

Comment RAJA Group a construit une plateforme data unifiée avec Microsoft Fabric – et comment Cellenza a contribué à écrire...
12 octobre 2021
Read this post in English
Sécurité des lignes et colonnes avec Databricks

Article co-rédigé avec Himanshu Arora, Data Solution Architect chez Databricks
Comme vous l’avez vu dans l’article sur le droit à l’oubli, la réglementation européenne impose des règles strictes en matière de gouvernance des données. D’autre part, il est capital de catégoriser vos données en fonction de leur criticité afin de positionner les droits d’accès à celles-ci. C’est pourquoi la gouvernance des données est un enjeu majeur, complexe et protéiforme pour les entreprises. L’accès aux données fait partie de cette gouvernance.
Les bases de données relationnelles proposent depuis plusieurs années des mécanismes pour contrôler et limiter ces accès.
L’exploitation des données stockées dans un data lake est plus récente. Cependant, la problématique reste la même, peu importe le stockage.
En utilisant Databricks, il est possible de mettre en place des sécurités au niveau des lignes (row-level security) ou au niveau des colonnes (column-level security).

Limitation des accès aux colonnes et aux lignes avec Azure Databricks
Le principe est le même pour la sécurité des lignes ou celle des colonnes.
Vous allez devoir définir des groupes d’utilisateurs, puis créer des vues et donner accès à ces vues aux groupes en fonction de ce que les utilisateurs sont autorisés à voir.
Row level security
La sécurité des lignes s’effectue en positionnant une clause spécifique pour une vue donnée.
Dans cet exemple, nous allons travailler sur une table de ventes dans laquelle on trouve les ventes réalisées par deux régions commerciales : la région Est et la région Ouest.

Les commerciaux doivent avoir accès uniquement aux ventes de leurs régions respectives : un commercial de la région « Ouest » doit voir uniquement les lignes dont la colonne « RegionCommerciale » a la valeur « Ouest » et vice versa.
La direction commerciale doit avoir accès à l’intégralité de la table.
Il va donc falloir créer 3 groupes :
- Le groupe « Est » pour les commerciaux de la région Est
- Le groupe « Ouest » pour les commerciaux de la région Ouest
- Le groupe « Direction » pour la direction commerciale
Pour pouvoir faire le lien entre le groupe d’appartenance de l’utilisateur et les valeurs de la colonne « RegionCommerciale », nous allons utiliser la fonction IS_MEMBER pour déterminer les lignes auxquelles l’utilisateur aura accès.
Création des groupes
Pour créer les groupes, vous devez vous rendre dans la console d’administration « Admin Console » :
Puis cliquer sur le bouton « Create Group » :

Et enfin, donner un nom au groupe. Ici, le groupe « Est » :

Une fois le groupe créé, il faut affecter le ou les utilisateurs au groupe :

Mon utilisateur a été ajouté au groupe « Est ».
La commande ci-dessous teste si l’utilisateur actuel appartient au groupe « Est ».

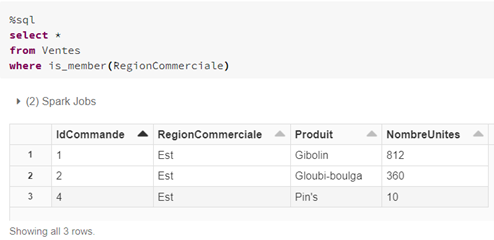
En sélectionnant la table « Ventes » avec une condition qui utilise la fonction « is_member » en s’appuyant sur les valeurs de la colonne « RegionCommerciale », le résultat affiche bien uniquement les 3 lignes de la région commerciale « Est ».
L’étape suivante consiste à créer une vue en utilisant la requête précédente :

La consultation de cette vue nous renvoie bien les lignes de la région de l’utilisateur :

Un utilisateur du groupe « Ouest » aura le résultat ci-après à la consultation de la vue :

Le groupe « Direction » aura accès à l’intégralité de la table. Pour autoriser uniquement ce groupe à accéder à la table, il est nécessaire d’activer le contrôle d’accès aux tables (« table access control »).
Il y a 3 prérequis pour que vous puissiez utiliser cette fonctionnalité :
- Avoir un workspace en niveau de service Premium
- Le ou les utilisateurs ne doivent pas être autorisés à créer des clusters
- Il faut utiliser un cluster en mode « High Concurrency »

Une fois cela fait, vous pourrez activer la fonctionnalité au niveau du workspace :

Puis au niveau du cluster :

Enfin, donner le droit de consulter la table au groupe « Direction ».

Dans cet article, nous créons les groupes et affectons les utilisateurs manuellement. Il est bien sûr possible d’automatiser ces actions, par exemple, en utilisant le provider databricks de Terraform ou encore via databricks cli.
Lorsqu’il est nécessaire d’utiliser des groupes, le plus simple consiste à utiliser la fonctionnalité SCIM permettant de gérer des groupes AD.

