Cloud et Google Cloud, chacun d’eux proposant des offres personnalisées et sur mesure. Par exemple, une entreprise qui a assez de recul sur l’IA et a les compétences nécessaires peut s’offrir une plateforme Machine Learning comme Azure ML Service qui permet la gestion, le contrôle et l’accélération du cycle d’un projet ML (ce qui est connu sous le terme MLOps, c’est-à-dire l’industrialisation des projets ML) mais surtout de permettre aux data scientists de se focaliser sur leurs tâches.
Généralement, la plupart des data scientists viennent d’un background purement académique (ingénieurs / docteurs) et l’on remarque parfois un manque des bonnes pratiques liées au Software engineering comme le clean code, clean architecture, TDD, DevOPs (CI/CD), etc. ce qui peut induire au mauvais déroulement d’un projet DL/ML. Bien sûr, un data scientist ne doit pas tout faire (quoique… il est toujours positif de s’ouvrir et d’apprendre d’autres compétences, vu l’évolution de la Data Science), et pour cela il faut avoir les bons outils mais surtout construire des équipes complètes avec différents profils :
- Équipe data platform
- Équipe Dev
- Équipe data science
- Équipe ML platform
- Équipe Sales
- Équipe Product
- Manager
Un autre exemple est le cas d’une entreprise qui veut adopter des solutions IA mais qui n’a pas assez de compétences dans ce domaine. Elle peut faire appel à l’utilisation des APIs de services IA, qui pourront être intégrées dans n’importe quelle application. L’intégration de ces APIs ne nécessite pas de forte expertise dans l’IA et avec des compétences de Dev, on peut les mettre en place.
Microsoft Azure Cloud propose Azure Cognitive Services qui offre une panoplie de services pour traiter des différentes thématiques telles que :
- La vision
- La parole
- Le langage
- etc.

Azure Cognitive Services (Source : Documentation Microsoft)
Si vous souhaitez du contenu sur comment faire de l’IA sans Data scientist, nous vous invitons à visionner l’intervention de notre Digital Advisor, Nicolas Robert, et de Justine Charley, Architecte et Data Scientist, chez Microsoft lors de la Microsoft Build 2022 : « Comment embarquer de l’IA dans vos projets sans avoir une équipe de DataScientists? »
Deep Learning et Machine Learning en entreprise et dans la recherche
Le Deep Learning/Machine Learning en entreprise est différent de la recherche. Brièvement, en entreprise (en production) on a des différentes parties prenantes, on veut un service avec un temps d’inférence rapide et une latence la plus basse possible. Les données changent constamment (Data Shifting) et surtout il faut que le livrable soit dans les normes de l’IA Responsable. Toutefois, dans la recherche on veut un modèle avec une performance proche des performances dans l’état de l’art (SOT) : on cherche beaucoup plus l’optimisation du temps d’entrainement, les données sont statiques. Généralement on utilise des datasets benchmark et on porte peu d’importance à la partie IA Responsable (on est beaucoup plus dans l’innovation pure).
Comme vous pouvez le constater, les conditions et les objectifs dans les deux mondes sont très différents. On voit clairement que l’application des systèmes IA en entreprise est plus challengeant : on estime que 80% des projets ne franchissent pas l’étape POC, mais avec la mise en place des pratiques MLOps on remarque une nette amélioration. Toutefois, certaines pratiques et habitudes peuvent nuire à l’avancement d’un projet ML, comme le fait de s’oublier dans l’amélioration des métriques des modèles et essayer coûte que coûte d’avoir une meilleure précision et monter de 0.4% de précision, en utilisant de grandes ressources de données, de calculs et plus de temps. Malheureusement, les entreprises s’intéressent peu aux algorithmes utilisés et aux métriques ajustées sauf s’il y a un impact sur les métriques business, ce qui est plus important et concret pour les managers. Qu’on le veuille ou non, sans gain de profit, n’importe projet ML va être arrêté parce qu’il ne rapporte pas de plus-value.
