

Comment RAJA Group a construit une plateforme data unifiée avec Microsoft Fabric – et comment Cellenza a contribué à écrire...
29 octobre 2020
Data Bug : identifier, corriger, déployer dans la journée

Quel que soit votre projet, le maintien de la qualité de vos données est primordial. En effet, il est inutile de collecter une importante quantité de données si vous ne pouvez pas vous y fier pour prendre des décisions judicieuses !
La seule façon de maintenir une qualité élevée est de mettre en place des contrôles de qualité ainsi qu’une validation à chaque étape de votre pipeline de données. Comme le dit le proverbe : « garbage in, garbage out ! »
La qualité des données ne se limite pas seulement à aider les organisations à charger des données correctes dans leurs systèmes d’information ; elle permet également de se débarrasser des données erronées, corrompues ou dupliquées. Le nettoyage des données devient une étape essentielle dans l’intégration d’informations dans les systèmes. La gestion de la qualité des données est la capacité à fournir des données fiables capables de répondre aux besoins métiers et techniques des utilisateurs.
La qualité, c’est primordial ! En effet, malgré l’enthousiasme et l’argent dépensé dans des projets (Big) data, ceux-ci finissent souvent par échouer en raison de données peu fiables. On ne peut évidemment en tirer aucune information pertinente même avec les modèles d’Intelligence Artificielle (IA) les plus évolués.

L’objectif de cet article est tout d’abord de redéfinir la notion de qualité et de donner quelques bonnes pratiques sur les processus à mettre en place pour s’assurer de la qualité de vos données en continu.
Qu’est-ce qu’une donnée de qualité ?
Il n’existe pas de standard absolu qui ferait d’un ensemble de données une référence en termes de qualité et de fiabilité. Et c’est là tout l’intérêt, et de fait la complexité, de la définition des exigences de qualité.
La qualité s’exprime et se définit par rapport à une finalité : le besoin impose ses contraintes à la donnée entrante. Elle est aussi fonction du prisme par lequel on l’observe : un Data Engineer et un Data Scientist n’auront pas les mêmes attentes et n’agiront pas aux mêmes niveaux du pipeline d’ingestion et de traitement.
Bien qu’aucune définition ne fasse l’unanimité, tout le monde s’accorde cependant sur le fait que la qualité d’une donnée peut se décomposer en un certain nombre de dimensions, catégories ou critères :
- Précision : les données expriment correctement les activités du métier ;
- Complétude : toutes les données nécessaires à l’observation du métier sont présentes ;
- Fraîcheur : les données sont à jour et sont disponibles dans des délais acceptables ;
- Cohérence : les données respectent toutes les contraintes définies par le métier et ne présentent pas de contradictions ;
- Consistance : les données ne présentent pas de doublon ;
Les définitions de ces critères restent cependant assez limitantes parce que difficilement mesurables. L’idée est de trouver des métriques objectives permettant de les refléter et les évaluer.
Origine de la non-qualité des données
Dans une architecture multi-sources et où la quantité de données récupérées est importante, les raisons pouvant induire une mauvaise qualité sont multiples.
Parmi les principales, on peut citer :
- Des erreurs de saisies au niveau des sources, particulièrement si les données sont entrées manuellement ;
- Une perte de données ou l’introduction d’erreurs à la suite d’un process de migration ;
- Des incohérences liées à de la réplication d’information conduisant à des problèmes d’incohérence de l’information ;
- Une mauvaise interprétation ou compréhension des données…
Dans ce contexte, il est primordial de pouvoir déterminer des méthodes, d’identifier des métriques et des outils pour définir, mesurer, interroger et contrôler la qualité des données.
Les étapes de vérification des données
Le management de la qualité de la donnée est un processus continu. Il est important d’agir le plus tôt possible dans le cycle de vie de la donnée.
Voici un schéma qui présente l’approche globale de ces étapes :