Column level security
La sécurité des colonnes s’effectue en sélectionnant et en positionnant une condition sur le ou les champs en utilisant la fonction IS_MEMBER au niveau du « SELECT », et non plus au niveau de la clause « WHERE ».
Ci-dessous un exemple de table :
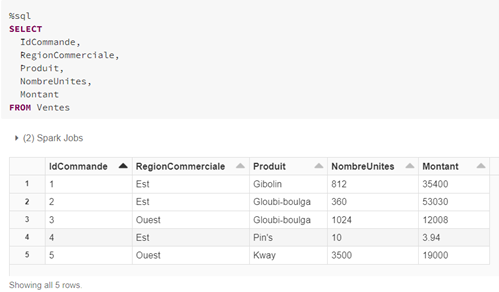
La création de la vue applique une condition pour l’affichage de la colonne « Montant ». Si l’utilisateur appartient au groupe de la colonne « RegionCommerciale », alors la valeur de la colonne « Montant » est affichée. Sinon, la valeur « Non autorisé » est affichée.

Voici l’affichage du résultat pour un utilisateur appartenant au groupe « Est » :

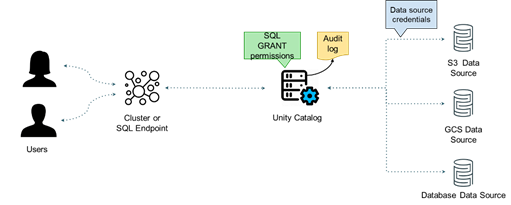
Unity Catalog
Nous avons vu qu’il est possible de positionner des règles sur la consultation des données.
Cependant, si différents workspace exploitent les mêmes données, il est nécessaire de répliquer la même configuration au travers de ces workspaces.
Unity Catalog vous permettra, à terme, de définir des règles qui pourront être appliquées à l’ensemble des workspaces au travers d’un catalogue partagé.
⚠️A noter : à ce jour, Unity Catalog est en bêta. Les exemples montrés ci-après peuvent être amenés à évoluer au cours du temps.
Ce catalogue permet, bien sûr, de gérer l’accès aux données mais également l’accès aux notebooks, l’accès aux modèles, etc.
Sachant que ce catalogue est géré au niveau du compte Databricks, il permet d’être agnostique au Cloud provider.
D’autre part, Unity Catalog cherche à créer un lien avec l’écosystème de catalogue existant. Cet écosystème est constamment en mouvement.
Vous pourrez gérer ce catalogue via une interface graphique dédiée à Unity Catalog.
En ce qui concerne les restrictions d’accès, elles se feront par l’intermédiaire d’attributs. Il faut donc d’abord créer un attribut. Dans l’exemple ci-dessous, l’attribut se nomme « pii » (pour « personal identifiable information ») :
CREATE ATTRIBUTE pii
Il faut enseigner marquer les colonnes concernées avec l’attribut. La table iot_events avec la colonne « email » ainsi que la table users avec la colonne « phone » sont concernées :
ALTER TABLE iot_events ADD ATTRIBUTE pii ON email ALTER TABLE users ADD ATTRIBUTE pii ON phone ...
Et enfin, il est possible d’interdire l’accès aux colonnes marquées de cet attribut à un groupe d’utilisateurs :
GRANT SELECT ON DATABASE iot_data HAVING ATTRIBUTE NOT IN (pii) TO product_managers
Unity Catalog proposera également les logs d’audit pour l’accès aux colonnes liées à un attribut.
Une gestion facilitée et centralisée
Les bases de données relationnelles mettent à disposition depuis longtemps des fonctionnalités permettant de limiter les accès aux données. Bien que plus récents que les bases de données relationnelles, les outils exploitant des données depuis un data lake commencent à se doter de fonctionnalités comparables en termes de gouvernance.
Unity Catalog va apporter plus de facilité afin de gérer celle-ci tout en centralisant cette gestion.
Pour aller plus loin
Vous souhaitez approfondir le sujet et en savoir plus sur la gestion transparente et sécurisée des données ? Nous vous invitons à consulter nos autres articles de cette série :
- Data Privacy & Transparency : la protection des données en entreprise
- Droit à l’oubli : Quel impact sur la donnée ? Quelles procédures mettre en place ?
- Chiffrement homomorphe : comment protéger les données personnelles et garantir leur non déchiffrement ?
- Comment protéger une infrastructure Cloud contre la fuite de données ?
- Comment travailler avec une base de données chiffrées ?
Sans oublier notre livre blanc téléchargeable gratuitement et le replay du webinaire animé par nos experts data :
Article co-rédigé par Donatien Tessier et Imanshu Arora





