

Introduction Integrating security into a widely used platform like GitHub is both a challenge and an opportunity to enhance its...
17 November 2022
Lire cet article en Français
Synapse Analytics: how to implement CI/CD on Azure DevOps?

This blog post will look into Synapse Analytics data integration pipelines, so it can also be used as a reference for projects using Data Factory.
We will look at what are pipelines under the hood, and how to implement CI/CD on Azure DevOps.
I will take an example project. The different activities themselves do not really matter, so I won’t deep dive into those.
Without further ado, let’s start!
Synapse/Data factory pipelines
For this example project, we have a Maestro pipeline, which is the entry point for all other pipelines.
The Maestro pipeline will execute all the processes pipelines.
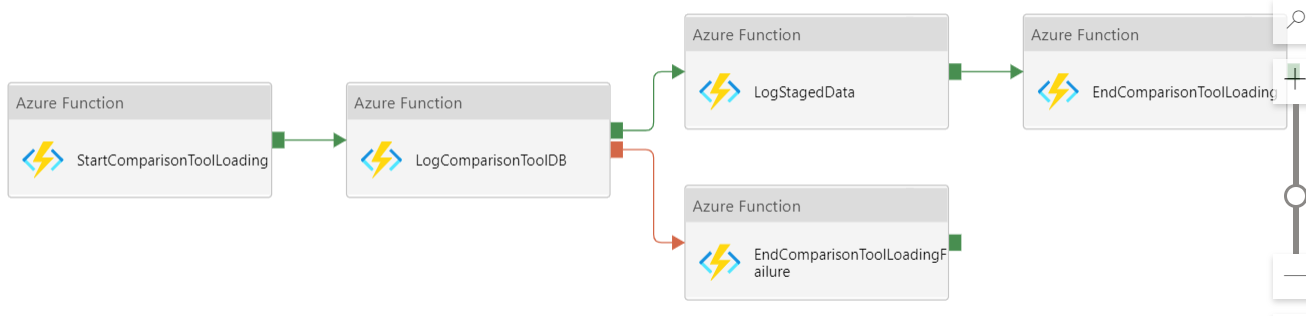
Other pipelines that are “children” of Maestro can also execute their own subprocesses. For example the Advisory pipeline will execute the ComparisonTool Loading pipeline.
The general template I used for all the pipelines is:
- Start a process: log in the “monitoring” DB that the process started at T time. We create a ProcessRun.
- Execute the process: log the “subprocesses” = items generated by the process in the ProcessRunItem table.
- End a process: update previously created ProcessRun with the status of execution of said process.
The pipelines are a collection of JSON files that you can find in the git repository (if git integration is enabled). Every one of those contains the definition of their respective pipeline, in other words, the activities they contain. The collaboration branch (equivalent to main branch for synapse) is called “synapse” for this example. It can be named differently though, your choice.
Find below the pipelines as shown through the Synapse Analytics UI:
Maestro

NXDH Data Validation

Advisory

ComparisonTool Loading
CI/CD on Synapse/DataFactory: how does it work?
First of all, we need to enable the integration with git.
- Only the DEV environment should be integrated with git, thus all integration development should be done exclusively on the DEV environment. No direct changes to QA, PROD environments.
- We have a “collaboration branch” which is the equivalent of main or master branch in a regular git project. In my example, it is called “synapse”. It is therefore important to avoid working directly on the collaboration branch, but rather to create a feature branch to not risk to break the existing.
- Once we are happy with the changes on our feature branch, we can commit those changes and create a pull request towards the collaboration branch (in our case, “synapse”)


- Once we are happy with the DEV environment, we can publish it from the Synapse Workspace. Only the collaboration branch can be published.

The build Pipeline will publish as artifacts for release the two files that are generated upon clicking on the Publish button on synapse, on the branch workspace_publish : TemplateForWorkspace.json & TemplateParameters.json

- Release pipeline will create Pipelines & Linked Services from “TemplateforWorkspace” in all the environments by overwriting “TemplateParameters” with the right values. We need the Synapse workspace deployment task, available as an Azure DevOps extension downloadable for free.


Then you can check that the Linked Services are correctly input after deployment, and that the pipelines changes are applied.
A few details that are important regarding the CI/CD on Synapse:
- We need to create the Integration Runtimes in all the environments before releasing or it will fail.
- The TemplateForWorkspace.json includes the Integration Runtime name because it expects the same name across all environments.
- We then understand we need to create those IRs with the same name in every environment.
⚠️You should NOT commit directly into the collaboration branch because it is the equivalent of the main branch in a regular project. Commit to another branch first and create a Pull Request to the collaboration branch when you are happy with the result.
Don’t overwrite another branch by mistake
This concludes this blog post! I hope it can serve useful for reference in your future DataFactory/Synapse projects.






