

Juin c’était le mois de la solidarité et de l’engagement ! Chez Cellenza, on a participé au challenge « Défie la...
9 août 2022
Industrialisation des solutions d’Intelligence Artificielle

Chaque année, les experts Cellenza partagent leur vision sur les tendances technologiques et sectorielles à suivre au cours des prochaines années. Ces tendances sont compilées dans la Tech’Vision de Cellenza. l’industrialisation des solutions d’IA fait partie de ces tendances à suivre : nous vous proposons de la découvrir.
La création d’outils basés sur l’intelligence artificielle nécessite une vision « produit » et un cycle de vie plus complexe qu’un développement classique. L’état de l’art des technologies autour de l’intelligence artificielle (IA) se renouvelle à une fréquence inédite : on construit aujourd’hui des solutions dont la durée d’exploitabilité est réduite à quelques mois du fait de l’arrivée future de nouveaux modèles. En se contentant de lancer ces solutions sans suivi, on ne crée finalement que des POCs (proof-of-concept).
Sortir de ce développement artisanal passe par l’adoption de nouveaux outillages, l’inclusion de nouveaux rôles et la création d’une gouvernance de la donnée et des modèles.
L’intelligence artificielle, source de nombreux défis
L’intelligence artificielle commence à prendre une part de plus en plus grande dans les projets logiciels. Contrairement au développement classique basé uniquement sur du code, on combine ici trois facteurs : données, modèles et code.
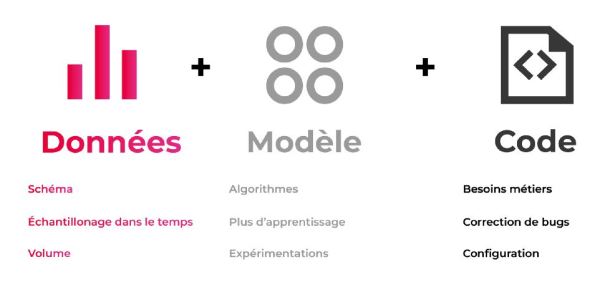
Ces deux facteurs supplémentaires doivent apporter de nouvelles réflexions sur le plan fonctionnel : que l’on parle de solutions utilisant du traitement du langage, de la vision par ordinateur ou encore de l’analyse prédictive, on rencontre une problématique commune propre à l’intelligence artificielle : celle de l’IA « responsable ». Elle se décline en différentes catégories : l’éthique, la transparence, le respect de la vie privée ainsi que l’impartialité.
En complément, des défis techniques apparaissent : découvrir et accéder aux données, entrainer des modèles de manière reproductible, servir un modèle, tester, déployer. Enfin, il est capital de s’assurer de mettre en place des solutions de monitoring et d’observabilité, qui sont fréquemment oubliées une fois qu’un modèle acceptable a été trouvé.
Comment industrialiser l’usage de l’intelligence artificielle pour sortir d’un mode de construction très artisanal et répondre à ces multiples défis ? Beaucoup d’entreprises se sont lancées dans l’exploitation de l’intelligence artificielle sans anticiper ces éléments et leur impact. Sur le plan technique, ils induisent la création d’outillage spécifique et une montée de compétences des équipes. Sur le plan organisationnel, ils nécessitent un travail important sur la gouvernance, mais aussi sur la structuration des équipes au profit d’une meilleure collaboration.
Des métiers différents du développement classique
Créer une solution basée sur un modèle sur mesure nécessite de nombreuses compétences. Il ne suffit pas de recruter un data scientist, sous peine de se retrouver avec le cas désormais classique du modèle qui ne tourne qu’en environnement de test et sur lequel on passe plus de temps à tenter de l’industrialiser et déployer qu’il n’en a fallu pour le créer. Parfois, le modèle est bien déployé jusqu’en production, mais au travers d’un lot d’actions manuelles, ce qui le rend inmaintenable.
Le travail de création d’une solution basée sur du Machine Learning est pluridisciplinaire et impose une bonne coordination. Ainsi, on passe d’un lot de connaissances personnelles à un réel fonctionnement d’équipe combinant data engineering, data science, ML engineering, développement traditionnel et suivi opérationnel.
