

Comment RAJA Group a construit une plateforme data unifiée avec Microsoft Fabric – et comment Cellenza a contribué à écrire...
27 octobre 2020
Azure Data Factory et Azure Databricks : des socles pour la BI et la Data Science

La réussite d’un projet data repose principalement sur l’alimentation de la plateforme data en données. Par ailleurs, les données doivent être qualitatives et présentes au bon moment pour alimenter les briques suivantes, telles que la data science ou la Business Intelligence (BI).
Ingestion des données dans un projet data
La première brique d’un projet data repose sur l’ingestion de données. Cette étape consiste à récupérer l’ensemble des données nécessaires au fonctionnement de projets tirant parti des données.
Les questions à se poser en amont d’un projet data
Avant de démarrer un projet data, il est important de se poser les questions suivantes :
- Comment accède-t-on à la donnée ? Utilise-t-on une API, une copie de fichiers depuis un répertoire réseau on-premise, une base de données, etc. ?
- Quelle est la fréquence d’ingestion des données ? Est-elle mensuelle, quotidienne, s’agit-il d’un flux de données ?
- Faut-il faire du full data ou du delta data ?
La réponse à ces questions permettra de déterminer l’architecture à mettre en place : batch, temps réel ou lambda.
Quels sont les différents niveaux de qualité des données ?
En fonction des étapes de traitement des données, la donnée passe par différents niveaux de qualité :
- Niveau bronze : la donnée vient seulement d’être ingérée. Elle peut avoir différents formats : CSV, JSON, image, XML, etc. ;
- Niveau argent : la donnée est nettoyée et préparée. Le format utilisé est Delta Lake (pour en savoir plus, consulter notre article sur Delta Lake).
- Niveau or : chaque projet exploite les données de niveau argent pour les valoriser et les transformer en or. Les données peuvent être stockées au format Delta Lake ou être poussées vers une base Cosmos DB ou Azure Synapse, par exemple.

Deux projets peuvent utiliser des données communes mais ne pas les exploiter de la même manière. C’est pourquoi il faut garder les données de niveau argent à un état relativement brut.
Imaginons qu’un projet A ait besoin d’agréger des données alors qu’à l’inverse, un projet B nécessite de travailler sur les données brutes. Puisque les données viennent de sources différentes, elles doivent être nettoyées et transformées de manière à pouvoir être analysées ensemble. Sinon, les données seraient semblables à des pièces de puzzle qui ne pourraient pas s’emboiter !
Pourquoi avoir des données propres et centralisées ?
Accéder aux données dans un même endroit permet de mutualiser les informations, ce qui amène par la suite à un flux de nouveaux projets. Cela permet en effet à ceux qui ont accès à des données propres d’avoir une vue différente que celles qu’ils auraient eue en regardant les données morceau par morceau. On peut par exemple trouver des agrégations intéressantes ou créer des modèles de prédictions. Ils apportent alors plus de valeurs aux données.
Cela paraît simple en substance, mais c’est sans prendre en compte la volumétrie des données et la fréquence à laquelle on va les ingérer. Il faut donc choisir les bons outils et la bonne stratégie.
On peut ingérer la donnée :
- En temps réel ;
- Par batches ;
- En combinant les deux (lambda architecture).
La lambda architecture est très fréquente. On cherche à mettre en lumière deux facettes (les données du passé et celles du présent) ; c’est une tâche généralement fastidieuse.
Une manière de simplifier énormément le travail est d’utiliser le format delta. Les tables delta peuvent gérer les flux continus de données depuis des sources à la fois historiques (batches) et streaming (en temps réel), sans coupure. Grâce à l’utilisation du framework open source Spark, cette solution est compatible avec la plupart des solutions de streaming déjà en place, telles que Apache Kafka ou Azure Event Hub.
Azure Data Factory
Azure Data Factory est un service du cloud Azure permettant de :
- Copier des données depuis une source vers une destination ;
- Orchestrer une suite d’actions ;
- Transformer des données en utilisant Mapping data flows ou préparer des données avec Wrangling data flow. Nous ne traiterons pas ce troisième point dans cet article.
Copier des données depuis des sources multiples
Une des forces de Azure Data Factory réside dans son activité de copie. Pour pouvoir l’utiliser, il faut dans un premier temps définir une connexion vers la source de données et les destinations. Cette connexion se nomme Linked Services.
Azure Data Factory propose de très nombreux connecteurs, vers les services Azure, bien évidemment (ADLS Gen2, Azure SQL Database, Cosmos DB, etc.) mais également vers des systèmes tiers comme les outils de la suite SAP (SAP HANA, SAP ECC, etc.), Snowflake, Amazon (Redshift, S3, etc.), Google BiQuery et bien d’autres.
Les Linked services sont répartis en deux catégories :
- Data store ;
- Compute.

