

Comment RAJA Group a construit une plateforme data unifiée avec Microsoft Fabric – et comment Cellenza a contribué à écrire...
5 octobre 2021
Droit à l’oubli : quel impact sur la donnée ? Quelles procédures mettre en place ?

L’entrée en vigueur du RGPD (Règlement Général sur la Protection des Données) a bousculé les pratiques des entreprises en matière de gestion des données personnelles, mais il est un droit consacré par ce texte qui a posé – et pose toujours – de sérieuses difficultés d’implémentation technique : le droit à l’oubli.
Si la tâche peut être plus aisée pour certaines entreprises centrées sur le consommateur comme Facebook ou Google, d’autres entreprises qui ont construit leur système d’information en silo par exemple ont pu éprouver plus de difficultés pour mettre en place des procédures de suppression des données personnelles.
Cette procédure de suppression peut s’avérer difficile déjà concernant les données en production ; mais qu’en est-il pour les backups ? Comment supprimer une donnée contenue dans une archive sans altérer les autres ?
Pour faciliter le travail de mise en conformité des entreprises, de nouvelles solutions et bonnes pratiques sont apparues :
- Pour les données de production, le Delta Lake propose des fonctionnalités comme le change feed pour propager les suppressions des données personnelles ;
- Pour les backups, nous verrons quelles actions mettre en place en fonction des capacités techniques de l’entreprise.

