

Introduction Integrating security into a widely used platform like GitHub is both a challenge and an opportunity to enhance its...
6 September 2022
Lire cet article en Français
GraphQL API: An Overview and Use Cases

Post co-written by Guillaume David and Nicolas Sotty
Business requirements for sparse data management are growing due to the modernization of information systems, APIzation projects, and the implementation of modern integration architectures. This data may not necessarily all be stored in the same place. It needs to be collected or viewed quickly and easily, however.
Faced with these needs, REST APIs have a number of limits. Graph QL APIs provide a new approach to API design that has emerged as a potential solution to this problem. Microsoft’s API Management tool now includes support for adding and managing Graph QL APIs.
The purpose of this post is to provide you with an overview of this “new” form of API. We’ll start by defining what a Graph QL API is, and then we’ll look at the pros and cons of using Graph QL APIs instead of REST APIs. Finally, we’ll look at a real-world example and provide our thoughts on whether or not these use cases are worth considering for API integration.
What Is a GraphQL API?
We should clarify that the Microsoft Graph API, a RESTful Web API that provides access to data from many Microsoft Cloud services via a single endpoint (https://graph.microsoft.com) and shared authentication in Azure Active Directory, is beyond the scope of this article.
Note: To learn more, please read the “Use the Microsoft Graph API” guide.
Graph QL is an open-source data manipulation and query language. It was created in 2012 by Facebook and Lee Byron to let the caller (or client) choose the data structure and which attributes should be returned (data whose storage may be distributed). The server then uses this structure to compile and return the response. This strongly typed approach aims to overcome REST APIs’ potential for returning inadequate or excess data.
Later, in 2015, Facebook released this project as open source. Then, in 2019, it formed the GraphQL Foundation alongside the likes of Amazon Web Services, Microsoft, and Twitter to further disseminate and expedite the growth of GraphQL.
To make it easier to create and manage existing GraphQL services, Microsoft plans to add support for them to Azure API Management in November 2021.
The following key concepts form the basis of this API language:
- The client defines its requirements, and the server responds using the same structure (ask for what you need, get exactly that)
- The strong typing of these APIs prevents under-fetching or over-fetching issues
- Query across multiple resources with a single query
Graph QL API Model Overview & Differences from Rest API
The GraphQL API typology was created to address these issues with REST APIs. It mainly seeks to address the lack of flexibility of REST APIs. Entity graph modeling ensures it can meet different needs without multiplying the number of queries.

Figure 1– Sample GraphQL API architecture
Next, we’ll dive into the core ideas that make GraphQL APIs so powerful.
The Endpoints/URL
There is only one endpoint in a GraphQL API: “myApi/graphql.” We can query the Graph entities from this (server-side) endpoint.

The Flexibility of GraphQL
GraphQL provides greater flexibility than a REST API since it opens up a vast range of data exposure capabilities. In practice, it’s as easy as showing the user a graph of entities and letting them choose what to query.
To achieve this, both the entity graph and the possible queries must be recorded in the graph.
This is an example of an entity graph with only two entity types:

