


Comment RAJA Group a construit une plateforme data unifiée avec Microsoft Fabric – et comment Cellenza a contribué à écrire...
21 juin 2022
Read this post in English
Utiliser Spark avec Kubernetes (K8s)

Article corédigé par Donatien Tessier, Amine Kaabachi et Jérôme Thin
Apache Spark est un framework open source écrit en Scala. Il est utilisé pour le traitement des données en masse.
Il est possible de faire tourner Spark sur YARN, en mode standalone, ou d’utiliser Databricks disponible sur les trois fournisseurs de Cloud (Azure, AWS, GCP). Depuis peu, on peut également faire fonctionner Spark avec Kubernetes (K8s). Dans un écosystème Microsoft, il est donc possible d’utiliser Azure Kubernetes Service (AKS).
Dans cet article de notre série dédiée à l’hybridation, vous allez découvrir comment s’inscrit K8s au sein de l’architecture Spark, le fonctionnement de Spark avec K8s, les bonnes pratiques et un exemple avec AKS.
Architecture globale de Spark
L’idée géniale des créateurs de Spark consiste à chercher à maximiser l’utilisation de la mémoire vive et à minimiser les lectures/écritures sur disque.
Il s’agit d’une architecture distribuée comprenant 3 composants principaux :
- Un driver, qui va découper le travail en différentes tâches ;
- Un cluster manager/orchestrateur, qui s’occupe d’affecter des tâches aux workers ;
- Un ou plusieurs workers (aussi appelés « executor »)

Il existe plusieurs cluster managers :
- Standalone : pour exécuter Spark sur son poste, par exemple
- Apache Mesos : de moins en moins utilisé
- Hadoop YARN : le plus courant
Depuis quelques années, il est possible d’utiliser Kubernetes comme cluster manager (en GA depuis mars 2021 avec Spark 3.1).
Ci-dessous un schéma de l’architecture Spark avec Kubernetes :