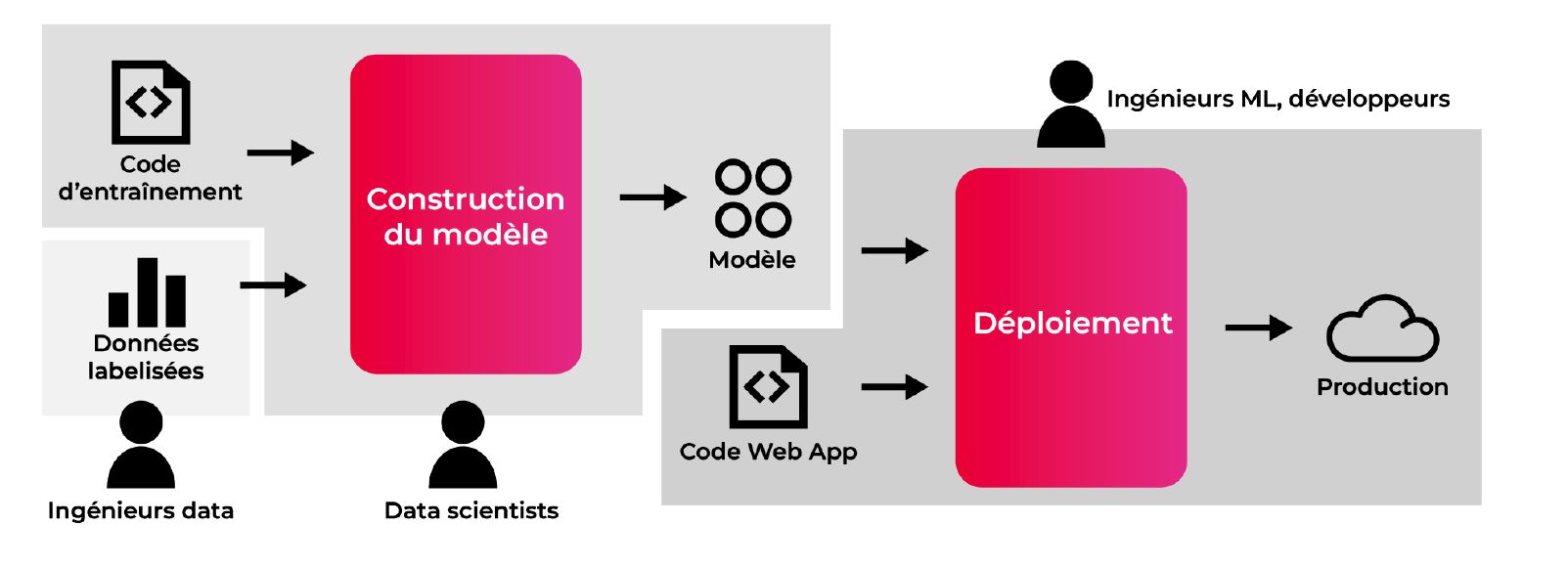
Cette équipe se compose de différents rôles : certains comme celui du data engineer – en charge de la donnée alimentation, nettoyage, application de labels – ou du data scientist – en charge de l’exploitation de la donnée – sont devenus classiques à l’ère du big data. D’autres sont apparus récemment sur le marché, comme celui de « Machine Learning engineer ». Ce rôle a pour vocation d’accompagner les équipes dans l’industrialisation de la démarche : cela passe par la fourniture d’outils pour guider les data scientists dans la réalisation d’expérimentations et la création de modèles, et l’accompagnement des développeurs pour créer les services qui exposent ces modèles. Enfin, ils doivent être garants du fonctionnement opérationnel de l’ensemble.
En termes de compétences, le Machine Learning engineer se retrouve donc à la croisée des chemins entre data scientist, développeur traditionnel et profil opérationnel : il doit comprendre l’analyse de la donnée en amont, savoir coder pour réaliser les modèles ML, mais aussi appliquer les principes DevOps (pipelines, CI/CD, automatisation) en y ajoutant la couche de complexité complémentaire liée au Machine Learning : en synthèse, il maitrise l’approche « ML Ops » que l’on détaillera plus loin.
L’intégration de ce rôle dans les équipes est cruciale pour garantir une meilleure historisation de la phase amont (en évitant le travail en local du data scientist), une accélération du délai de déploiement des modèles et une meilleure mise à l’échelle.