Dans la partie Compute, vous retrouverez les connexions qui peuvent se faire avec des outils permettant de traiter les données (c’est le cas d’Azure Databricks, par exemple).

Une fois les deux Linked services créés (un pour la source et l’autre pour la destination), il est nécessaire de créer un dataset. Il s’agit de préciser certains éléments :
- A partir de quel endroit lire la donnée sur la source ?
- Quel type de fichier ?
- Quel format ?
- S’agira-t’il d’un répertoire ou d’un nom fichier (ou d’un nom de table dans le cas d’une base de données) ?
- Etc.
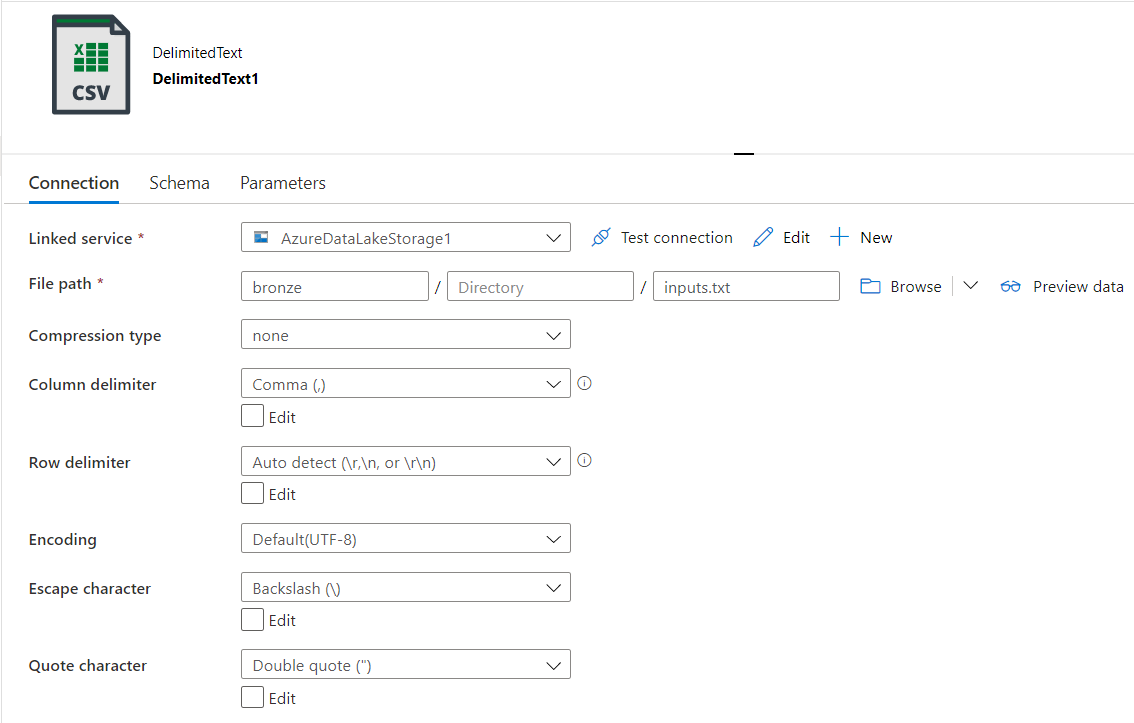
Enfin, il vous sera possible de configurer l’activité de copie en utilisant le dataset d’origine et le dataset de destination.
De plus, vous aurez une vision du temps passé à chacune des étapes de la copie pour :
- Lister les fichiers ;
- Lire la source ;
- Ecrire dans la destination.

Dans la même veine, vous pouvez consulter la consommation d’un pipeline en terme de DIU-hour. En faisant un premier test, vous pourrez ensuite estimer votre future consommation en fonction de la fréquence d’exécution du pipeline :

L’activité de copie peut être lancée en mode full ou bien se faire à partir des dates de modification de fichiers ou en se basant sur la watermark dans le cas d’une base de données. Pour en savoir plus, nous vous invitons à consulter la documentation Microsoft.

