

Comment RAJA Group a construit une plateforme data unifiée avec Microsoft Fabric – et comment Cellenza a contribué à écrire...
6 octobre 2020
Gérez vos projets data avec Azure DevOps

La semaine dernière, nous avons publié le premier article de notre Mois de la Data « Organisation de la data en entreprise : les outils indispensables ». Nous vous invitons vivement à le découvrir avant d’aller plus loin sur ce nouveau sujet !
Pour le deuxième article de cette belle et longue série, nous allons essentiellement vous expliquer comment l’approche DevOps peut vous aider dans vos projets de Data.
L’approche DevOps au service de la Data
Le DevOps est avant tout un mouvement de pensée, une culture dans laquelle on cherche à produire toujours plus efficacement de la valeur pour nos métiers. Pour cela, on va bien sûr s’appuyer sur des outils, mais également sur les personnes et leurs collaborations.
Bien que le plus souvent, l’approche DevOps est évoquée dans le cadre de projets web, ou cloud-native, ce n’est absolument pas une limitation. Un projet data peut également bénéficier des apports du DevOps.
En nous appuyant sur le partenariat entre Databricks et Microsoft, nous allons voir plus en détail quels outils peuvent être utilisés pour fluidifier l’apport de valeur métier au quotidien.
Tout d’abord, nous verrons comment gérer le code source de l’application. Dans un deuxième temps, nous étudierons comment versionner et maintenir l’infrastructure.
Nous nous pencherons ensuite sur l’automatisation des tests sur cette plateforme data.
Enfin, nous verrons comment automatiser le déploiement de l’ensemble de l’application, infrastructure comprise, à l’aide d’Azure DevOps.
Comment gérer vos projets data ?
Gestion du code : collaboration et versioning
Deux des éléments essentiels à la bonne santé d’un projet data sont, comme pour tout type de projet de développement logiciel, la collaboration et la traçabilité.
A moins d’être seul sur le projet, il faut être capable d’intégrer les développements de plusieurs personnes. Qu’il s’agisse d’un travail commun ou de fonctionnalités séparées, il est nécessaire de collecter le travail de chacun et d’être capable de l’intégrer à une version à livrer.
La gestion de code source et le versioning répondent à ce besoin. Git est un outil puissant, qui nécessite un peu d’apprentissage, mais les possibilités qu’il offre valent bien cet investissement.
D’autres gestionnaires existent mais Git reste, de loin, le plus utilisé et probablement le plus efficace.
Mise en place d’une stratégie de branche
Tous les gestionnaires de code source offrent la possibilité de travailler dans des espaces isolés : on parle de branches de développement.
Avec Git, il existe plusieurs approches, plus ou moins simples. Il n’existe malheureusement pas de stratégie miracle : il sera donc nécessaire de déterminer celle qui conviendra le mieux au projet et à l’équipe.
L’une des stratégies les plus simples à mettre en place est celle que l’on nomme « Trunk based development » ou encore « TBD ».
On travaille ici avec une branche principale dans laquelle viennent s’intégrer tous les développements. Ceux-ci sont réalisés dans des branches de topic, souvent appelées « branches de features ».
Voici un schéma simplifié de cette stratégie de branche :

Dans cette stratégie, chaque nouveau développement est réalisé dans une branche issue du tronc commun. Lorsque le travail est terminé et prêt à être intégré, on réalise un merge dans la branche master.
Généralement, cette fusion se fait par le biais d’une Pull Request (ou Merge Request). Il s’agit d’une étape de validation qui permet de relire le code.
La relecture de code est un moyen efficace pour :
- Repérer les bugs,
- Partager la connaissance,
- S’assurer que le code est homogène au sein de l’application.
Gestion de l’infrastructure
Lorsqu’un déploiement ne se passe pas comme prévu – généralement en production – on s’aperçoit qu’une des causes fréquentes provient de l’hétérogénéité des environnements.
Dans la pratique du DevOps, on répond à cette problématique à l’aide de ce que l’on nomme « l’infrastructure as code« . C’est-à-dire que l’infrastructure elle-même va être gérée de façon déclarative et que la configuration sera archivée dans un repo Git.
De plus en plus largement répandue, cette pratique s’applique également à notre écosystème applicatif.
Nous allons voir dans ce chapitre comment gérer notre infrastructure à l’aide de Terraform et des providers AzureRM et Databricks.
Les prérequis
Pour démarrer, vous aurez besoin :
- D’une souscription Azure,
- D’utiliser Terraform 0.12 ou supérieur,
- D’utiliser Databricks provider 0.2.5 ou supérieur,
- D’un compte de service Azure AD avec le rôle contributeur sur la souscription.