De la gouvernance et des outils adaptés aux nouvelles problématiques
Construire un modèle basé sur du Machine Learning ne repose pas uniquement sur un lot de compétences techniques individuelles. Au-delà des profils techniques, la vision produit est cruciale et doit être portée à un niveau transverse dans l’entreprise. En effet, la réalisation de ces solutions est complexe :
- Elle nécessite d’importantes quantités de données qualitatives et consolidées grâce à des connaissances fonctionnelles inter-domaines ;
- Elle utilise de coûteuses puissances de calcul pour la phase d’entrainement, et parfois également pour l’exécution (par exemple pour des modèles basés sur des unités de traitement graphiques – GPU).
L’organisation de la capitalisation, du partage et de la restitution sont des éléments clés pour accélérer l’implémentation et limiter les coûts des réalisations.
Gouvernance de la donnée
En amont du processus de Machine Learning, les données doivent être qualifiées et documentées. Cela passe par la création d’un data catalog et l’introduction de rôles adaptés autour de la gouvernance des données qui y sont référencées avec notamment les data owners et data stewards. A l’aide de cet outil, on peut rapidement identifier les données disponibles, leurs caractéristiques ainsi que leur cycle de vie lorsque le data lineage (traçabilité des données) a été mis en place. La visualisation des propriétés des lots de données permet également de lutter plus efficacement contre l’insertion de biais dans les modèles (qui utilisent ces données pour leur entrainement), en y détectant en amont des caractéristiques qui sont amenées à impacter négativement le futur modèle.
Cette question de maitrise de la donnée résonne également avec celle de l’intégration : comment collecter, analyser, nettoyer la donnée des différentes briques qui composent le système d’information ? Ces thématiques sont de vrais défis au niveau de l’entreprise, en particulier dans des contexte temps réel.
MLOps
L’exploitation des données à l’aide d’apprentissage machine (Machine Learning) s’industrialise au fur et à mesure de son adoption. Depuis de nombreuses années, elle est le fruit de travaux menés individuellement avec un outillage limité. Le manque de versioning des algorithmes élaborant les modèles et le suivi limité des expérimentations rendent le travail chronophage et peu efficace. Au fil du temps, l’extension des sujets et des équipes crée un besoin de partage ainsi que la nécessité d’accéder à une plus grande puissance, offerte aujourd’hui par le Cloud et probablement par l’informatique quantique dans un futur proche. C’est dans ce cadre qu’est née la démarche « ML Ops », inspirée de l’approche « DevOps » que l’on connait dans le cadre de développements agiles.
Les principes du ML Ops en reprennent les aspects « CI / CD » (Continuous Integration / Continuous Deployment) en les appliquant au domaine du Machine Learning : aux pipelines fournissant un comportement reproductible s’ajoutent des étapes complémentaires pour qualifier les données, les performances (précision) et la sélection des modèles à déployer. Ces aspects sont complétés par les notions de « Continuous Training » pour réentrainer fréquemment et automatiquement les modèles et observer les évolutions des performances.
Plus que tout système logiciel classique, le monitoring des outils basés sur du Machine Learning est important. En effet, ces derniers ne sont pas idempotents : une telle solution « vit » après son déploiement et peut être amenée à subir une dérive (« drift ») liée aux données d’entrainement et d’exécution. On déploie alors des solutions de monitoring et des boucles de feedback permettant de récupérer des métriques et données d’utilisation pour ensuite améliorer la performance.
