

Comment RAJA Group a construit une plateforme data unifiée avec Microsoft Fabric – et comment Cellenza a contribué à écrire...
30 septembre 2020
Organisation de la data en entreprise : les outils indispensables

Les mutations de la transformation digitale ont généré un fort volume de données, structurées ou non, et sur des domaines variés : les produits, les clients, les processus, le financier, et autres.
La valorisation de cette donnée est désormais l’enjeu d’aujourd’hui et de demain afin d’améliorer les performances concurrentielles et économiques de l’entreprise. Pour cela, il est nécessaire de s’appuyer sur un socle technologique à même de répondre aux besoins métiers actuels et futurs.
Ce socle technologique peut être divisé en sept grands domaines que sont :
- L’ingestion : adresse la collecte de la donnée que ce soit en temps réel ou non,
- Le stockage de la donnée,
- Le traitement de la donnée (ETL),
- La mise à disposition aux métiers de cette donnée à des fins analytiques ou de data science,
- L’orchestration : planifie et ordonnance les domaines précédents,
- La visualisation : pour rendre la donnée plus lisible,
- Le développement et déploiement pour travailler.
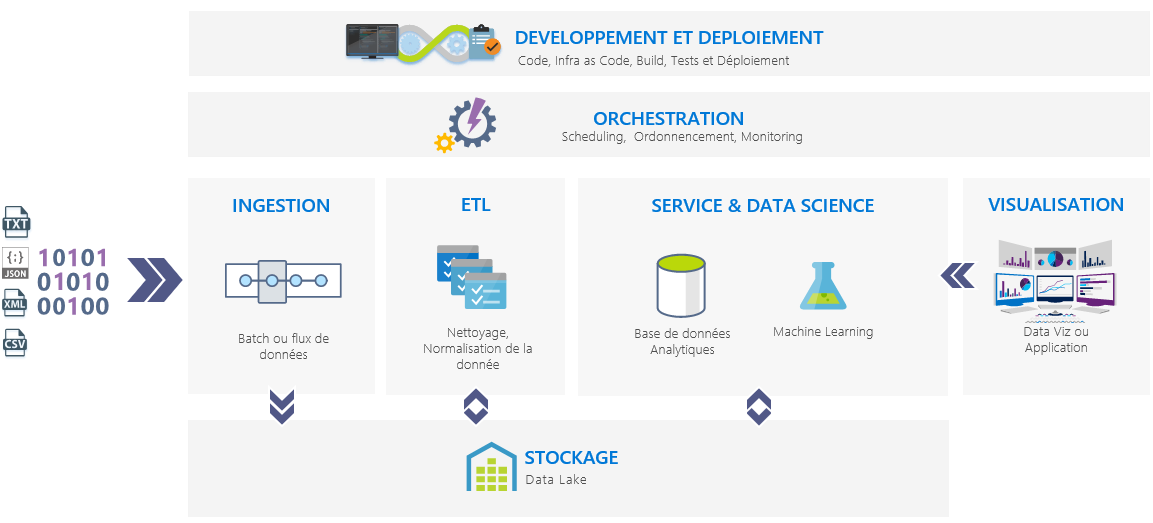
Quels outils pour répondre à ces sept domaines ? Tel est le sujet de cet article.
Les outils appropriés à votre stratégie de data
Le choix des outils est primordial pour faciliter l’efficacité des développements, l’industrialisation et la sécurité des projets data.
Le cloud étant notre domaine d’expertise premier chez Cellenza, Azure est le candidat idéal pour traiter nos projets de data. La scalabilité, l’usage à la demande, la rapidité de mise en œuvre sont indispensables pour adresser la volumétrie de données et l’agilité nécessaire à un projet.
L’ingestion et le stockage de la donnée
Selon la typologie de projet, nous pouvons distinguer deux flux de données : les données en temps réel (IoT, flux de commande / paiement, etc.), et les données à traiter en mode batch (traitements plutôt ordonnancés).
Les hubs de données tels que Azure Event Hub , Azure IoT Hub sont les candidats idéals pour ingérer les données en temps réel.
Pour le traitement batch, nous utiliserons plutôt Azure Data Factory afin d’effectuer le rapatriement des données vers notre zone de stockage.
Quel que soit le flux utilisé, la donnée doit être stockée pour être traitée par les processus ETL (pour Extract Transform & Load) classiques. Les technologies actuelles : Spark, Azure Synapse, etc. exploitent principalement le protocole HDFS. Azure Storage Account avec Data Lake Store Gen2, qui supportent HDFS, s’avère donc être le choix qui s’impose pour stocker notre donnée et la mettre à disposition des autres services de traitement de données.
ETL, Service et Data Science
Depuis quelques années, la technologie Spark prend son envol. Initialement utilisée pour transformer, normaliser et agréger la donnée (ETL), Apache Spark a évolué. La version 3.0 adossée à Delta Lake ajoute la performance requise pour nos applications BI ainsi que la transactionnalité et la sécurité nécessaire sur la donnée. Les récentes annonces de Databricks sur Delta Engine et Photon confirment ce nouvel état de fait.