GraphQL Queries
There are two query types in GraphQL:
- Mutations: queries that aim to change the state of the data. In other words, the purpose of the mutation is to modify the data.
- Queries: requests that aim to retrieve data. No changes are made with this second type.
HTTP GET and POST Requests with GraphQL
GraphQL allows both GET and POST requests:
- If the request includes the query parameter, it must be treated as a GET request
myApi/graphql?query=myquery
- If the request Content-Type is “application/GraphQL,” it’s a POST request
Responses from the GraphQL API are always in the following JSON format:
- A data entry with all the requested data
- An error entry listing all of the errors returned by the query
The Graph Entities
When we talk about the entities of the graph, we mean the group of objects that GraphQL will manipulate. These objects are made up of Fields, which represent the entity’s parameters.
These Fields can be divided into two sections:
- ConnectionFields
- Fields
ConnectionFields connect two graph entities, while Fields are used for primitive type properties (int, string, etc.).
The graph entities are the objects that GraphQL will have to manipulate as input through the arguments or as output through the query return type.
Each property of Object type must be defined in a GraphQL Type. A GraphQL Type is an object made up of Fields that define each property and how to resolve it.
Each Field comprises a Name, a Resolver, and parameters. The name is used to identify the Field, and the Resolver is used to resolve the Field.
A Resolver is a function that resolves the query by populating a Field with the defined data. Simply put, it lets you connect the Graph QL Field and the backend data (database, third-party API, etc.).
Here is an example of a Field:
this.Field("title", context => context.Book.Title, nullable: true)
- “Title” is the Name of the Field
- Context => context.Book.Title is the Resolver
- Nullable: true is one of the Parameters that can be defined here
In this scenario, we have a Resolver that retrieves the book title from the context, but it’s also possible to indicate a hard result or a calculated value.
For example, if I replace my top Field with this one, GraphQL will always return “Twenty Thousand Leagues Under the Sea” if I ask for the book title:
this.Field("title", context => "Twenty Thousand Leagues Under the Sea", nullable: true).
Now we understand the function of a GraphQL API and its components, we can examine the constraints that it faces.
GraphQL’s Weaknesses and Limitations
One of the limitations of GraphQL is that the GraphQL engine handles the “NULL” value. The “NULL” value is equivalent to the value “undefined.” It decides that there is no value because of this. This poses a problem if we need to handle the scenario of value reinitialization. You’ll need to devise your own workaround for this issue.
The second limitation is File management. GraphQL doesn’t support this field type, so you can’t upload or download files using this type of API.
The third issue is loss of performance control since a property can be queried as soon as it has been exposed. After that, you can use navigationProperties and QueryFields to query the whole graph. Because we can’t always control the request size, we must be cautious when making this kind of API available externally.
Coexistence of a GraphQL Endpoint and REST Endpoints
To get around some of these limitations and weaknesses, it’s possible to have both a GraphQL endpoint and REST endpoints within the same API. It is, therefore, possible to leave file management to our REST endpoints.
Now, let’s create a simple Graph QL API to demonstrate the concepts discussed so far.
Example of GraphQL APIs Use
Let’s use a GraphQL API with two entities, Book and Author, to show how these ideas work. They are linked by a one-to-many relationship (one author to 0 to n books). The goal here is to show what a simple backend would look like.
As a reminder, this corresponds to this part of the diagram at the beginning of this post:
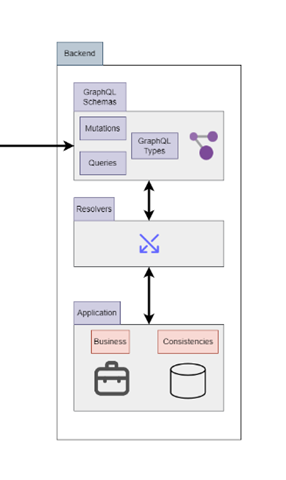
Note that this example uses a .NET project with an EntityFramework and a GraphQL API.
For consistency’s sake, we’ll start by declaring the application layer and, more specifically, the “consistencies” part (which, in our case, is tightly coupled with EntityFramework).
Then, in the second step, we’ll declare GraphQL types and their Resolver.
The last step will be the GraphQL query.
EntityFramework Configuration
For our example, we’ll declare two entities we could create in a .NET project using EntityFramework.
The first is the Book entity, and the second is the Author entity.
GraphQL Type Configuration
We’ll create two GraphQL types for this example. The first class matches the declaration of the BookModel GraphQL type, and the second matches the AuthorModel type.
Here, we can see the declaration of all the type’s properties in the form of Field/NavigationField.
Configuring the GraphQL Query
The final step is to declare the Query. We can see that the latter is declared in the same way as a property of a GraphQL type, namely by a Field. We give this Field a name and define how it should be resolved.
At this point, we’ve finished declaring the backend layer.
Example of GraphQL Use
As we’ve already seen, with GraphQL, the client only requests what it needs. The client doesn’t retrieve everything that is exposed to it. Let’s look at how we might apply this in our scenario. We’ll imagine several situations in which applications need different information from our authors or books. The relative simplicity of the entities in our scenario means we only have a few different possibilities. These would obviously increase if we were dealing with more complex objects.
Scenario 1: Our client application wants to show a list of authors with their first and last names. We are not interested in the technical identifier or the books associated with these authors. Since this is the case, we’ll use the following query:

Response:

Here, we can see that the only thing we get is a list of objects with the first and last names of the authors.
Scenario 2: Our application needs the authors’ first and last names and the titles of the books they have written. Unlike in the previous scenario, we do not retrieve the technical ID of the author or the books. The following query will return a list of all the authors and the books associated with them:

Response:

For comparison, if we wanted the same level of accuracy with a REST API, we would have to expose two operations that handle different objects. Each endpoint is called in a specific situation. This leads to many requests and the exposure of data that is not useful since REST doesn’t natively allow filtering of the retrieved data.
Note: Our example is pretty simple and only has a few fields, but you can imagine that if we had complex objects with a lot of calculated properties, we would only have to expose our graph to make a lot of queries possible. Each query allows us to limit the scope of the retrieved data to meet our specific requirements.
Thoughts on GraphQL APIs and Their Usefulness
This post has shown you how Graph QL APIs can revolutionize how you think about application programming interfaces. This new type doesn’t replace REST APIs. Instead, it supplements them. Depending on how complicated the APIs are and what you want to get out of them, you need to choose one method or the other or create an architecture that combines both.
The promise that the client will only retrieve relevant data doesn’t always justify the complexity that comes with the richness and flexibility of the query language.
GraphQL APIs are an option worth considering if you want to create an API that exposes objects that are not necessarily complex but are incredibly rich, and where the clients do not require all the data. In this scenario, the ability to allow clients to choose what they want to retrieve and in which format would be beneficial.
When implementing modern integration platforms, the Graph QL APIs can help us when we want to expose what we call “super” models (object models resulting from the aggregation of several simpler objects) or even make it easier to use our APIs with a GraphQL overlay. The flexibility of the query language makes it possible to ensure the creation, modification, or selective retrieval of data through a single endpoint.
Further Reading on APIs and GraphQL
Feel free to check out the GraphQL Foundation’s learning resources at https://graphql.org/learn/ if you’re interested in learning more.





