

GitHub Copilot a été développé par GitHub et OpenAI, et les professionnels le qualifient d’« outil révolutionnaire pour les développeurs », car...
23 juillet 2013
SQL Server 2014 : La Force du In-Memory entre vos Mains

Microsoft accélère les choses en choisissant de sortir des versions de SQL Server plus fréquemment, ce qui n’est pas fait pour nous déplaire.
La grosse nouveauté pour 2014 est la fonctionnalité In Memory, projet EKATON de son nom de développement. Celle-ci nous permettra de pallier les limites de performance imposées par les disques physiques, en passant par la RAM dont le prix est de plus en plus abordable et dont la performance n’est plus à prouver.
Certains concurrents comme IBM (SolidDB) et Oracle (TimesTen), proposent des solutions presque similaires mais avec des installations différentes du produit de base.
SQL Server, quant à lui, intégrera nativement et de manière totalement transparente cette fonctionnalité en nous donnant la possibilité de créer des tables en stockage disque ou stockage mémoire, tout en sachant qu’une table en mémoire disque aura toujours une petite sœur sur le disque en cas de crash ou reboot machine où la mémoire se vide intégralement.
Nous ne serons pas tous des experts du In-memory à la sortie de SQL Server 2014, Microsoft a donc mis à notre disposition un outil de migration : ARM (Analysis, Migration and Reporting), qui analysera tout votre Datamart et proposera les tables à migrer dans la mémoire.
Pour rentrer dans les détails, je vais vous épargner les scripts de création de table, qui se trouve très facilement sur MSDN, mais plutôt présenter le fonctionnement global et l’interopérabilité entre des tables in-memory et des tables disques.

Comme le schéma l’indique, il y aura donc 2 plans d’exécutions possibles :
- L’ensemble des tables utilisées dans la procédure sont In-Memory : le compilateur spécifique In-Memory est utilisé et les requêtes seront totalement optimisées.
- Tout ou partie des tables sont stockées sur le disque : le compilateur In-Memory ne pourra pas être utilisé et la procédure passera par le compilateur classique.
Il faudra donc avoir l’ensemble de nos tables en mémoire, pour optimiser au maximum nos procédures.
L’autre changement majeur est dans la structure de stockage des données, les données ne sont pas stockées en page comme sur une table basée sur disque. Des lignes d’une même table en mémoire ne seront pas forcément stockées à côté au niveau de la mémoire, le seul moyen pour SQL Server de retrouver ses petits est d’utiliser l’index de table, c’est d’ailleurs la raison pour laquelle, il est obligatoire d’avoir une clef primaire unique pour chacune d’elle.
Chaque ligne contiendra un en-tête avec les informations nécessaires à cette localisation :
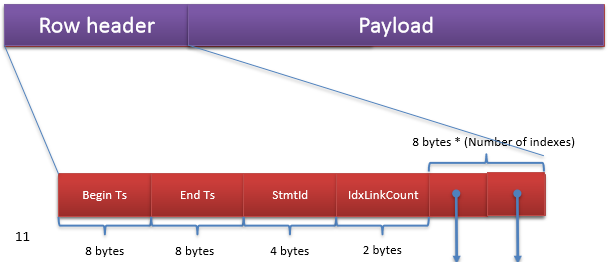
- Begin Ts (Timestamps): Id de la transaction qui a inséré la ligne
- End Ts (Timestamps): Id de la transaction qui a supprimé la ligne
- StmID : Id unique
- IdxLinkCount : Indique le nombre d’index qui référencent la ligne
Comme le montre le schéma, nous avons une date de début et une date de fin de validité de la ligne, c’est là que repose le fonctionnement du In-Memory de SQL Server pour gérer les lignes qui seront visibles ou non :
- Chaque transaction qui mettra à jour une ligne mettra à jour la colonne End Ts
- Les versions visibles seront donc les lignes n’ayant pas de date de fin (stockées sous le signe infini ∞)
Une méthode connue dans le domaine de la base de données, mais pourquoi réinventer la roue quand un système qui fonctionne existe ?
Le In-Memory intègre également le « Hash Index » et une isolation des transactions particulières, mais ce serait de longues explications pour peu de nouveautés, je vous conseille donc de vous référer au product guide pour plus de détails. Disponible ici.
Au final, le In-Memory de Microsoft est très bien intégré à l’environnement actuel et nos habitudes ne seront absolument pas changées, nous n‘aurons qu’à actualiser nos connaissances avec le fonctionnement des tables In-Memory.
Les performances ont été prouvées avec le projet de BWIN, le site de paris en ligne qui est passé de 10 000 transactions à la seconde, à plus de 250 000 avec les fonctionnalités In-Memory.
La liste des Avantages/Inconvénients/Contraintes (non exhaustive) :
- Contraintes :
- Clef primaire obligatoire
- Pas de DML Triggers
- Pas de clef étrangère ou contraintes CHECK
- Pas de colonne IDENTITY
- 8 indexes maximum, incluant la clef primaire
- Avantage :
- Temps d’acquisition des verrous réduit
- Temps d’écriture des logs réduit
- La majorité des fonctionnalités T-SQL sont supportées
- Inconvénient :
- Mirroring et Réplication not supported