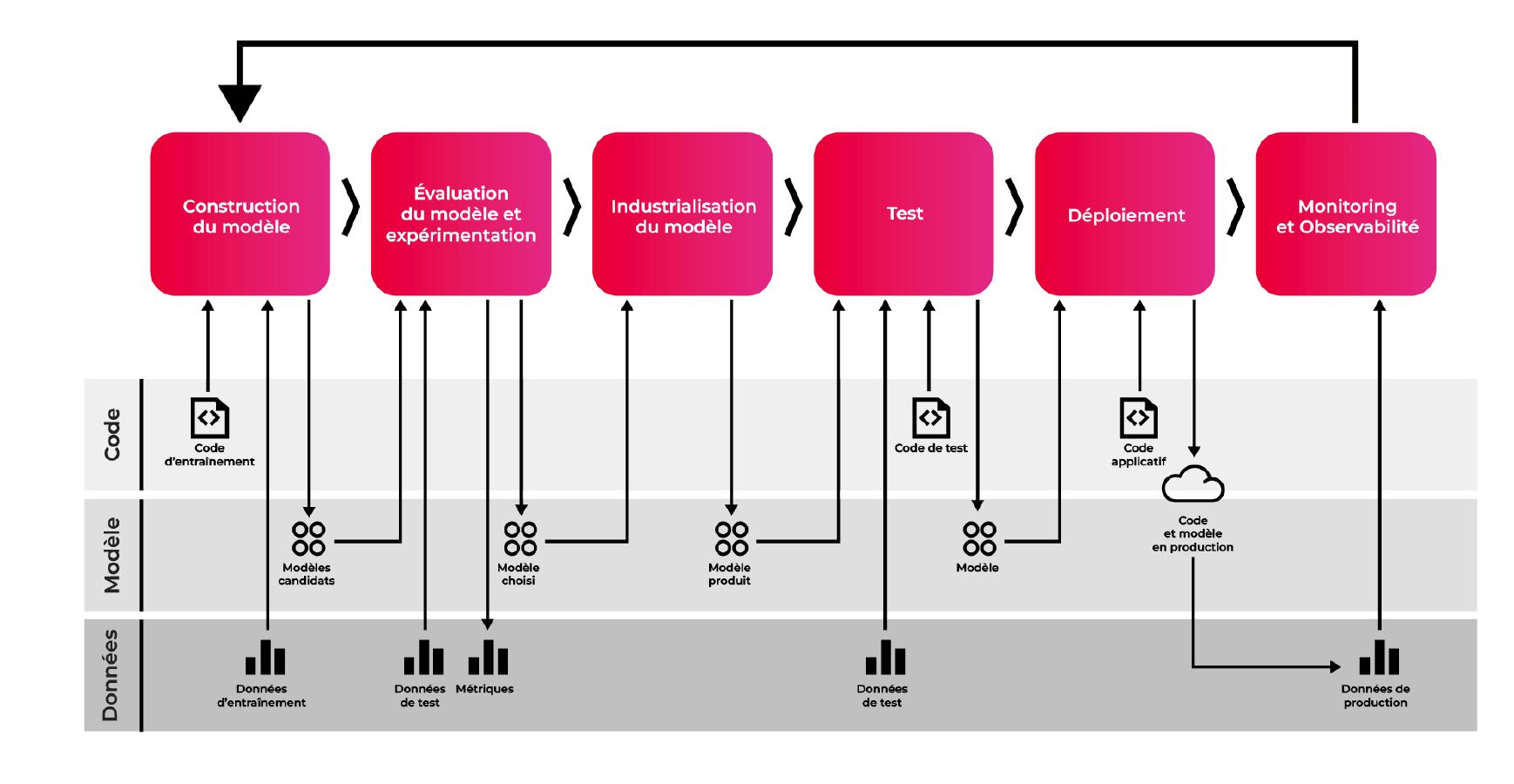
Finalement, on obtient un cycle de vie automatisé de bout en bout où l’intervention humaine reste nécessaire mais limitée à l’analyse des évolutions.
La boîte à outils pour industrialiser la démarche
Dans la boite à outils du ML Engineer, on retrouve des outils dédiés à ces pratiques ML Ops comme MLflow, mais le marché reste encore peu mature. Ils se complètent maintenant avec des solutions dédiées aux problématiques spécifiques de l’intelligence artificielle :
- on retrouve par exemple l’utilisation de « cartes » de modèles (ex : model cards toolkit de Google) afin d’apporter une dimension « transparence » des modèles créés ;
- des outils sont dédiés à l’impartialité des modèles, comme le package Python Fairlearn ;
- des projets comme SmartNoise existent pour améliorer la protection de la donnée privée : ils génèrent du bruit ou ajoutent des éléments aléatoires aux données afin d’empêcher l’identification d’éléments individuels.
