

Dans la continuité des articles précédents sur la Kubernetes Gateway API, nous explorons aujourd’hui un aspect plus opérationnel de ce...
6 septembre 2022
Read this post in English
GraphQL API : présentation et cas d’usage

Article corédigé par Guillaume David et Nicolas Sotty
Dans le cadre de la modernisation des systèmes d’information, des projets d’APIsation et de mise en place d’architectures Modern Integration, les besoins métiers sont grandissants autour de la gestion des données de nature éparse. Ces dernières ne sont pas forcément stockées aux mêmes endroits, mais doivent être récoltées ou visualisées rapidement et simplement.
Face à ces besoins, les API REST présentent un certain nombre de limitations. Pour pallier cela, une nouvelle façon de penser les APIs a vu le jour : les APIs Graph QL. Microsoft a d’ailleurs intégré à son outil de management d’APIs la possibilité d’ajouter et de gérer des APIs de type Graph QL.
Cet article a pour objectif de dresser une vue d’ensemble de cette « nouvelle » typologie d’API. Pour ce faire, nous allons tout d’abord définir ce qu’est un API Graph QL puis nous ferons un comparatif entre les avantages et les inconvénients de ce nouveau type d’API par rapport aux REST API. Enfin, nous verrons un cas pratique d’utilisation et nous vous donnerons notre avis sur les cas et l’intérêt de leur utilisation dans des contextes d’intégration via API.
Qu’est-ce qu’une API GraphQL ?
Avant de débuter, une petite précision : cet article ne traite pas de Microsoft Graph API qui est une RESTful Web API permettant d’accéder aux informations de multiples services Microsoft Cloud grâce à un Endpoint unique (https://graph.microsoft.com) et une authentification partagée dans Azure Active Directory.
Note : Pour aller plus loin, nous vous invitons à consulter la documentation « Use the Microsoft Graph API ».
Graph QL est un langage open source de manipulation et de requêtage de données. Fondé par Facebook et Lee Byron en 2012, il a pour but de permettre à l’appelant (ou le client) de choisir spécifiquement la structure et la liste des attributs des données qu’il souhaite récupérer (données dont le stockage peut éventuellement être distribué). Le serveur suit ensuite cette structure afin de construire et retourner la réponse. Cette méthode fortement typée a pour but d’éviter les problèmes de retour de données insuffisantes ou surnuméraires que les Api REST peuvent connaitre.
Par la suite, Facebook rend ce projet open source en 2015, avant de créer en 2019 la fondation GraphQL avec d’autres entreprises telles qu’AWS, Microsoft ou Twitter, pour propager et accélérer le développement de cette technologie.
En novembre 2021, Microsoft intègre à l’Azure API Management la prise en charge des APIs GraphQL qui permet de créer et de gérer des services GraphQL existants en les important dans ce composant.
Ce langage d’API se base sur les concepts clés suivants :
- Le client définit lui-même ce dont il a besoin et le serveur répond dans la même structure (Ask for what you need, get exactly that)
- Le typage fort de ces APIs permet d’éviter les problématiques de retour de données insuffisant (under-fetching) ou à l’inverse superflu (over-fetching)
- Requêter sur de nombreuses ressources grâce à une seule requête.
Présentation du modèle Graph QL API & différences par rapport au REST API
La typologie d’API GraphQL a été créée pour répondre aux problématiques des API REST. Elle s’attaque principalement au problème de flexibilité de ces dernières. En effet, son modèle en graphe d’entités lui permet de répondre à différents besoins sans multiplier les requêtes.

Figure 1- Exemple d’Architecture API GraphQL
Dans les paragraphes suivants de cet article, nous allons aborder les concepts clés faisant la force des APIs GraphQL.
Les endpoints / URI
Sur une API GraphQL il n’y a qu’un seul endpoint : « myApi/graphql ». C’est à partir de ce endpoint (côté serveur) que l’on va pouvoir requêter les entités du Graph.

La Flexibilité de GraphQL
GraphQL offre plus de flexibilité par rapport à une API REST car elle ouvre énormément de possibilités par rapport aux données exposées. En effet, il suffit de présenter un Graph d’entités pour que l’utilisateur choisisse ce qu’il souhaite requêter.
Pour cela, il faut enregistrer dans le graph les requêtes réalisables ainsi que le graph des entités.
Voici à quoi pourrait ressembler un Graph d’entités simple, ne possédant que deux types d’entités :