Composition de l’infrastructure
Dans cet article, nous nous limiterons aux ressources essentielles, mais vous pourrez trouver dans la documentation, ou dans d’autres articles à venir, quelques ressources supplémentaires très utiles. En particulier, il est possible de gérer la sécurité en configurant les utilisateurs, groupes et rôles.
Voici un schéma global de l’infrastructure que nous allons automatiser :

Nous disposerons de trois environnements : Dev, Test et Prod.
Chaque environnement sera géré via Terraform à partir d’un même modèle. Seuls quelques éléments configurables viendront différencier nos environnements. Nous n’avons donc pas besoin de déclarer trois fois les ressources, mais une seule fois pour tous les environnements. Nous déclarerons également quelques variables qui nous permettront de personnaliser les environnements, à commencer par leur nom.
Voyons maintenant en détail comment se décompose notre configuration Terraform pour un environnement.
Tout d’abord, nous avons besoin d’un groupe de ressources. Celui-ci contiendra notre workspace :
Ensuite, nous avons besoin d’un workspace Azure Databricks :
A l’aide de l’identifiant du workspace, nous pouvons configurer le provider Databricks :
Important : Rappelez-vous de ne jamais archiver les variables sensibles dans votre code. Terraform fournit plusieurs moyens de passer ces valeurs de façon sécurisée au moment de l’exécution. Reportez-vous à la documentation Terraform pour en savoir plus.
Pour cet exemple simple, nous allons utiliser le provider Databricks pour créer un simple cluster dans notre workspace :
La version de spark est définie à l’intérieur de la configuration du cluster. L’avantage, c’est qu’à chaque environnement et chaque nouveau cluster, nous sommes assurés que la version sera exactement la même partout. Si nous écrivons un notebook dans une version spécifique, il sera compatible quel que soit le cluster sur lequel il va s’exécuter.
L’environnement n’est pas présent sous forme de variable. Comme nous le verrons plus loin dans le chapitre sur le déploiement, c’est une variable qui se trouvera en amont du déploiement Terraform. Nous l’utiliserons en revanche pour automatiser la création des noms des workspaces et des clusters.
Par exemple, pour l’environnement de Dev, notre workspace se nommera « wksp-dev » et notre cluster, « cluster-dev ».
Une fois les variables correctement initialisées, vous pouvez exécuter les commandes « terraform init » puis « terraform plan » pour voir quelles ressources s’apprêtent à être déployées.
A ce stade, le fichier « tfstate » sera local et le déploiement sera manuel. Nous verrons plus loin comment rendre tout ceci plus robuste, collaboratif et automatisé.
Phase de tests
Un des piliers de la culture DevOps consiste à livrer souvent de petits incréments produits, plutôt que de grosses évolutions.
Il devient alors plus facile de mesurer l’impact de ce qui vient d’être fait, et les risques de mise en péril de l’application sont bien moins grands.
Les tests unitaires
Les tests unitaires sont un bon moyen d’éviter les régressions. Ils nous donnent confiance dans nos livraisons et nous permettent de nous concentrer plus sur les nouvelles fonctionnalités que sur le testing ou la correction d’anomalies.
Les tests unitaires sont très répandus dans le monde du web : voyons comment les implémenter sur nos notebooks ou scripts, et comment les exécuter dans un contexte isolé de toute infrastructure.
Ce dernier point sera important lorsque nous aborderons la partie intégration continue.
Prenons comme exemple un notebook écrit en python.
Pour rendre l’exécution des tests facilement exportable, nous utiliserons une image Docker qui contient le nécessaire :
- python 3.8,
- pip,
- venv,
- open JDK 8,
- pyspark,
- pytest-spark.
Le tout sur une base ubuntu:latest
Voici le fichier Docker correspondant :
Pour exécuter vos tests, il ne vous reste alors plus qu’à monter un volume (ou bien copier vos sources dans l’image au moment du build), puis exécuter la commande « pytest » à la racine de votre répertoire contenant vos notebooks ou scripts et vos tests.
Le plugin pytest-spark va permettre d’utiliser pyspark dans les fonctions de tests, et de les exécuter dans un contexte similaire à celui d’un cluster.
Voici un exemple illustrant à quoi peut ressembler un test :
Et la fonction associée sur laquelle porte le test :
Sachez qu’il existe d’autres types de tests, qu’on lance généralement moins souvent et qui vont nécessiter de vrais environnements.
Les tests d’intégration
On parle de tests d’intégration lorsqu’ils visent à vérifier que votre cluster communique bien avec les différentes sources. Par exemple, il peut s’agir d’exécuter un pipeline Data Factory et de vérifier que les appels aux notebooks se font correctement.
