

Déployer Microsoft 365 en entreprise est un véritable projet qui va bien au-delà de la vérification de prérequis et de...
23 août 2013
La recherche sous SharePoint 2013 : 3ème partie

Une fois le service de recherche installé : nous allons devoir crawler le contenu de notre site afin de construire l’index.
Mise en place de l’architecture de crawl
Pour lancer l’indexation, on se rend dans l’administration du service de recherche :

Vérifier qu’il soit bien démarré, sinon le démarrer.
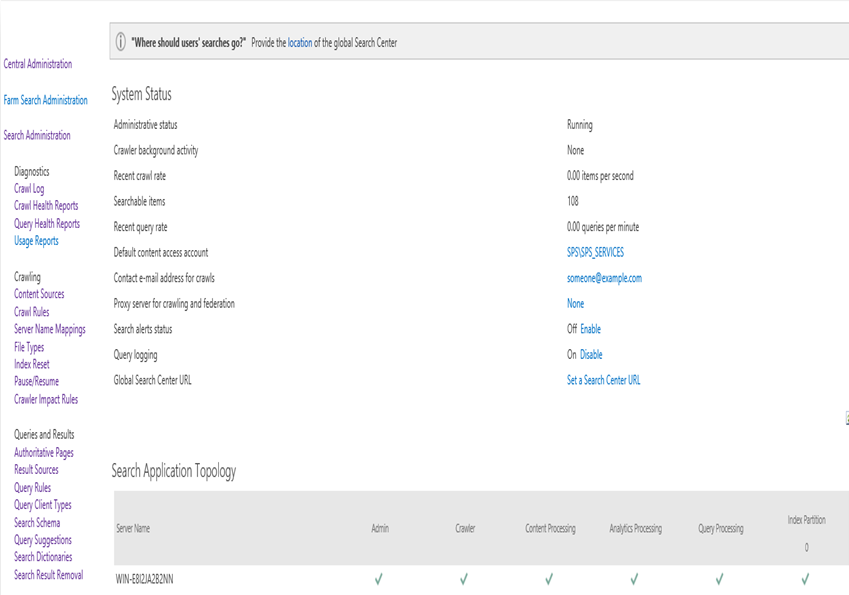
On arrive sur la page d’accueil du service de recherche, noter ici la topologie de la recherche :
Pour lancer notre première indexation (CRAWL), on va dans la section “Crawling”, page “content source” :
On peut ainsi soit créer un nouveau content source, soit modifier l’existant. On choisit de planifier le crawl incrémental/continu et le crawl full. On clique sur ok, remarquez que sous SharePoint 2010 à la fin de cette étape, un crawl était démarré par défaut. Ce n’est plus le cas en 2013. Il faut donc soit le démarrer manuellement, soit attendre le prochain.

Exclusion de fichier selon leur type
On a aussi la possibilité d’exclure certains types de fichiers en fonction de leur extension. Par défaut il y a déjà une liste des types de fichiers généralement exclus lors de l’indexation du contenu des sites SharePoint.
A noter qu’à chaque ajout, modification de cette liste, un full crawl sera nécessaire.
Crawl continu vs Crawl Incrémental
Une des nouveautés de SharePoint 2013 est l’ajout du crawl “continu”. Ce mode ne peut être appliqué qu’à des sources de contenu SharePoint. Ce type de crawl, par défaut, récupère les changements toutes les 15 minutes, et les pousse dans le processeur de contenu. De cette manière, un document peut apparaître dans l’index après quelques secondes; il n’est plus nécessaire d’attendre que l’index soit “mergé”.
Les crawl incrémentaux sont toujours supportés dans SharePoint 2013. Chacun a ses avantages :
- Le crawl continu commence alors que le premier crawl complet n’est pas terminé. De cette manière, il n’est pas nécessaire d’attendre la fin du crawl complet avant de pouvoir commencer des recherches.
- Les crawl continus sont déclenchés en parallèle; un long crawl ne bloquera pas le démarrage du suivant.
- Les crawl continus marquent les erreurs pour plus tard, et continuent le crawl plutôt que d’utiliser une logique de nouvel essai. Cela leur permet de terminer plus rapidement si des problèmes sont rencontrés.
- D’un autre côté, il est possible de contrôler les horaires des crawls incrémentaux si la plateforme physique n’a pas les ressources suffisantes pour supporter le crawl continu.
- De plus, contrairement au crawl continu, le crawl incrémental va tenter de résoudre les erreurs lorsqu’elles se produisent.
Il faut également noter la possibilité de vider l’index, si cela s’avère nécessaire.
A vous de jouer et créer une bonne règle de Crawl en fonction des besoins. Dans notre prochain article nous verrons comment créer les crawled properties…