Il existe aujourd’hui un outil qui contient tout cela, c’est Azure Databricks. C’est un service PaaS opéré par Microsoft et Databricks sur sa plateforme cloud Azure. Il offre des connecteurs avec d’autres services tels que le storage Azure ou la sécurité Azure Active Directory.
Databricks intègre l’ensemble des outils de data science (scikit-learn, pytorch, tensorflow, etc.) ainsi que MLFlow . Il est aussi notre outil de prédilection pour adresser la data science !
Finalement, avec un seul composant, nous adressons les domaines de l’ETL, du data warehouse et de la data science.
La visualisation de la donnée
Logiciel traditionnel de Data Visualisation, Power BI, continue à prendre tout son sens dans un projet de data analytics / BI.
Toutefois, dans des cas plus simples, un autre outil peut apporter de la valeur à votre donnée, c’est Redash. Récemment ajouté à Databricks, il s’adresse aux utilisateurs SQL, en leurs permettant de faire de la visualisation de données.
Actuellement moins bien intégré à l’environnement Microsoft, il sera prochainement disponible au sein de Databricks , ce qui fait de lui une nouvelle technologie sur laquelle nous pouvons nous appuyer.
Le développement et le déploiement de la donnée
Enfin, le dernier socle, et un des plus importants, est le socle de développement. Notre choix sur le sujet se porte tout naturellement sur Azure Devops et ses trois composants.
Azure Repos pour entreposer le code
Nous utiliserons Git dans Azure Repos pour entreposer l’ensemble du code qui compose notre écosystème applicatif.
Bien que les workspaces Databricks puissent s’intégrer avec un repo Git, ce n’est pas cette approche que nous allons vous présenter. L’intégration permet en effet d’historiser des modifications réalisées directement depuis un workspace, mais elle ne permet pas toute la finesse d’une vraie stratégie de branche, comme nous allons le découvrir plus loin.
Azure Pipelines, l’orchestrateur CI/CD
L’automatisation viendra du composant Pipelines d’Azure DevOps. Il s’agit d’un orchestrateur CI/CD. Nous aurions tout à fait pu utiliser un autre outil équivalent tel que jenkins, Gitlab ou GitHub actions, mais nous avons fait le choix de l’intégration à la plateforme Microsoft.
Visual Studio Code, l’IDE qu’on ne présente plus
VS Code est un éditeur open source très pratique et populaire. Il dispose de toutes les extensions nécessaires qui vous permettront de travailler efficacement. En particulier, grâce à l’extension Python et au module databricks-connect vous pourrez vous connecter à un cluster Databricks pour exécuter vos notebooks en cours d’écriture.
Les 8 outils à utiliser pour réussir votre stratégie data
Si l’on regarde nos sept domaines d’interventions sous le spectre des outils, nous obtenons la galaxie suivante :

Sept domaines, 8 outils dont Databricks qui adresse trois grands pans d’un projet data, et Data Factory qui en adresse deux.
On peut enfin le dire : la data se simplifie ! 😃
Lors de ce mois de la data, nos prochains articles exposeront plus en détails ces domaines et leurs applications avec les outils sélectionnés. Vous pouvez, dès à présent, accéder au deuxième article de notre série : « Gérer vos projets de Data avec Azure DevOps« .
✍️ Cet article a été rédigé par nos experts Data : Rémi Sorlin et Matthieu Klotz.