Étape 1 : s’assurer de la bonne réception de la donnée
Il ne sert à rien d’avoir les meilleurs algorithmes de Data Correctness, si aucune donnée n’est acquise. Il est vital de mettre en place des tests unitaires de réception de la donnée, surtout lorsque la source n’est pas maîtrisée et donc soumise à modification sans notification. De plus, la source peut aussi subir des indisponibilités. Il est donc essentiel de monitorer le volume de la donnée reçue pour détecter au plus tôt cette indisponibilité.
Étape 2 : définir les contraintes
Les données obtenues après la phase d’ingestion nécessitent une analyse plus rigoureuse en termes de qualité. En effet, l’objectif est de se servir de cette donnée pour alimenter des modèles de Machine/Deep Learning, peu robustes face aux erreurs de types ou à des données manquantes ou indéfinies.
Pour cela, il est nécessaire de nettoyer la donnée et la « formater » afin qu’elle puisse répondre aux exigences des modèles et être correctement exploitée.
Ce travail de préparation en amont peut être chronophage et très fastidieux. D’où l’intérêt d’automatiser certains traitements. Des solutions comme « Dataframe Rules Engine » ou encore la solution à venir « Delta Pipeline with Expectations » de DataBricks, proposent un outil d’exploration des tables qui permet de valider les tables de données avant une mise en production. Il est nécessaire de clarifier ce que l’on attend en input. La mesure objective de la qualité de ces entrées vis-à-vis d’une attente de sortie, peut s’effectuer via la définition de métriques. Ces valeurs calculées vont servir d’indicateurs de qualité.
Un Data Engineer et un Data Scientist prennent en charge des indicateurs différents. Un Data Engineer s’intéresse à la donnée de façon unitaire, c’est-à-dire sans les corréler entre elles. Pour ce faire, il s’intéresse aux mesures heuristiques spécifiquement conçues pour un dataset donné. Il s’agira de vérifier que les données correspondent bien à un schéma, comme de vérifier qu’une date a le bon format ou qu’une colonne « Nom Prénom » contient bien au moins deux chaînes de caractères. Un Data Engineer regarde également la complétude des données à un niveau basique. Il va donc regarder si un champ peut être « null », à quelle fréquence, et si le dataset possède un « trou » (par exemple une donnée journalière qui serait manquante certains jours).
Un Data Scientist regarde la donnée plus dans son ensemble pour vérifier si elles correspondent à des mesures prédéfinies. Cela permet de s’assurer que les types de données sont bien cohérents avec ce qui est attendu et que certaines valeurs statistiques sont bien respectées. Par exemple, il peut s’intéresser au fait qu’un paramètre numérique doit rester dans un certain intervalle de valeurs ou avoir une certaine distribution. Il peut également vérifier que les données suivent des règles métiers définies pour vérifier leur cohérence. Ces tests simples peuvent permettre d’identifier rapidement des valeurs anormales qui fausseraient les résultats d’analyse.
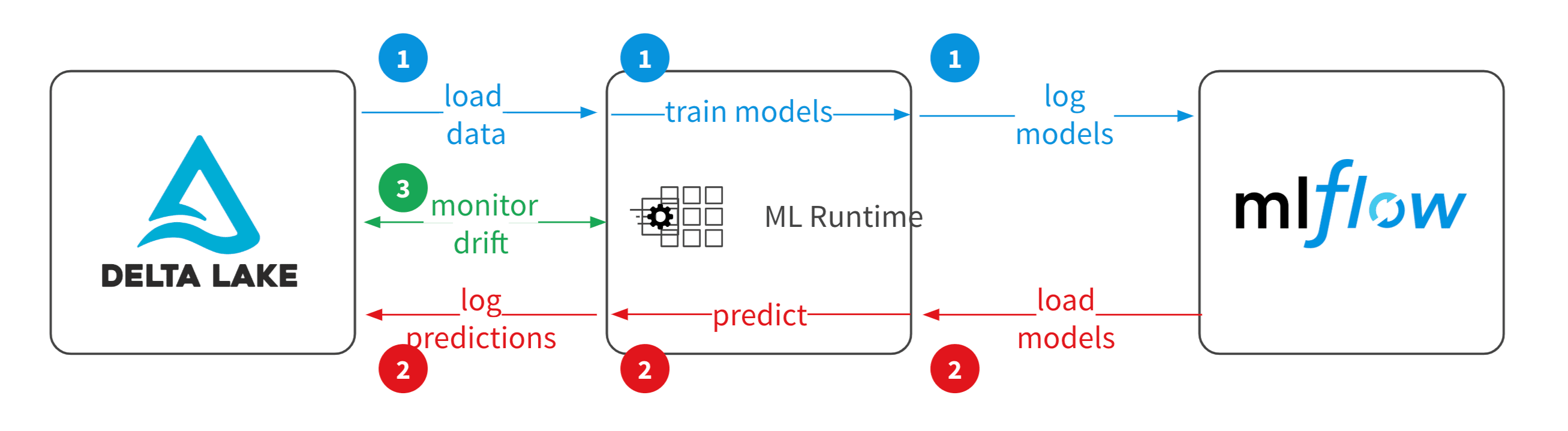
Étape 3 : monitorer le phénomène de Data Drift avec MLFlow
La dérive des données est l’une des principales raisons pour lesquelles la précision des modèles se dégrade avec le temps. Pour les modèles d’apprentissage machine, la dérive des données est la modification des données d’entrée du modèle qui entraîne une dégradation des performances du modèle. Le suivi de la dérive des données permet de détecter ces problèmes de performance du modèle.
Plusieurs causes peuvent expliquer la dérive des données :
- Les changements de processus en amont, comme le remplacement d’un capteur qui fait passer les unités de mesure de pouces à centimètres ;
- Des problèmes de qualité des données (par exemple un capteur cassé qui affiche toujours 0) ;
- La dérive naturelle des données, comme la température moyenne qui change avec les saisons.
Une façon courante de détecter la dérive d’un modèle est de surveiller la qualité des prévisions de sortie. Cette surveillance peut s’effectuer via l’outil MLFlow. Une fois qu’un modèle est entrainé et déployé sur MLFlow, vous pouvez enregistrer et surveiller deux types de données :
- Les mesures de performance du modèle, qui font référence aux aspects techniques du modèle, tels que la latence d’inférence ou l’empreinte mémoire. Ces mesures peuvent être enregistrées et surveillées facilement lorsqu’un modèle est déployé sur des bases de données ;
- Les mesures de qualité du modèle, qui dépendent des étiquettes réelles. Une fois que les étiquettes sont enregistrées, vous pouvez comparer les étiquettes prévues et réelles pour calculer les mesures de qualité et détecter les dérives dans la qualité prédictive du modèle.
Le suivi de l’évolution des performances modèles au cours du temps permet de détecter des points de chute pouvant être expliqués par un phénomène de data drift.
Étape 4 : vérifier la donnée avec « Great Expectations »
Le nettoyage de la donnée et la maintenance des pipelines data prennent une grande partie du temps de travail des spécialistes de la data. Il existe désormais des outils d’aide à l’automatisation des tâches, comme le projet Open-Source « Great Expectations » qui permet de tester, documenter et profiler les pipelines data dans l’intégration continue (CI). La vérification de la donnée par cet outil permet d’allouer plus de temps à l’analyse de son intégrité. En effet, Great Expectations donne accès aux dataset durant la CI pour la valider, la profiler et/ou la documenter.
Étude de cas : vérification des données
Dans le but d’illustrer ces propos, voici les résultats d’une étude que nous avons effectuée sur l’open-dataset « Oxford COVID-19 Governement Response Tracker ». Cette étude a été réalisée par un Data Engineer et un Data Scientist le 6 octobre 2020 sans support métier sur une période courte (quelques heures) à l’aide de Databricks.
Dans le code qui suit, le dataset est chargé dans le dataframe ayant pour nom « df ».
Vérification de la complétude du dataset
Pour voir la complétude du dataset, groupons le dataset par date croissante :
display(df.groupBy("date").count().orderBy("date"))