Le droit à l’oubli consacré par le RGPD : quel impact sur la donnée ?
La consécration d’un droit existant ?
Le droit à l’oubli numérique consacré par le RGPD n’est pas une nouveauté. Ce droit était déjà évoqué dans la Loi Informatique et Libertés (n° 78-17 du 6 janvier 1978) et dans la Loi pour une République numérique de 2016 à propos des mineurs (n° 2016-1321 du 7 octobre 2016).
Au niveau européen, c’est lors de l’affaire dite Google Spain de 2014 qu’est introduit un droit au déréférencement : la Cour de Justice de l’Union Européenne (CJUE) donnera raison à un particulier espagnol qui considérait que les premiers résultats retournés par le moteur de recherche en tapant son nom lui portaient préjudice, obligeant Google à mettre en place une procédure de déréférencement en ligne. Ce droit au déréférencement n’était pas absolu puisqu’il restait à mettre en balance avec le droit à l’information.
Le RGPD clarifie certains flottements juridiques et redéfinit les limites de ce droit à l’oubli.
Une redéfinition des limites du droit à l’oubli par le RGPD
L’article 17 du règlement nᵒ 2016/679, dit Règlement Général sur la Protection des Données (RGPD) entré en vigueur le 25 mai 2018 consacre donc un droit à l’effacement ou droit à l’oubli numérique. Il va plus loin que les textes qui l’ont précédé en détaillant à la fois les conditions pour lesquelles le responsable de traitement a l’obligation d’effacer des données à caractère personnel mais aussi les limites de ce droit.
Le responsable du traitement a l’obligation d’effacer les données personnelles de la personne concernée dans l’une des situations suivantes :
- les données ne sont pas ou plus nécessaires au regard des objectifs pour lesquels elles ont été initialement collectées ou traitées ;
- la personne concernée retire le consentement sur lequel est fondé le traitement et il n’existe pas d’autre fondement juridique au traitement ;
- la personne concernée s’oppose au traitement et il n’existe pas de motif légitime impérieux pour le traitement ;
- les données font l’objet d’un traitement illicite (données volées/piratées par exemple) ;
- les données doivent être effacées pour respecter une obligation légale.
Ce droit à l’effacement n’est cependant pas absolu : il est écarté dans un nombre de cas limité. Il ne doit pas aller à l’encontre :
- de l’exercice du droit à la liberté d’expression et d’information;
- du respect d’une obligation légale (ex. délai de 10 ans de conservation des factures clients et fournisseurs) ;
- de l’utilisation de vos données si elles concernent un intérêt public dans le domaine de la santé;
- de leur utilisation à des fins archivistiques dans l’intérêt public, à des fins de recherche scientifique ou historique ou à des fins statistiques;
- de la constatation, de l’exercice ou de la défense de droits en justice.
L’organisme dispose d’un délai d’un mois à compter de la réception de la demande de suppression de données personnelles pour s’exécuter – si la demande répond bien aux exigences ci-dessus. En cas d’absence de réponse ou d’insuffisance de réponse, le demandeur peut saisir la CNIL.
D’autres États se sont inspiré du RGPD : c’est le cas par exemple de l’État de Californie et de son California Consumer Privacy Act (CCPA) entré en vigueur le 1er janvier 2020 qui prévoit un droit similaire pour les consommateurs de demander la suppression des données collectées auprès d’eux (CCPA – 1798.105 – Consumers right to deletion).
Nous nous concentrerons dans cet article sur les procédures d’effacement que doivent mettre en place les entreprises pour leur Data Lake et pour la gestion de leurs backups.
Quelles procédures mettre en place ?
Le Data Lake a pu apparaître au début comme allant à l’encontre du principe de minimisation posé par le RGPD. Cependant, il permet au contraire d’avoir une vision globale des données, et notamment des données personnelles. Encore faut-il avoir les bons outils pour maitriser ce Data Lake : en production, le format Delta Lake permet de faciliter l’identification et la traçabilité des données personnelles à l’aide de plusieurs fonctionnalités dont le change feed.
Le Delta Lake pour supprimer les données personnelles et les données obsolètes
Le Delta Lake se présente sous la forme d’une couche de stockage open source apportant les transactions ACID à Apache Spark ce qui améliore la fiabilité des données d’un Data Lake. Il apporte également d’autres fonctionnalités comme la gestion de l’historique – puisqu’une table Delta Lake est composée de fichiers au format parquet et de logs transactionnels – ou encore l’ajout des opérations de type DELETE, UPDATE et UPSERT.
Si vous voulez aller plus loin sur le sujet : https://blog.cellenza.com/data/pourquoi-utiliser-delta-lake/
Nous prendrons pour notre démonstration un jeu de données gdpr mis à disposition par Databricks (cf. liens à la fin de cette section) qui contient 65 millions de lignes, chacune contenant des ID de clients distincts pour un total d’environ 3Go.
Une table gdpr.customers contient les informations personnelles des clients, dont voici le schéma :
Une autre table gdpr.customer_delete_keys contient une liste de clients qui ont exercé leur droit à l’oubli via un portail online :
Grâce à l’ID du clients (c_customer_id), nous allons pouvoir identifier les données personnelles à supprimer.
Etape 1 : convertir les étapes au format Delta
Avant de pouvoir utiliser les avantages du Delta Lake, les données brutes (parquet, JSON, CSV, etc.) doivent être ingérées et converties au format Delta.
Le jeu de données que nous allons utiliser est au format parquet. Nous allons commencer par le convertir au format Delta :
Etape 2 : les suppressions
Maintenant que nos données sont converties, nous pouvons effectuer la suppression des données correspondantes, en supprimant les clients référencés dans la table gdpr.customer_delete_keys de notre table gdpr.customers :
Nettoyer des données obsolètes
Par défaut, Delta Lake garde l’historique de la table pendant 30 jours. Cela signifie qu’il est possible de revenir à une version antérieure de la table grâce à cet historique après avoir supprimé des données personnelles suite à la demande d’un utilisateur.
Pour éviter cela, vous pouvez utiliser la fonctionnalité VACUUM, pour supprimer les fichiers qui ne sont plus référencés pas une Delta table et qui sont antérieurs à un certain seuil de rétention (7 jours par défaut) :
Utiliser le change feed de Delta Lake
Avec cette fonctionnalité de change feed activée, le runtime enregistre les « évènements de modification » des données contenues dans une table : les données de ligne et les métadonnées indiquant le type d’opération (insert, delete, update).
Vous pouvez utiliser cette fonctionnalité pour propager des modifications en envoyant les données modifiées aux systèmes en aval (vers un SGBDR ou d’une table Silver vers Gold dans un Data Lake par exemple).
1. Activer le change feed
Cette fonctionnalité est disponible à partir du Databricks Runtime versions 8.4 et n’est pas activée par défaut. L’activation peut se faire table par table ou pour toutes les nouvelles tables :
Les modifications apportées avant l’activation ne sont pas capturées. Seules les modifications effectuées après l’activation seront écrites dans le dossier _change_data sous chaque répertoire de la table Delta.
2. Propager les modifications apportées à une table Silver vers une table Gold
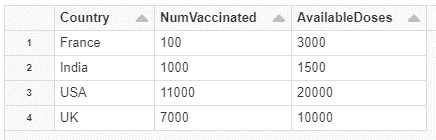
Nous allons propager des modifications d’une table Silver contenant le nombre de vaccinations par pays vers une table Gold contenant le taux de vaccination par pays :
Table Silver :

Table Gold :

- Activons le change feed et appliquons quelques modifications sur la table :
Output de la Table Silver :
Un DESCRIBE HISTORY vous aidera à vérifier si une modification a été effectuée avant ou après l’activation du change feed :

- Explorons maintenant les changements enregistrés par la fonctionnalité change feed :

- Puis propageons ces modifications effectuées sur la table Silver vers la table Gold :
Output :

Nous pouvons vérifier que les modifications effectuées dans la table Silver ont bien été répercutées sur la table Gold comme souhaité !