Les actions s’exécutent sur un integration runtime. Il en existe deux : Azure IR ou Self-hosted IR. Vous pouvez utiliser un « integration runtime Self-hosted » pour copier des données on-premise. Cela se fait en installant un agent sur une VM on-premise. Azure Data Factory va envoyer une demande de copie à l’agent. L’agent récupère alors les données et les envoie à Azure Data Factory. Ainsi, il n’y a pas de flux entrants depuis Azure Data Factory vers le réseau on-premise.
Afin d’avoir une idée des bonnes performances de l’activité de copie, vous pouvez consulter la documentation Microsoft sur ce sujet.
Notons qu’il existe également un integration runtime permettant d’exécuter des packages SSIS, dont nous ne parlerons pas ici.
Orchestration : création de pipelines
L’orchestration commence par la création de pipelines consistant en un enchaînement d’activités. Il existe plusieurs types de relation entre les activités :
- Success : l’activité 2 démarre si l’activité 1 termine avec succès ;
- Failure : l’activité 2 démarre si l’activité 1 termine en erreur ;
- Completion : l’activité 2 démarre une fois que l’activité 1 se termine, qu’elle soit en succès ou en échec ;
- Skipped : l’activité 2 ne s’exécute pas.

Vous pouvez ensuite créer des triggers pour déclencher les pipelines.
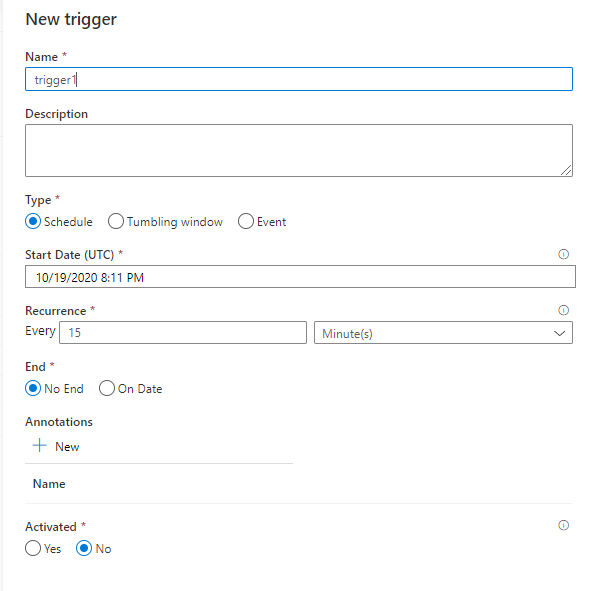
Trois types de triggers sont disponibles :
- Schedule : planifier l’exécution à une date et/ou une heure précise (par exemple : tous les jours à 10h et 19h / tous les mardis / tous les 10 du mois / etc.) ;
- Tumbling window : planifier l’exécution sur une fenêtre de temps glissante (par exemple : toutes les 10 minutes ou toutes les heures) ;
- Event : planifier un pipeline à la création ou à la suppression d’un blob.
Vous pouvez également utiliser les APIs Data Factory pour déclencher l’exécution d’un pipeline à partir d’une web app, par exemple.
Pour ce qui est de la gestion de configuration, il est possible de lier Azure Data Factory (ADF) à un repository Git.
Le principe est d’avoir une instance de ADF par environnement. L’instance de l’environnement de développement est connectée au repository. Ce n’est pas le cas de l’instance de l’environnement de recette et de production pour lesquels vous allez livrer ce que vous avez préparé en développement.
Pour gérer les variables liées aux environnements, il y a la section « Parameterization template » (consulter la documentation Microsoft sur le sujet).
ETL : extraire, transformer et sauvegarder les données
Extract, Transform, Load (ETL) est le process général d’extraction de la donnée (ou de sa copie) depuis une ou plusieurs sources vers une destination, de transformation des données et de sauvegarde du résultat de ces transformations.
Delta Lake pour fusionner les données
Dans un précédent article, nous avions abordé la question de pourquoi utiliser Delta Lake. Créé par Databricks, le format delta est un format open source qui répond aux problématiques du data lake classique en ajoutant, entre autres :
- des transactions ACID ;
- la possibilité de faire un merge des données (insert ou update) ;
- la validation de schémas, du data versioning au traditionnel parquet (delete).
Utilisation concrète : ETL sur des données Covid-19 avec Azure Databricks
Microsoft fournit des données open data sur l’évolution journalière du nombre de cas, de décès et de guérison du covid-19 dans le monde entier et dans chaque pays.
La donnée curated (niveau argent) est déjà prête à être transformée par des data analysts et data scientists pour apporter de la valeur mais ce qui nous intéresse particulièrement, c’est d’arriver au même résultat à partir de la donnée brute (niveau bronze). Le format brut est également disponible.
En termes d’ingestion, on est dans un cas très simple : il est nécessaire de copier des données depuis un blob storage appartenant à Microsoft vers un blob storage que nous avons créé sur notre souscription Azure.
Extraction des données avec Azure Databricks
Nous utilisons Azure Data lake Storage gen 2 (ADLS2) pour stocker la donnée brute. Nous allons l’extraire pour la transformer en utilisant Azure Databricks et sauvegarder le résultat sur ce data lake au format delta lake.
Pour connecter ADLS2 et Azure Databricks, vous vous invitons à vous référer à notre article sur comment traiter les données en toute sécurité avec Azure Databricks.
Dans notre cas, nous avons utilisé des points de montages pour accéder facilement aux données.
Le data lake est composé de 3 containers : un pour le container bronze, un pour l’argent et un pour l’or. Nous avons créé 3 points de montage pointant vers chacun des containers.