Vérification de la fraîcheur des données
Le dataset possède des données jusqu’au 5 octobre 2020, soit la veille de la date de l’étude : les données sont donc fraîches.
Vérification de la consistance des données
Pour vérifier la consistance, il faut regarder si le dataset possède des doublons. Le dataset est supposé donner les actions du gouvernement par jour et par pays. L’ONU nous dit que le monde compte 193 Etats ; or dans notre analyse, nous avons vu que nous avons 242 lignes par jours. Analysons plus en profondeur en faisant un comptage de jour par pays :
display(df.groupBy('countrycode').count())

Il semblerait qu’il y ait deux incohérences. Enlevons ceux qui ont le bon nombre de dates pour nous en assurer :
display(df.groupBy("countrycode").count().where(col("count") != 285))

Il y a bien deux incohérences au niveau de « GBR » (Grande-Bretagne) et « USA » (Etats-Unis). Si nous ciblons sur « GBR » :
display(df.where(col("countrycode")== 'GBR').groupBy("date").count().orderBy("date"))

Ainsi le dataset aurait 5 lignes par jours. En y réfléchissant, la Grande-Bretagne est composée de 4 pays (Angleterre, Ecosse, Pays de Galles et Irlande du Nord) : le dataset comporterait donc une ligne par pays et une ligne pour la Grande-Bretagne en général (ceci n’est qu’une spéculation de notre part, qui nécessiterait confirmation avec le métier ou avec une personne ayant connaissance de ces données). Si nous examinons ces cinq lignes pour un jour donné :
display(df.where((col("countrycode")== 'GBR') & (col('date') == "2020-03-25")))