Les requêtes en GraphQL
En GraphQL il existe deux types de requêtes :
- Les mutations: des requêtes dont le but est un changement d’état de la donnée. En d’autres termes, la mutation a pour but de modifier la donnée.
- Les queries: des requêtes qui ont pour objet de récupérer de la donnée. Aucune modification n’est réalisée via cette dernière.
Les requêtes HTTP GET et POST avec GraphQL
En GraphQL, il est possible de faire des requêtes GET et POST :
- Si la requête comporte le paramètre query alors il faut la traiter comme une requête GET
myApi/graphql?query=myquery
- Si le Content-Type de la requête est « application/GraphQL » alors il s’agit d’une requête en POST
Les réponses de l’API GraphQL sont toujours formatées en JSON sous le format suivant :
- Une entrée data contenant l’ensemble des données requêtées
- Une entrée errors contenant l’ensemble des erreurs retournées lors de la requête
Les entités du graphe
Lorsque l’on parle des entités du graph, on évoque l’ensemble des objets qui seront manipulés par GraphQL. Ces objets sont composés de Fields, ce qui correspond aux paramètres de l’entité.
Ces Fields peuvent être divisés en deux parties :
- Les ConnectionFields
- Les Fields
Les ConnectionFields servent à lier deux entités du graphe ensemble, alors que les Fields sont utilisés pour les propriétés de type primitif (int, string …).
Les entités du graphe sont les objets que GraphQL devra manipuler en entrée via les arguments ou en sortie via le type de retour de la requête.
Chaque propriété de type Object doit être définie en Type GraphQL. Un Type GraphQL est un objet composé de Field définissant chacune des propriétés de ce dernier ainsi que la manière de la résoudre.
Chaque Field est composé d’un Nom, d’un Resolver et de paramètre. Le nom sert d’identifiant au Field et le Resolver sert à résoudre le champ.
Un Resolver est une fonction qui permet de résoudre la requête en remplissant les données d’un Field en fonction de ce qui a été défini. Plus simplement, il permet de faire le lien entre le Field Graph QL et la donnée du backend (base de données, API tierce…).
Voici un exemple de Field :
this.Field("title", context => context.Book.Title, nullable: true)
- “Title” correspond au Nom que l’on donne au Field
- Context => context.Book.Title correspond au Resolver
- Nullable: true fait partie des Paramètres qui peuvent être définis ici
Dans ce cas, nous avons un Resolver qui récupère dans le « context » le titre du livre (« Book Title »), mais il est tout à fait possible d’indiquer un résultat en dur ou un présenter une valeur calculée. Par exemple, si je remplace mon Field du dessus par celui-là, GraphQL me retournera toujours « Vingt mille lieues sous les mers » si je demande le titre du livre :
this.Field("title", context => "Vingt mille lieues sous les mers”, nullable: true).
Maintenant que nous avons une idée de ce à quoi sert ainsi que de quoi est composé une GraphQL API, intéressons-nous aux limitations avec lesquelles il faudra composer.
Limitations et faiblesses de GraphQL
Une des limitations de GraphQL est la gestion de la valeur « NULL » par le moteur GraphQL. En effet, pour lui, la valeur « NULL » équivaut à la valeur « undefined ». Il considère donc qu’il n’y a pas de valeur. Cela pose problème lorsque l’on va vouloir gérer le cas d’une réinitialisation d’une valeur. Il faut pour contourner cette problématique créer sa propre mécanique.
La deuxième limitation est la gestion des Files. On ne gère pas ce type de champ, il n’est donc pas possible de faire d’upload/download de fichier via ce type d’API.
Le troisième point est la perte du contrôle des performances, car à partir du moment où la propriété est exposée, elle peut être requêtée. Dès lors, il est possible par le jeu des navigationProperties et des QueryField, de requêter l’ensemble du graphe. Il faut donc faire très attention dans le cas où l’on expose ce type d’API à l’extérieur, car on ne maitrisera pas forcément la taille de la requête.
Coexistence d’un endpoint GraphQL et des endpoints REST
Pour pallier certaines de ces limitations et faiblesses, il est possible de faire coexister un endpoint GraphQL et des endpoints REST au sein d’une même API. Il est donc tout à fait possible de laisser la gestion des fichiers à nos endpoints REST.
Afin d’illustrer les notions présentées précédemment, nous allons à présent créer une simple API de type Graph QL.
Exemple d’utilisation des APIs GraphQL
Pour illustrer ces idées, prenons le cas d’une API GraphQL avec deux entités : Book et Author. Elles sont liées par une relation one-to-many (un auteur à 0 à n livres). Le but ici est de montrer à quoi ressemblera un backend simple.
Pour rappel, cela correspond à cette partie du schéma montrée au début de cet article :
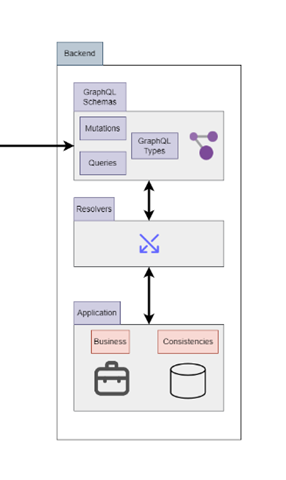
Note : cet exemple traite d’une API GraphQL intégrée à EntityFramework dans un projet .NET.
Pour des raisons de cohérence, nous allons commencer par déclarer la couche applicative et plus précisément la partie « consistencies » (qui, dans notre cas, est fortement couplée à EntityFramework).
Puis, dans un second temps, nous allons déclarer des types GraphQL et leur Resolver.
Enfin nous finirons par la Query GraphQL.
Configuration EntityFramework
Pour notre exemple, nous allons déclarer deux entités que l’on pourrait créer dans un projet .NET dans lequel on utilise EntityFramework.
La première est l’entité Book et la seconde Author.
Configuration Type GraphQL
Pour l’exemple, nous allons créer deux types GraphQL. La première classe correspond à la déclaration du type GraphQL BookModel et la seconde au type AuthorModel.
Nous pouvons voir ici la déclaration de l’ensemble des propriétés du type sous forme de Field/NavigationField.
Configuration de la Query GraphQL
Enfin nous allons finir par la déclaration de la Query. On peut voir que cette dernière est déclarée de la même manière qu’une propriété d’un type GraphQL, c’est-à-dire par un Field. On donne un nom à ce Field ainsi que la manière dont il doit être résolu.
A ce moment-là, nous avons fini la déclaration de la couche Backend.
Exemple d’utilisation de GraphQL
Comme vu précédemment, avec GraphQL c’est le client qui requête ce dont il a besoin et non le client qui récupère tout ce qu’on lui expose. Nous allons voir l’utilisation que l’on pourrait faire dans notre cas. Nous allons imaginer plusieurs cas de figure dans lesquels des applications vont avoir besoin de différentes informations de nos auteurs / livres. Dans notre cas, les entités étant très simples, nous avons de ce fait peu de possibilités différentes, mais dans le cas d’objet beaucoup plus complexes, le nombre de possibilités serait multiplié.
Cas n°1 : Notre application cliente veut afficher une liste d’auteurs avec le nom et prénom. L’identifiant technique ainsi que les livres associés à ces auteurs ne nous intéressent pas. On fera donc cette requête :