Vous pouvez retrouver le use case Microsoft complet dans ce notebook.
Si vous souhaitez aller plus loin :
- Sur la conformité au RGPD avec Delta Lake : https://docs.databricks.com/security/privacy/gdpr-delta.html
- Sur le change feed : https://docs.microsoft.com/en-us/azure/databricks/delta/delta-change-data-feed
Ces fonctionnalités permettent donc d’appréhender plus aisément la gestion de la suppression des données personnelles dans un Data Lake ; mais qu’en est-il pour les données stockées dans les backups et les archives ?
La gestion des services et des archives
L’entreprise a un mois pour répondre à une demande de suppression de données personnelles et s’assurer que les données en question sont effacées de ses systèmes. Nous avons supprimé les données personnelles de notre Data Lake (données en production), mais qu’en est-il des données stockées sur un backup ? Que faire des données contenues dans des sauvegardes de longue durée ? En cas de restore d’un backup, comment procéder tout de même au ménage des données qui doivent être supprimées ? Comment, malgré tout, garantir l’intégrité d’un backup après cette opération alors que certains ne donnent pas la possibilité de recherche ou de suppression sans restaurer complètement le backup ?
Supprimer ces données personnelles d’une sauvegarde peut apparaître comme un véritable challenge, voire un cauchemar.
Mais les autorités de contrôle connaissent la difficulté de l’implémentation de cette obligation en pratique et adapteront leurs exigences en fonction :
- des circonstances particulières,
- de la durée de rétention prévue pour ces backups,
- et des possibilités techniques pour l’organisation de supprimer ces données.
Vous devez également être transparent avec l’utilisateur qui aura fait la demande de suppression, en lui expliquant que sa demande sera réalisée dans les systèmes « actifs » mais que les sauvegardes suivent un autre cycle de rétention qui permettra l’exécution effective de la demande seulement dans un second temps.
En résumé, voici les actions que vous pouvez mettre en mettre en place pour vos backups :
- Prévoir une durée de sauvegarde précisée, limitée et raisonnable ;
- Informer les utilisateurs qui ont exercé leur droit à l’oubli que ces données seront conservées suivant le calendrier de rétention, et préciser ce calendrier ;
- Mettre en place un journal des suppressions qui permettra aux administrateurs des bases de données de supprimer automatiquement les données lors des restaurations de sauvegardes (ce journal doit également respecter le principe de minimisation des données) ;
- Ne pas utiliser le backup à d’autres fins que pour restaurer un environnement technique ;
- Mener une analyse des risques et d’impact sur les procédures et la protection des données afin de démontrer à l’autorité de contrôle que supprimer les données de backup est techniquement impossible immédiatement ; et documenter les procédures et politiques de sécurité de ces données (emplacement, chiffrage, etc.).
Pour aller plus loin :
Que ce soit pour les données « à chaud » ou « à froid », le droit à l’effacement reste un défi constant pour les entreprises. Depuis l’entrée en vigueur du RGPD, de nouvelles solutions techniques facilitent toutefois cette tâche.
Le RGPD aura contribué à rationaliser la collecte et la rétention des données par les entreprises, mais également à s’assurer d’une meilleure protection et sécurité de celles-ci, notamment à l’aide du chiffrage : rendez-vous dans notre article suivant de cette série pour en savoir plus sur ce sujet !
Retrouvez tous nos articles du Mois de la Data Privacy & Transparency :
- Data Privacy & Transparency : la protection des données en entreprise
- Chiffrement homomorphe : comment protéger les données personnelles et garantir leur non déchiffrement ?
- Sécurité des lignes et des colonnes avec Databricks
- Comment protéger une infrastructure Cloud contre la fuite de données ?
- Comment travailler avec une base de données chiffrées ?
Sans oublier le replay de notre webinaire sur le thème « Protéger et sécuriser vos données : quels impacts sur vos process ? », animé par nos experts : Matthieu Klotz (CTO Data/IA), Nathalie Fouet (consultante Data/IA) et Amine Kaabachi (consultant Data/DataOps) :