Nous constatons que nous n’avons à l’heure actuelle pas de colonne qui permettrait de différencier ces lignes. Ce problème est le même avec les USA où nous comptons 53 lignes pour chaque date (nous supposons que nous avons au moins 1 ligne par État) et toujours aucun moyen de les dissocier.
Vérification de la précision des données
Pour vérifier la précision du dataset, regardons un cas concret et examinons les dates pendant lesquelles la France a subi un confinement :
display(df.where((col("countrycode") == 'FRA') & (col("c6_flag")== 'true')))

En regardant le dataset, la colonne « c6_stay_at_home_requirements » est à 2 du 17 mars 2020 jusqu’au 10 mai 2020, puis passe à 1 du 11 mai 2020 au 21 juin 2020. Le 17 mars correspond bien au début du confinement en France, le 11 mai au début du déconfinement et le 21 juin correspond à la fin de la phase 2 du déconfinement.
Avec ces informations, on pourrait en déduire que la précision est bonne. Cependant, dans la mesure où nous ne l’avons vérifiée que pour un seul pays, il faudrait envisager de faire cette étude sur plusieurs pays et différents éléments du dataset pour nous en assurer.
Vérification de la cohérence des données
Pour établir la cohérence du dataset, il faut vérifier les règles métiers. Par exemple, on peut regarder que si le confinement est en vigueur, alors les écoles sont bien fermées :
display(df.where((col("c6_flag")=='true') & (col("c1_flag")=='false')).groupBy('countryname').count())

Notre analyse nous montre que cela n’est pas le cas pour 35 pays. Il serait alors intéressant d’analyser plus en détail ces pays pour comprendre ces données. Est-ce que le pays avait une loi particulière régissant cela ? Est-ce une particularité que nous ne connaissons pas ? Est-ce une erreur du dataset ? Il est essentiel de pouvoir trouver une réponse à ces questions avant d’entreprendre l’utilisation de ce dataset dans un projet.
Utilisation de l’outil Great Expectations
Cet outil peut être utilisé pour facilement vérifier si une colonne est dans le bon format ou si les valeurs semblent correctes. Par exemple, vérifions le nombre de valeurs qui sont nulles pour la colonne « c1_school_closing » et si l’ensemble des valeurs de la colonne « date » représente correctement une date.
Pour cela, nous devons au préalable convertir notre dataframe dans un format supporté par Great Expectations :
import great_expectations as ge import pandas as pd dfP = df.toPandas() dfGe = ge.from_pandas(dfP)
Maintenant, il est possible de vérifier les colonnes :

Nous voyons qu’il y a 2708 valeurs qui sont « null » dans la colonne « c1_school_closing », ce qui correspond à 3.74 % de l’ensemble des valeurs.

Nous constatons donc qu’il n’y a aucun problème dans la colonne « date ».
Ici, nous avons fait des tests simples et non-automatisés. Cependant, l’outil est bien plus puissant : il offre la possibilité d’intégrer des tests similaires directement dans une CI ou dans un pipe Data permettant d’obtenir des rapports détaillés sur l’ensemble d’un dataset.
Résultats de notre analyse
Malgré une analyse peu poussée, nous avons trouvé dans le dataset des soucis qui nécessitent une investigation plus poussée. Cette investigation peut mener à l’amélioration de la collecte de la donnée en amont ou à mieux comprendre comment lire le dataset.
L’analyse, que nous avons produite ici, est une analyse à un jour donné qui permet de faire un état des lieux d’un dataset. L’étape suivante serait de faire une analyse automatique à une période donnée (en fonction de la période d’acquisition) pour vérifier la donnée régulièrement, et de sauvegarder ces résultats, à l’aide de logs ou autre. Ces derniers permettront in fine de vérifier la qualité de la donnée tout au long de son évolution.
La data correctness, étape incontournable d’un projet Data
La Data Correctness est un point essentiel à tout projet Data. C’est cette étape qui permet de savoir si la donnée est suffisamment mature pour être utilisée. Elle permet également de mieux comprendre le métier dont est issue la donnée. En effet, il est nécessaire de travailler en étroite collaboration avec le métier à ce niveau pour savoir ce que la donnée est censée mesurer et le vérifier.
✍️ Cet article a été co-rédigé par nos experts data : Stéphane Delarue et Jade Amraoui.