Réponse :

Nous voyons bien ici que nous ne récupérons qu’une liste d’objets avec le nom et prénom des auteurs et rien d’autre.
Cas n°2 : Notre application a besoin des noms et prénoms des auteurs ainsi que du titre des livres que ces derniers ont écrits. Nous ne récupérons pas, contrairement au cas précédent, l’identifiant technique de l’auteur ni celui des livres. La requête suivante va nous retourner l’ensemble des auteurs ainsi que la liste des livres associés :

Réponse :

Pour la comparaison, si l’on souhaitait atteindre le même niveau de précision avec une API REST, il nous faudrait exposer deux opérations traitant d’objets différents. Chaque endpoint étant appelé dans un cas spécifique, cela conduit à une multiplication des requêtes, mais également à l’exposition de données non-utiles puisque le REST ne permet pas nativement de filtrer la donnée récupérée.
A noter : Notre exemple traite d’un cas assez simple avec peu de champs, mais il faut imaginer que dans le cas d’objets complexes avec de nombreuses propriétés calculées, il nous suffirait d’exposer notre graphe pour qu’une multitude de requêtes soit réalisables. Au travers de chacune des requêtes, nous pourrons limiter le scope de la donnée récupérée à ce dont nous avons besoin.
Conviction sur l’utilisation des GraphQL APIs
Au travers de cet article, nous avons présenté une nouvelle manière de penser les APIs avec les APIs Graph QL. Ce nouveau type ne vient pas remplacer les APIs REST mais vient les compléter. En effet, en fonction du niveau de complexité de ses APIs et de ce que l’on souhaite en tirer, il faudra se diriger vers une façon de faire ou l’autre, ou bien vers une architecture mélangeant les deux.
En effet, la promesse de ne récupérer que les données intéressantes pour le client ne justifiera pas toujours la complexité amenée par la flexibilité et la richesse du langage de requêtage.
Les APIs Graph QL seront une option à considérer lorsque l’on souhaite mettre en place une API exposant des objets qui ne sont pas forcément complexes, mais très étoffés, et où les clients ne souhaiteront pas recevoir l’intégralité de la donnée. Dans ce cas, il sera très intéressant de proposer aux différents clients de choisir ce qu’ils souhaitent récupérer et sous quel format.
Dans le cadre de la mise en place de plateformes d’intégration moderne, les APIs Graph QL pourront nous aider lorsque l’on souhaite exposer ce que l’on appelle des « super » modèles (comprendre des modèles objets résultant de l’agrégation de plusieurs objets plus simples). Ou même simplement simplifier la consommation de nos APIs au travers d’une surcouche GraphQl. La flexibilité qu’offre le langage de requêtage permettra de proposer la création, la modification ou bien la récupération sélective des données au travers d’un unique endpoint.
Aller plus loin sur les APIs et GraphQL
Pour aller plus loin, n’hésitez pas à consulter la documentation de la fondation GraphQL : https://graphql.org/learn/