Lors de l’étape « extract », on peut placer une étape de validation. Prenons l’exemple d’une extraction de fichiers JSON : lorsque le schéma attendu n’est pas respecté, Databricks permet d’insérer les données ne respectant pas le schéma dans un fichier d’erreur. Il est ainsi possible de les tracer.
Transformation des données
La transformation de données nécessite d’abord d’examiner les données afin de comprendre leur structure et de changer l’information en un format ou schéma pour lequel des utilisateurs seront en mesure de les exploiter.
Plusieurs transformations à partir de la donnée brute sont possibles :
- Modifier le schéma, afin que les valeurs numériques soient bien comptées telles quelles, ce qui permettra de les utiliser pour faire de l’analyse descriptive et exploratoire.
- Créer de nouvelles colonnes à partir de celles existantes. Prenons l’exemple des données de ventes sur une plateforme e-commerce. Sur une colonne contenant les dates complètes de transaction, on peut ajouter une colonne contenant le jour de la semaine ou séparer les heures des dates pour une utilisation ultérieure par des analystes ou data scientists.
Dans l’exemple ci-dessous, le schéma a été modifié.
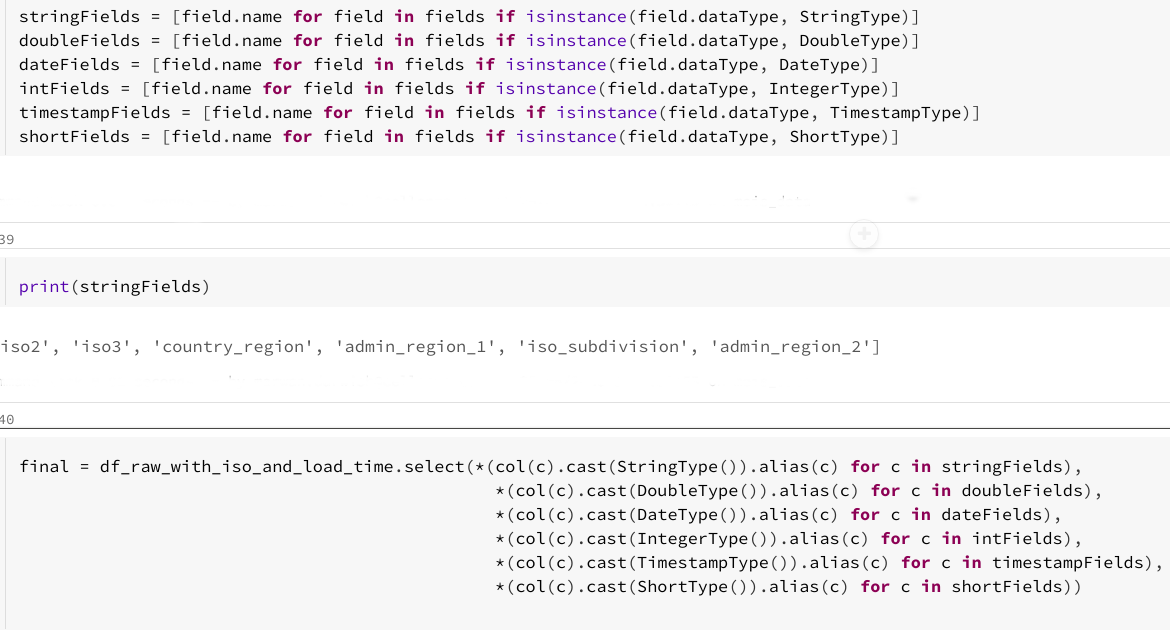
Un autre moyen d’ajouter des colonnes (alias de l’information supplémentaire), c’est d’enrichir les données par une table de référence d’une autre source et faire une jointure. Vous observerez ci-dessous, un enrichissement des mêmes données par des données ISO provenant d’un fichier CSV.