Ces tests peuvent être exécutés sur un environnement préexistant ou sur un environnement créé à la demande pour l’occasion. Le fait d’utiliser une approche « infra as code » permet de créer un environnement entier pour un besoin spécifique et le supprimer dès qu’il devient inutile.
Les tests de performance
L’infra as code permet également de réaliser des tests de performance à moindre coût. Bien souvent, ces tests sont difficiles à réaliser car ils nécessitent des performances similaires à l’environnement de production. Grâce à l’infra as code, il est possible de créer un environnement équivalent, en termes de performances, avec une durée de vie si courte que l’impact financier sera acceptable, voire négligeable.
Smoke tests
Enfin, un dernier type de test peut être mis en place : il s’agit des tests « end to end », également appelés »smoke-tests ». Dans ce cas, on va s’assurer après chaque déploiement en production que la plateforme est opérationnelle. On peut par exemple déclencher l’exécution d’un notebook chargé de faire quelques vérifications sur les données. Il peut aussi s’agir de manipuler des données de test créées pour l’occasion, afin de ne pas impacter les données réelles de production.
L’intégration et le déploiement continu
Intégration continue : on parle d’intégration continue lorsque chaque modification de code déclenche une action de vérification du code, généralement en exécutant une série de tests unitaires automatisés.
Déploiement continu : on parle de déploiement continu lorsque chaque modification de code, après avoir passé l’étape des tests, se trouve déployée sur au moins un environnement. Le plus souvent, il s’agit d’un environnement de test.
Nous avons vu dans les chapitres précédents comment réaliser des tests unitaires et comment déployer notre infrastructure. Voyons maintenant comment orchestrer le tout, afin de déployer notre code en continue sur nos différents environnements.
Pour réaliser cela, nous allons utiliser Azure Pipelines et les définitions de build en YAML. Ceci nous permet de rester dans la logique « as code », puisque la définition même de notre pipeline sera archivée avec le reste du code dans le repo Git.
Pour rendre notre code plus maintenable et réutilisable, nous allons utiliser des templates YAML.
Voici à quoi va ressembler notre pipeline complet une fois terminé :
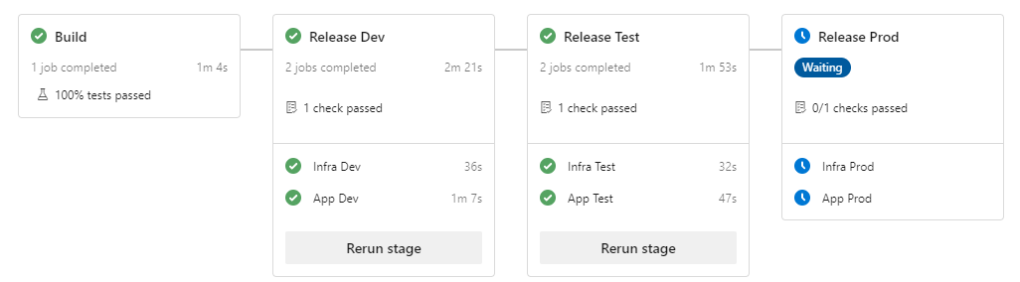
La phase de build
En ce qui concerne la première étape, il s’agit d’exécuter les tests unitaires et de packager les fichiers à déployer. En règle générale, on exécute cette étape à chaque fois que du code est archivé sur le repo Git. C’est le package de sortie, également appelelé « livrable », qui sera la source pour la phase de déploiement que nous verrons juste après.
La bonne pratique consiste à dire « builder une fois, déployer n fois ». Autrement dit, on ne va construire le package qu’une seule fois – il correspond à une version du produit – et que c’est ce livrable qu’on va déployer sur nos environnements (Dev, Test, Prod).
Le code YAML de cette étape est le suivant :
Nous utilisons ici une fonctionnalité des pipelines YAML qui nous permet d’exécuter nos tâches à l’intérieur d’un conteneur. Comme nous avons une image Docker contenant les outils nécessaires, nous avons préalablement poussé cette image sur une Azure Container Registry et nous allons la réutiliser dans notre pipeline.
Nous indiquons à pytest le format de sortie junit. Il s’agit d’un format nativement pris en charge par Azure DevOps. Cela va nous permettre d’intégrer l’étape de publication des résultats de tests. Nous pourrons alors constater dans le résultat du pipeline que tous les tests sont passés, ou bien lesquels ont échoué :

La phase de release
La phase de release démarre après la phase de build car avant de déployer, nous devons nous assurer que les tests passent. Si l’étape de build est un succès, le déploiement sur le premier environnement peut démarrer. Il s’agit dans notre exemple d’un environnement de Dev. Pour rappel, celui-ci est constitué d’un workspace Databricks et d’un cluster Spark dédié.
