

Dans la continuité des articles précédents sur la Kubernetes Gateway API, nous explorons aujourd’hui un aspect plus opérationnel de ce...
17 novembre 2022
Read this post in English
Synapse Analytics : comment mettre en œuvre le CI/CD sur Azure DevOps ?

Dans ce billet de blog, nous allons nous pencher sur les pipelines d’intégration de données Synapse Analytics. Vous pourrez également vous y référer lors de vos projets réalisés avec Data Factory.
Nous allons définir ce que sont réellement les pipelines « sous le capot » et comment mettre en œuvre l’intégration continue/le déploiement continu sur Azure DevOps.
Prenons un projet exemple. Les différentes activités elles-mêmes importent peu, je ne m’y attarderai donc pas.
Rentrons plutôt dans le vif du sujet sans plus attendre !
Pipelines Synapse/Data Factory
Ce projet exemple utilise un pipeline Maestro, qui est le point d’entrée de tous les pipelines.
Le pipeline Maestro exécute l’ensemble des pipelines de processus.
Les autres pipelines considérés comme des « enfants » de Maestro peuvent également exécuter leurs propres sous-processus. Par exemple, le pipeline Advisory peut exécuter le pipeline Comparison Tool Loading.
Le modèle général que j’ai utilisé pour tous les pipelines est le suivant :
- Démarrer un processus : enregistrez dans la base de données « de surveillance » que le processus a été démarré à telle heure. Nous créons une table ProcessRun.
- Exécuter le processus : consignez les « sous-processus » = éléments générés par le processus dans la table ProcessRunItem.
- Terminer un processus : mettez à jour la table ProcessRun préalablement créée en y ajoutant le statut d’exécution du processus correspondant.
Les pipelines correspondent à un ensemble de fichiers JSON placés dans le référentiel git (si l’intégration git est activée). Chaque fichier contient la définition d’un pipeline, c’est-à-dire les activités qu’elle contient. La branche de collaboration (qui équivaut à la branche principale pour Synapse) est appelée « synapse » dans le cadre de cet exemple. Vous pouvez toutefois lui donner un autre nom si vous le souhaitez.
Vous trouverez ci-dessous les pipelines tels qu’ils apparaissent dans l’interface utilisateur de Synapse Analytics :
Maestro

NXDH Data Validation

Advisory

ComparisonTool Loading
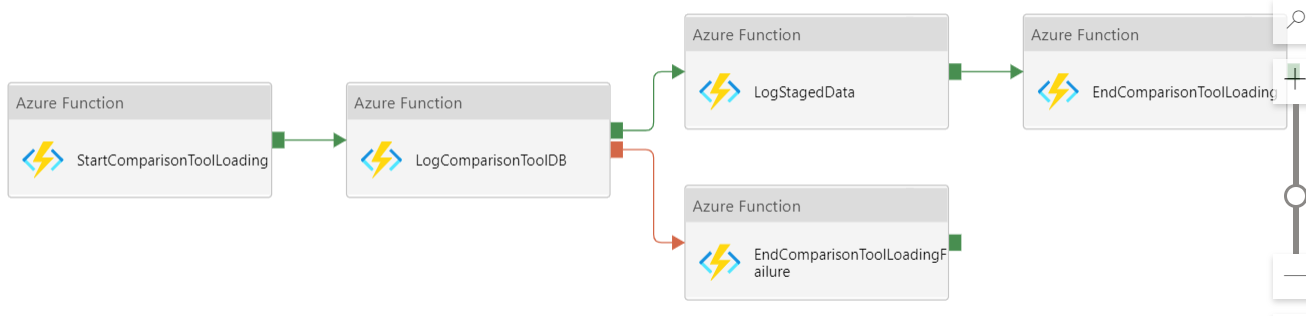
CI/CD sur Synapse/DataFactory : principe de fonctionnement
Tout d’abord, nous devons activer l’intégration git.
- Seul l’environnement de développement doit être intégré à git. L’ensemble du développement d’intégration doit donc être effectué exclusivement dans l’environnement de développement. Aucun changement direct ne doit être apporté aux environnements d’UAT et de production.
- Il existe une « branche de collaboration », qui est l’équivalent de la branche principale ou « master » dans un projet git classique. Dans mon exemple, elle s’appelle « synapse ». Il est donc important d’éviter de travailler directement sur la branche de collaboration et de créer plutôt une branche de fonctionnalité pour ne pas risquer de corrompre la branche existante.
- Une fois que les changements apportés à la branche de fonctionnalité nous conviennent, nous pouvons les valider avec l’instruction commit et créer une pull request auprès de la branche de collaboration (« synapse », dans notre cas).


- Maintenant que l’environnement de développement est prêt, nous pouvons le publier depuis l’espace de travail Synapse. Seule la branche de collaboration peut être publiée.

Le pipeline de développement publiera en tant qu’artéfacts pour mise en production les deux fichiers générés lorsque vous cliquerez sur le bouton Publish au niveau de la branche Synapse (workspace_publish) : TemplateForWorkspace.json et TemplateParameters.json

- Le pipeline de mise en production créera les pipelines et les services liés à partir de « TemplateforWorkspace » dans tous les environnements en écrasant « TemplateParameters » par les valeurs appropriées. Nous avons besoin de la tâche de déploiement de l’espace de travail Synapse, disponible en tant qu’extension Azure DevOps téléchargeable gratuitement.


Vous pouvez ensuite vérifier que les services liés sont correctement intégrés à l’issue du déploiement et que les modifications apportées aux pipelines ont bien été appliqués.
Il convient de préciser quelques détails importants au sujet du CI/CD sur Synapse :
- Nous devons créer les integration runtimes dans tous les environnements avant la mise en production sinon le processus échouera.
- Le fichier TemplateForWorkspace.json comprend le nom de l’integration runtime, car un seul et même nom est attendu dans l’ensemble des environnements.
- Nous devons donc créer ces integration runtimes avec le même nom dans chaque environnement.
⚠️ Vous ne devez PAS procéder à une validation directement dans la branche de collaboration, car elle équivaut à la branche principale d’un projet classique. Procédez dans un premier temps à une validation auprès d’une autre branche, puis, lorsque le résultat vous convient, créez une pull request auprès de la branche de collaboration.
N’écrasez pas une autre branche par erreur !
Nous sommes arrivés à la fin de ce billet de blog ! J’espère que vous pourrez l’utiliser en guise de référence lors de vos prochains projets Data Factory/Synapse.