De ce fait, en tant que data scientists, nous devons comprendre les vrais challenges business, le but final d’un projet et surtout, lier les métriques d’algorithmes aux métriques business de l’entreprise et trouver un bon compromis.
Cela ne veut pas dire qu’on n’a pas droit de « s’éclater » et d’utiliser les dernières technologies, mais cela implique d’être plus raisonnable et mature, en commençant par des petites briques et monter crescendo afin de ne pas louper le but du projet (commencer par un modèle classique ou faire du transfer learning).
L’IA Responsable
L’IA responsable est un sujet critique et complexe : on pourrait lui consacrer des articles voire des livres entiers ! En quelques mots, l’IA responsable est la conception, la création et l’industrialisation d’un produit IA avec une bonne intention et beaucoup de sérénité, afin d’assurer un impact positif sur les individus et les sociétés, sans discrimination ou injustice. Dans la littérature, on trouve plusieurs définitions et principes et dans cet article, nous vous présentons les principes de Microsoft pour une IA responsable :
- Équité (Fairness)
- Fiabilité et sécurité (Reliability and safety)
- Confidentialité et sécurité (Privacy and security)
- Inclusion (Inclusiveness)
- Transparence (Transparency)
- Responsabilité (Accountability)

Intelligence Artificielle Responsable par Microsoft (Source : Documentation Microsoft)
Si vous souhaitez plus d’information sur la gestion du cycle de vie d’un projet Machine Learning respectant les principes de l’IA responsable, vous pouvez consulter l’article de de Nathalie Fouet, notre experte Legal Data : Run d’un projet IA : garder sous contrôle le cycle de vie d’un modèle ML.
Si vous souhaitez une introduction à la sécurité de l’IA, notre CTO Smart business Yann Bilissor a écrit un article sur le thème : Sécurité de l’IA : sécuriser les données pendant le traitement et le stockage
Applications du Deep Learning / Machine Learning
On peut utiliser l’Intelligence Artificielle dans n’importe quel domaine de la vie à travers l’application des techniques Deep Learning / Machine Learning, comme le montrent les quelques exemples ci-dessous :
- Assurance : automatisation du traitement des réclamations des clients. Azure Cognitive Services propose un service de « Sentiment analysis » qui nous permet de calculer le degré de satisfaction des clients.
- Finance : personnalisation du service client et lutte contre la fraude et le blanchiment d’argent. Azure Cognitives Service propose Anomaly Detector qui embarque facilement la capacité de détecter des anomalies sur des données time-series.
- Santé : amélioration des soins et favorisation de la médecine préventive, amélioration de la rapidité et la précision des diagnostics.
- Réseaux sociaux : hyper personnalisation des contenus.
- Automobile : véhicules électriques et autonomes.
A noter : Pour les cas où l’on a besoin d’un contrôle total des algorithmes Deep Learning/Machine Learning, Azure Cloud offre Azure Machine Learning service et Azure Databricks où l’on peut utiliser des frameworks de développement comme TensorFlow, PyTorch et Scikit-learn.
Deep Learning/Machine Learning : une technologie puissante
Le Deep Learning/Machine Learning est clairement une technologie puissante pour la transformation de n’importe quel business. Néanmoins, son adoption peut sembler compliquée, mais faut pas avoir peur vis-à-vis de l’IA, car avec les services IA proposés par les Cloud providers et l’émergence de nouvelles pratiques autour de la data et le ML/DL, l’adoption de ces solutions peut se faire aisément. Nous conseillons donc de toujours démarrer petit à petit, et d’intégrer cette nouvelle brique graduellement dans votre business ou organisation sans un énorme investissement afin de comprendre comment vous pouvez en bénéficier.
Vous souhaitez être accompagnés dans vos projets de Smart Business, d’IA ou de ML ? N’hésitez pas à consulter nos offres de services :