L’utilisateur soumet un job spark à l’API Kubernetes via kubectl. Kubernetes va ensuite provisionner des pods pour chacun des composants : un pod pour le driver et un pod par executor.
Fonctionnement de Spark sur Kubernetes
Spark-submit/spark operator
Aujourd’hui, il existe de multiples façons d’exécuter des jobs Spark sur Kubernetes. Vous pouvez soit utiliser spark-submit, soit l’opérateur Kubernetes ou même passer par un middleware comme Apache Livy.
Comparons les différentes options et essayons de voir laquelle est la meilleure :
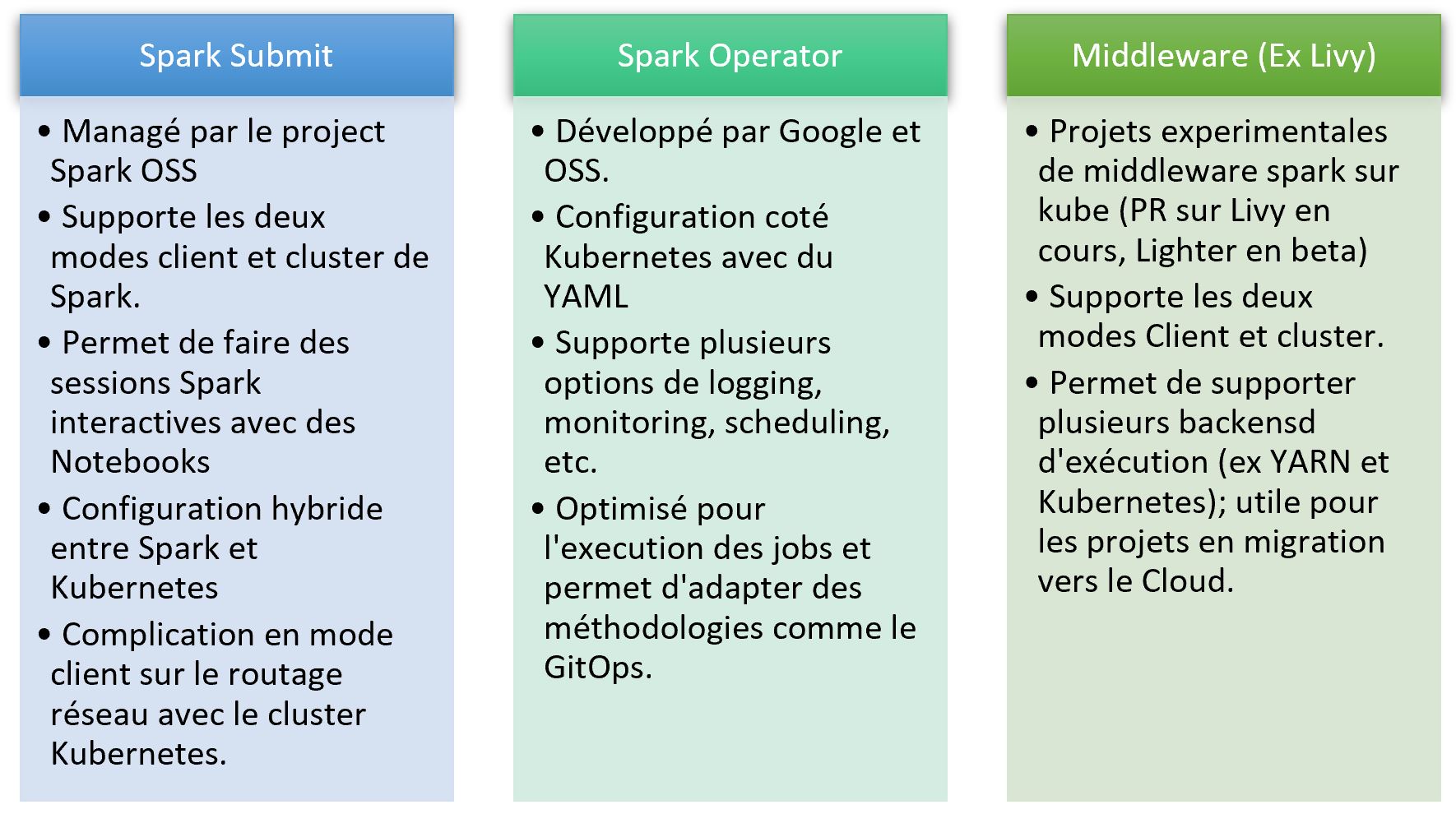
Si vous souhaitez utiliser Spark sur Kubernetes aujourd’hui, les possibilités sont les suivantes :
- Utiliser Spark Submit pour l’exploration et les projets d’un seul utilisateur ;
- Utiliser Spark Operator pour les déploiements de production et le déploiement de modèles avancés comme GitOps ;
- Essayer de stabiliser une solution middleware pour les charges de travail interactives multi-utilisateurs.
Les trois options sont possibles, mais la troisième n’est pas recommandée pour les cas d’utilisation en production, compte tenu de l’état actuel des projets OSS.
Shuffle
L’opération de « shuffle » consiste à l’échange de données entre les différents executors. En effet, ils commencent par réaliser des opérations unitairement puis, dans certains, peuvent avoir besoin de s’échanger des données.
Par exemple, pour faire la jointure entre une table Table1 et une table Table2 en utilisant un identifiant commun (id) puis trier le résultat, cela donnera le schéma suivant :