La release commence par une mise à jour de l’environnement lui-même. On applique la configuration Terraform, ce qui mettra à jour l’environnement si besoin, ou bien même le créera de toutes pièces s’il n’existe pas.
Voici le code de notre étape de déploiement de l’infra :
Cette fois, l’initialisation du backend se fait à l’aide d’un Storage Account Azure. Le fichier tfstate sera centralisé et accessible par Azure DevOps pour tous les déploiements.
Pour finir, le pipeline déploie les notebooks dans le workspace correspondant.
Le code YAML de cette dernière étape est le suivant :
Grâce à l’utilisation des templates, ce code est partagé entre tous les environnements. Ajouter un nouvel environnement ne prend pas plus de quelques minutes.
De plus, le fichier YAML qui représente notre pipeline est léger et facile à lire. Voici celui de notre exemple :
Le template db-env-release.yml est un simple conteneur qui permet d’assembler les jobs de déploiement infra et applicatif. Il fait lui-même appel aux précédents templates.
Dans le cas d’un déploiement sur un environnement « éphémère », il suffira d’ajouter une étape de « terraform destroy » à notre pipeline.
Gestion du monitoring dans un projet data
Le monitoring est un élément très important de la culture DevOps. Le développement ne s’arrête pas lorsque le logiciel arrive en production. Au contraire, il continue tant que vit le produit.
La tâche d’une équipe de développement data est donc de s’assurer en permanence que le produit fonctionne correctement et apporte la valeur métier pour laquelle il a été prévu.
Le monitoring doit permettre de détecter toute anomalie qui serait introduite suite à une livraison. Les livraisons se faisant en continu, le monitoring doit l’être également.
Il permet d’être informé très tôt d’un dysfonctionnement et de réagir rapidement en cas de problème. Cette rapidité d’action participe grandement à la satisfaction des utilisateurs, qui en retour seront davantage impliqués dans nos projets.
Le monitoring prend tout son sens dans un projet data notamment lorsqu’on parle de Data Correctness. Il permet non seulement de surveiller l’état de l’application, mais aussi de contrôler l’état de la donnée qui transite. Tout écart par rapport à l’état normal est alors immédiatement repéré et son origine peut être identifiée. Des actions peuvent alors être entreprises afin de corriger le problème.
Nous n’aborderons toutefois pas ce sujet en détail : un autre article y sera consacré prochainement.
Quand l’approche DevOps facilite les projets Data
Dans le passé, les outils utilisés dans le monde de la data ne se prêtaient guère au DevOps, pas plus que les outils DevOps ne se prêtaient au monde de la data.
Nous avons vu qu’aujourd’hui ce n’est plus vrai. Il existe en effet, grâce au Cloud et aux services managés, de quoi mettre en œuvre non seulement les outils, mais aussi les pratiques DevOps :
- La gestion du code source et la gestion des branches est facilitée par des outils comme Git, VS Code et ses extensions.
- L’intégration et le déploiement continus peuvent être mis en place grâce à des outils comme Azure DevOps ou GitHub actions.
- L’infrastructure as code permet divers scénarios de tests, tout en limitant les impacts liés à l’hétérogénéité des environnements.
- Enfin, l’utilisation d’outils comme Docker associés aux bibliothèques Python et autres langages, permet de réaliser des tests automatisés dans des environnements « jetables » facilement maintenables.
Ce que DevOps adresse comme problématiques depuis plusieurs années dans des domaines tels que le web, il les adresse aussi maintenant dans le cadre des projets data.
Il permet ainsi une plus grande qualité, une plus grande vélocité, et finalement une plus grande performance pour le métier et l’entreprise.
Tous ces outils sont en constante évolution. Aujourd’hui l’intégration du code source dans Git nécessite un éditeur tel que VS Code. S’il est très efficace, on peut regretter de ne pouvoir travailler directement dans l’éditeur en ligne. Prochainement, l’intégration avec Git sera améliorée grace aux Projets Databricks. Ceux-ci permettront d’exploiter la puissance de Git sans avoir à quitter le portail Databricks. Vous pouvez retrouver les premières annonces de cette nouvelle fonctionnalité sur le blog Databricks.
✍️ Cet article a été co-rédigé par nos experts data : Rémi Sorlin, Matthieu Klotz, Donatien Tessier et Quentin Ambard.