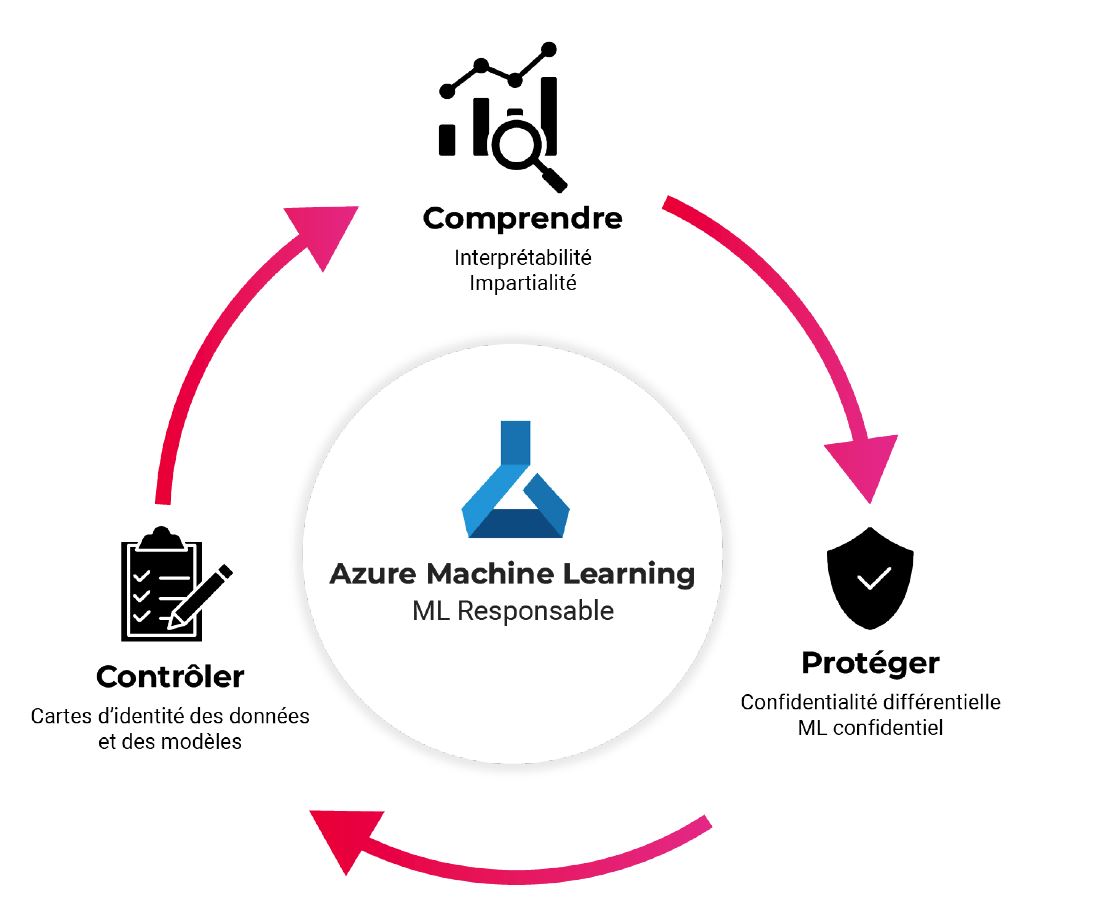
Source : What is responsible machine learning (preview) – Azure Machine Learning | Microsoft Docs
Des défis à relever
Réussir l’industrialisation de projets basés sur l’intelligence artificielle et le Machine Learning consiste à relever différents challenges :
- Arriver à construire une équipe technique pluridisciplinaire, incluant notamment un rôle spécifique de ML engineer, et l’accompagner de responsables produit capables de construire une vision autour des assets basés sur l’intelligence artificielle ;
- Mettre en place une gouvernance de la donnée;
- Déployer des outils accompagnant les équipes pour créer, déployer et suivre leurs modèles ;
- Former les équipes autour de l’« IA responsable ».
La mise en place de ces différentes étapes améliore la capitalisation des assets (data et modèles) et des processus : à terme, la démarche d’expérimentation est accélérée et le délai entre cette phase et la livraison s’en retrouve fortement réduit. Cela favorise également par la suite l’arrivée de nouveaux projets : la donnée est identifiée, disponible et une plateforme est prête à accueillir la conception et l’exposition des futurs modèles ML.