A la fin de l’étape 1, les executors 1 et 2 vont écrire le résultat de l’opération pour pouvoir l’échanger entre eux.
La vitesse d’Entrée/Sortie (E/S) est importante pour les charges de travail distribuées, car beaucoup dépendent de la permutation des fichiers entre les exécuteurs. Par défaut, Spark utilise le stockage local comme espace temporaire.
Lorsque nous voulons exécuter Spark sur Kubernetes, il est important de bien choisir le type de volume pour améliorer les performances d’E/S :
- EmptyDir : utiliser un dossier tmp sur la machine hôte du pod exécuteur.
- HostPath : utiliser un disque rapide monté sur la machine hôte (utile pour utiliser les disque SSD en backend pour les partitions de Shuffle)
- Tmpfs : utiliser la mémoire RAM comme espace de stockage (pas recommandé pour les usages multi-utilisateurs ou de productions).
Il est recommandé d’utiliser un volume avec des disques SSD pour les jobs de production.
Dynamic scaling
Kubernetes permet de gérer du dimensionnement dynamique. Par exemple, si le cluster manager (Kubernetes ici) détecte qu’il est nécessaire de provisionner un nouvel executor ou à l’inverse d’en décommissionner un, cela se matérialise par l’ajout d’un nouveau pod ou la suppression d’un pod existant.
Cependant, dans le cas d’une suppression, il est capital de ne pas supprimer un pod qui contient des informations nécessaires au shuffle. Cela pourrait altérer le fonctionnement du job Spark.
C’est pourquoi depuis Spark 3.0, seuls les executors (correspondant à des pods) qui ne contiennent pas de fichiers de shuffle actifs pourront être décommissionnés. Pour cela, il faut activer les deux options suivantes :
spark.dynamicAllocation.enabled=true spark.dynamicAllocation.shuffleTracking.enabled=true
Pour améliorer la vitesse d’allocation dynamique, il est possible de provisionner le cluster avec plusieurs pods en pending ayant une priorité faible.
Bien démarrer sur Kubernetes avec Spark
Configuration du cluster Kubernetes cible
Avant de créer un cluster Kubernetes pour Spark, il faut tout d’abord prévoir les workloads qui y seront hébergés :
- Les pods techniques pour le bon fonctionnement de Kubernetes (CoreDNS, kube-proxy, kube-api…)
- Le socle technique qui contiendra vos outils transverses pour le cluster : ingress controller, csi drivers, outils de monitoring…
- Le nombre d’applications Spark (faire une estimation de la consommation en termes de ressources).
En fonction de ces informations, il est préférable de « séparer » le cluster Kubernetes en au moins 2 node pools (groupe de nodes) :
- 1 node pool pour toute la partie technique (non Spark).
- A minima 1 node pool pour l’exécution des applications Spark.
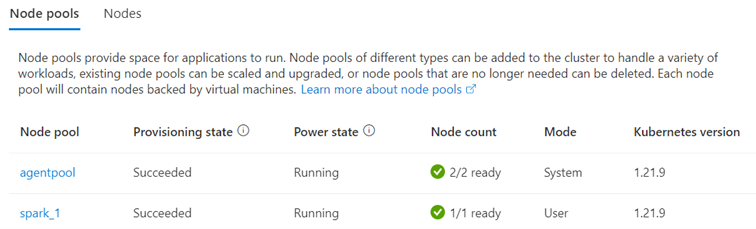
Exemple avec un cluster AKS sur Azure
Selon les besoins pour la partie Spark, on peut ajouter plus tard d’autres node pools avec d’autres types de VM (optimisés pour la mémoire par exemple).
A des fins de tests et pour réduire les coûts, on peut aussi utiliser des VM Spots. Ces dernièress sont beaucoup moins chers que les VMs à la demande ou réservées sur plusieurs années. Cependant, elles ne sont pas toujours disponibles et peuvent être arrêtées à n’importe quel moment.