Lors du développement des transformations de données, on passe nécessairement par une phase de tâtonnement : elle permet de s’assurer de l’intégrité des données et de vérifier l’absence de doublons ou de valeurs nulles. Si c’est le cas, il faut alors réfléchir à une stratégie pour nettoyer les données.
Si l’on reprend l’exemple de l’enrichissement avec les codes ISO, il se peut que certains index aient été dupliqués. En regardant de plus près, nous avons remarqué que certaines régions possèdent deux codes différents, ce qui amenait à la duplication de ces lignes, avec pour seule modification, un deuxième code ISO.
Dans ce genre de cas, on peut être amené à rejeter de la « mauvaise donnée ». Dans cet exemple, nous avons décidé de rejeter une infime partie des lignes en gardant uniquement un seul code ISO. En effet, il n’y a pas fondamentalement une grande valeur à tirer de deux codes iso_subdivision différents. C’est aussi l’assurance d’avoir un id unique, qui permettra aux utilisateurs finaux une analyse facilitée.
Load : sauvegarder les données
Il est important d’utiliser un schéma que l’on maîtrise.
Ainsi, en cas d’utilisation de csv, par exemple, le schéma n’est pas sauvegardé, contrairement à du Parquet.
Conçu pour stocker d’importants volumes de données complexes, le format Parquet apporte plusieurs avantages :
- Il intègre un schéma appliqué dès la lecture, contrairement à des formats populaires en data science, tels que CSV ou JSON. Cela rend la tâche moins fastidieuse aux personnes amenées à exploiter la donnée (d’un data scientist, par exemple) qui auraient à appliquer le schéma manuellement aux données. Cela permet également de garantir une cohérence au sein des différents traitements.
- Il offre des statistiques sur les métadonnées, ce qui peut réduire considérablement le temps de traitement de certains types de requêtes. Supposons qu’on ait des données Parquet partitionnées par région sur des détenteurs d’une assurance-vie dans 20 régions. On veut récupérer les entrées correspondant uniquement aux personnes âgées de plus de 95 ans sur des millions d’assurés. L’usage de ces statistiques permettra de sélectionner uniquement les fichiers à considérer. On vient d’économiser un temps précieux en évitant d’ouvrir plusieurs fichiers ; on limite ainsi la puissance de calcul en n’en consultant qu’une partie dès le départ.
- La compression effectuée colonne par colonne apporte de bien meilleures performances que des formats comme CSV ou JSON où les données sont lues ligne par ligne (pour en savoir plus, nous vous invitons à regarder la vidéo de Databricks).
Au-delà du format Parquet, on peut également utiliser Delta Lake, particulièrement simple, avec data skipping lors de la lecture.

En apparence, similaire au format Parquet, Delta a toutefois un ajout : le delta_log.

À l’intérieur du dossier, on retrouve un ensemble de fichiers json correspondant chacun à un commit. A l’intérieur de ces fichiers, différentes informations sont indiquées : nombre de lignes / le schéma des données à tel commit / utilisateur qui a comité /date à laquelle le commit a été effectué / etc.
Ces fichiers permettent de faire du rollback et d’assurer l’intégrité et la véracité des données.
L’ingestion des données, base d’un projet data
L’ingestion de données est le point d’entrée d’un projet data.
Il est indispensable de mener une réflexion en amont en mettant au point une ingestion pérenne mais agile. Celle-ci sera très certainement amenée à évoluer en fonction des nouvelles sources de données à ingérer.
Les experts Cellenza sont présents pour vous accompagner dans vos projets data et vous aider à mettre en place cette brique essentielle.
✍️ Cet article a été co-rédigé par nos experts data : Donatien Tessier et Marwan Darwish.