La scalabilité des nodes au sein des node pools est également importante, surtout pour déployer de nouvelles applications Spark. L’autoscalling permet d’ajouter de nouvelles VMs si les autres nodes n’ont plus de ressources disponibles.
Déploiement d’une application Spark
Pour chaque déploiement d’une application Spark, il faut spécifier les ressources nécessaires pour les pods driver et executor.
Si on ne précise pas assez de ressources, on n’exploitera pas la capacité disponible. Au contraire, si on souhaite consommer plus de ressources que ce qui est disponible, les pods risquent de :
- Ne pas démarrer, car il n’y a pas de ressources disponibles (Etat = Pending)
- Si le pod a réussi à démarrer, il peut avoir un état instable. Par exemple, être arrêté en pleine exécution d’un job pour une consommation de mémoire excessive (Etat = OOMKilled).
En termes de CPU (Central Processing Units) et de mémoire, il ne faut pas oublier que chaque node Kubernetes contient a minima des pods techniques. De plus, derrière chaque node, cela peut être une machine physique ou une VM avec un OS.
Si le cluster Kubernetes a plusieurs node pools pour Spark, il est possible de choisir le type de node en amont, en se basant sur les affinités par exemple.
executor: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: type operator: In values: - spark_high_memory
Historique des exécutions des jobs Spark
Afin de suivre l’execution des jobs Spark, il est possible d’accéder à l’interface Spark UI. Cependant, une fois le job terminé, ce n’est plus possible.
Il existe plusieurs manières de garder les traces des exécutions :
- Spark History Server pour avoir l’historique et le détail des exécutions des applications Spark ;
- Utiliser des outils open source comme la stack ELK ou Prometheus pour visualiser les logs des pods Spark.
Monitoring
En termes de monitoring, il y a deux types de métriques à suivre :
- Kubernetes via le dashboard Kubernetes. Pour AKS, on peut se baser sur les métriques dans le portail Azure : consommation globale en termes de ressources, nombre de pods, nombre de nodes…
- Spark: cf. les métriques mises à disposition selon la version de Spark utilisée. On pourra avoir des informations sur le driver et les executors ainsi que la JVM (Java Virtual Machine).
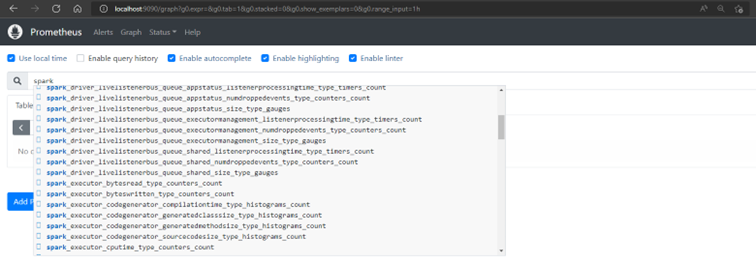
Exemple de métriques Spark disponibles dans Prometheus.
Exemple : Spark Operator K8s sur AKS (Azure)
Dans l’exemple qui va suivre, nous vous proposons d’installer Spark Operator pour tester l’exécution de l’application Spark Pi sur Kubernetes.
Contrairement au nom du repository Git, ce projet peut être installé sur n’importe quel cluster Kubernetes. Sur Azure, vous pouvez utiliser un cluster AKS par exemple.
Prérequis
Si vous avez une machine Windows, nous vous conseillons d’utiliser WSL2 pour faire tourner Ubuntu, par exemple (Installer WSL 2 | Microsoft Docs).
Vérifiez que vous avez les outils suivants installés en local :
- Azure CLI
- kubectl (az aks install-cli ou suivre la doc Kubernetes)
- Helm
Connexion au cluster AKS
Sur le portail Azure, se rendre sur la page du cluster AKS cible. Cliquer sur « Connect ».

Un panel s’affiche à droite avec les lignes de commandes à exécuter pour se connecter sur le cluster AKS.

Installation de Spark Operator sur AKS
Une fois connecté au cluster, vous allez devoir travailler avec deux namespaces :
- spark-operator : ce namespace sera créé via le Helm chart (chart de déploiement du spark operator)
- spark-everywhere : namespace dédié pour déployer nos applications Spark
Création du namespace pour nos applications Spark
Pour simplifier le déploiement des applications Spark, nous allons créer un namespace dédié.
kubectl create namespace spark-everywhere
Déploiement de Spark Operator
Via les commandes Helm, nous allons déployer le chart Helm de Spark Operator :
helm repo add spark-operator https://googlecloudplatform.github.io/spark-on-K8s-operator helm install spark-operator spark-operator/spark-operator --namespace spark-operator --create-namespace --set sparkJobNamespace=spark-everywhere
La commande ci-dessus réalise les opérations suivantes :
- Installation de Spark Operator dans le namespace spark-operator
- –set sparkJobNamespace : indique le nom du namespace où vous souhaitez faire tourner vos applications Spark.
Déploiement de l’application exemple Spark Pi
Tout d’abord, il faut récupérer le nom du service account qui sera utiliser pour faire tourner notre application Spark. Lors du déploiement du chart Helm, un service account a été créé dans le namespace spark-everywhere. On peut vérifier cela via la commande suivante :
kubectl get sa -n spark-everywhere
Voici ce à quoi le résultat devrait ressembler :

A noter : « spark-operator-spark » sera utilisé comme service account pour nos tests.
Il faut ensuite créer un manifeste de déploiement pour déployer l’application Spark Pi. On va le nommer sparkpi-deployment.yaml.
Exécuter la commande suivante pour déployer l’application :
kubectl apply -f sparkpi-deployment.yaml -n spark-everywhere
Cette commande devrait retourner ce texte :
sparkapplication.sparkoperator.k8s.io/spark-pi created
Vérification du fonctionnement de l’application Spark Pi
Pour vérifier que les pods tournent, exécuter plusieurs fois la commande à différents intervalles :
kubectl get pods -n spark-everywhere
Le résultat devrait ressembler à cela :

Ici, on voit que le driver a démarré en premier, suivi de l’executor.
Pour voir les logs de l’application :
kubectl logs <nom du pod executor> -n spark-everywhere -f
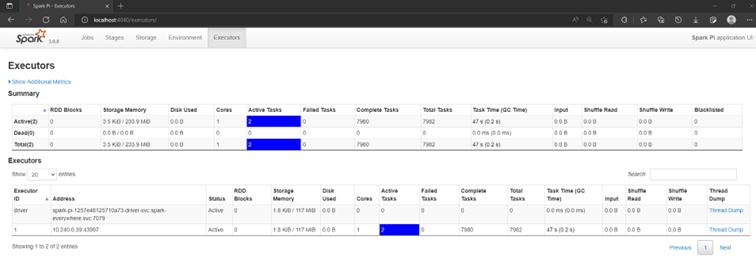
Accéder au portail Spark UI
kubectl port-forward svc/spark-pi-ui-svc 4040 -n spark-everywhere
Aperçu du portail Spark UI :

Avantages/Inconvénients de Spark avec K8s
Examinons à présent les avantages et inconvénients de cette solution hybride.
Avantages de Spark avec K8s :
- Une conteneurisation des applications Spark (même code source et dépendances) ;
- Une seule infrastructure pour l’ensemble de la stack technique ;
- Kubernetes est une solution cloud-agnostique;
- Optimisation des coûts et de la consommation des ressources
Inconvénients de Spark avec K8s :
- Une montée en compétence sur Kubernetes est nécessaire si vous ne l’utilisez pas ailleurs. C’est le cas côté infrastructure (observabilité, monitoring) et l’équipe data aura également besoin d’une montée en compétences ;
- Nécessite l’installation et la configuration des différents composants sur le cluster Kubernetes (cf. partie précédente) ainsi qu’une forte maintenance ;
- Des fonctionnalités Spark pas forcément disponibles.
Spark sur K8s : le bilan
Vous avez pu voir lors de cet article que Spark sur K8s n’est pas encore complètement mature. C’est néanmoins une possibilité qu’il est important à garder à l’esprit et à suivre au vu de l’évolution très rapide de la technologie.
Et pour en savoir plus sur l’hybridation, retrouvez nos autres articles de cette série :





