Developed by GitHub and OpenAI, professionals are calling GitHub Copilot a “revolutionary tool for developers,” since it combines Artificial Intelligence...
21 June 2022
Lire cet article en Français
Using Spark with Kubernetes (K8s)
Post co-written by Donatien Tessier, Amine Kaabachi and Jérôme Thin
Apache Spark is an open source framework written in Scala. It is used for bulk data processing.
Spark can be run on YARN, in stand-alone mode, or with Databricks, which is available on all three cloud services (Azure, Amazon Web Services (AWS), Google Cloud Platform (GCP)). Spark can now also be used with Kubernetes (K8s). This means that Azure Kubernetes Service (AKS) can now be deployed in a Microsoft ecosystem.
In this post from our series on hybridization, you will learn how K8s fits into the Spark architecture, how Spark works with K8s, best practices, and see an example using AKS.
Spark Architecture Overview
Spark’s creators had the smart idea of trying to maximize RAM use while minimizing disk reads and writes.
It is a distributed architecture with three main components:
- A driver, to divide the work into different tasks
- A cluster manager/orchestrator, for assigning tasks to the workers
- One or more workers (also called “executors”)
Check out our other posts in this series to learn more about hybridization:

There are multiple cluster managers:
- Stand-alone: to run Spark on your computer, for example
- Apache Mesos: less and less common
- Hadoop YARN: the most common
Kubernetes has been usable as a cluster manager for a few years (in general availability (GA) since March 2021 with Spark 3.1).
The diagram below shows the Spark architecture with Kubernetes:

The user uses kubectl to send a Spark job to the Kubernetes API. Kubernetes then provisions pods for each component, one for the driver and one for each executor.
How Spark Works on Kubernetes
Spark-Submit/Spark Operator
Today, there are many ways to run Spark jobs on Kubernetes. You can use spark-submit, the Kubernetes operator, or even go through middleware like Apache Livy.
Let’s look at the options and decide which is the most suitable:

If you want to use Spark with Kubernetes today, you have the following options:
- Use Spark-submit for single-user projects and exploration
- Use Spark Operator for production deployments and more advanced model deployments like GitOps
- Try to stabilize a middleware solution for interactive, multi-user workloads
All three options are possible, but given the current state of OSS projects, the third is not recommended for production use cases.
Shuffle
The “shuffle” operation involves the different executors exchanging data. They start by performing operations individually but, sometimes, they may need to exchange data.
For example, joining Table1 and Table2 using a common identifier (ID) and then sorting the result will produce the following schema:

At the end of step 1, executors 1 and 2 write the result of the operation so they can share it with each other.
Input/output (I/O) speed is important for distributed workloads since many depend on swapping files between executors. Spark uses local storage as its default temporary space.
When running Spark on Kubernetes, picking the right volume type to improve I/O performance is crucial:
- EmptyDir: use a tmp file on the executor pod host machine
- HostPath: use a fast disk mounted on the host machine (handy to use backend solid-state drives (SSDs) for Shuffle partitions)
- Tmpfs: use random-access memory (RAM) as storage space (not recommended for multi-user or production environments)
For production jobs, using a volume with SSDs is preferable.
Dynamic Scaling
Kubernetes can manage dynamic scaling. For example, if the cluster manager (Kubernetes in this case) detects that a new executor needs provisioning or an existing one needs decommissioning, this is done by adding a new pod or removing an existing pod.
However, when removing a pod, it is imperative not to delete one with information needed for shuffling. Doing so could change how the Spark job works.
This is why, since Spark 3.0, only executors (which correspond to pods) that do not have active shuffle files can be decommissioned. You need to enable the following two options for this:
spark.dynamicAllocation.enabled=true spark.dynamicAllocation.shuffleTracking.enabled=true
To speed up dynamic allocation, the cluster can be provisioned with multiple low-priority pending pods.
Getting Started with Kubernetes and Spark
Configuring the Target Kubernetes Cluster
Before creating a Kubernetes cluster for Spark, you need to plan the workloads that will be hosted on it:
- Technical pods that Kubernetes needs to function correctly (CoreDNS, kube-proxy, kube-api, etc.)
- The technical base that will contain your cross-cluster tools, such as the ingress controller, CSI drivers, and monitoring tools, etc.
- The number of Spark applications (estimate how many resources will be used)
Based on this information, the Kubernetes cluster should ideally be “split” into at least two node pools (groups of nodes):
- One node pool for the technical (non-Spark) part
- At least one node pool for running Spark applications
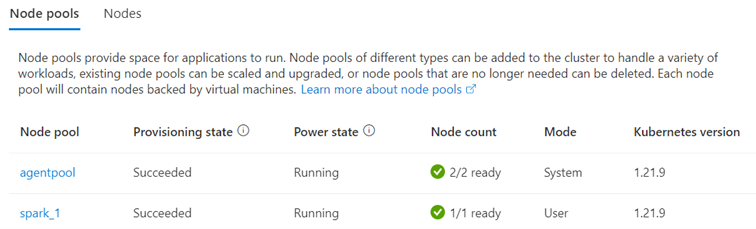
Example with an Azure Kubernetes Service (AKS) cluster
Depending on what Spark needs, we can add other node pools with different virtual machine (VM) types (optimized for memory, for example) later.
We can also use Spot VMs for testing and to reduce costs. These are much cheaper than on-demand VMs or VMs that are reserved for several years. However, they are not always available and can be shut down anytime.
The ability to scale nodes within node pools up or down is also important, especially when deploying new Spark applications. Autoscaling means new virtual machines (VMs) can be added if the other nodes run out of resources.
Deploying a Spark Application
When a Spark application is deployed, the resources needed by the driver pod and executor pods must be specified.
The available capacity will not be utilized if we do not specify enough resources. On the other hand, if we try to consume more resources than we have available, there is a risk of the pods:
- Not starting because there are no available resources (Status = Pending).
- If the pod does start successfully, it may be unstable. For example, stopping while running a job due to excessive memory consumption (Status = OOMKilled).
When considering central processing units (CPU) and memory, don’t forget that each Kubernetes node contains technical pods at a minimum. In addition, each node may have a physical machine or a VM with an OS behind it.
If the Kubernetes cluster has multiple node pools for Spark, you can choose the node type upstream, for example, based on affinity.
executor: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: type operator: In values: - spark_high_memory
Spark Job Execution History
The Spark UI interface can be used to track the execution of Spark jobs. Once the job is completed, this is no longer possible.
There are multiple ways to track executions:
- Spark History Server for the history and details of Spark application executions
- Use open source tools such as the Elasticsearch, Logstash, and Kibana stack (ELK stack) or Prometheus to view the Spark pod logs.
Monitoring
There are two types of metrics to track for monitoring:
- Kubernetes via the Kubernetes dashboard. For AKS, we can use the metrics in the Azure portal: total resource consumption, number of pods, number of nodes, and so on.
- Spark: see the available metrics depending on the Spark version we use. We can get information about the driver, the executors, and
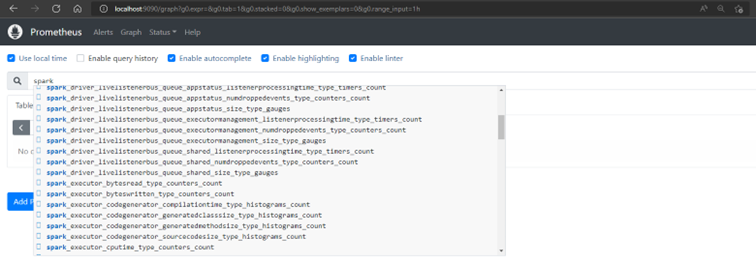
Example of Spark metrics available in Prometheus.
Example: Spark Operator K8s on AKS (Azure)
In the example below, we will show you how to install Spark Operator to test the execution of the Spark Pi application in Kubernetes.
This project can be installed on any Kubernetes cluster, despite the Git repository name. On Azure, for example, you can use an AKS cluster.
Requirements
If you have a Windows machine, we advise you to use WSL2 to run Ubuntu, for example (Install WSL 2 | Microsoft Docs).
Check that you have the following tools installed locally:
- Azure CLI
- kubectl (az aks install-cli or follow the Kubernetes doc)
- Helm
Connecting to the AKS Cluster
Navigate to the desired AKS cluster page on the Azure portal and click “Connect.”

A panel appears on the right showing the command lines you need to run to connect to the AKS cluster.
Installing Spark Operator on AKS
Once connected to the cluster, you will need to work with two namespaces:
- spark-operator: this namespace will be created using the Helm chart (Spark Operator deployment chart)
- spark-everywhere: dedicated namespace for deploying our Spark applications
Creating a Namespace for Our Spark Applications
We will create a dedicated namespace to make it easier to deploy Spark apps.
kubectl create namespace spark-everywhere
Deploying Spark Operator
We will deploy the Spark Operator Helm chart using Helm commands:
helm repo add spark-operator https://googlecloudplatform.github.io/spark-on-K8s-operator helm install spark-operator spark-operator/spark-operator --namespace spark-operator --create-namespace --set sparkJobNamespace=spark-everywhere
The above command performs the following operations:
- Installs Spark Operator in the spark-operator namespace
- –set sparkJobNamespace: indicates the name of the namespace where you want to run your Spark applications
Deploying the Spark Pi Demo Application
First, we need to know the name of the service account that will be used to run our Spark application. When the Helm chart was deployed, a service account was created in the spark-everywhere namespace. We can check this using the following command:
kubectl get sa -n spark-everywhere
This is what the result should look like:

Note: “spark-operator-spark” will be used as a service account for our tests.
Next, we must create a deployment manifest to deploy the Spark Pi application. Let’s call it sparkpi-deployment.yaml.
Run the following command to deploy the application:
kubectl apply -f sparkpi-deployment.yaml -n spark-everywhere
This command should return this text:
sparkapplication.sparkoperator.k8s.io/spark-pi created
Checking the Functionality of the Spark Pi Application
Run the command several times at different intervals to make sure the pods are running:
kubectl get pods -n spark-everywhere
The result should look like this:

Here, we can see that the driver started first, followed by the executor.
To view the application logs:
kubectl logs <nom du pod executor> -n spark-everywhere -f
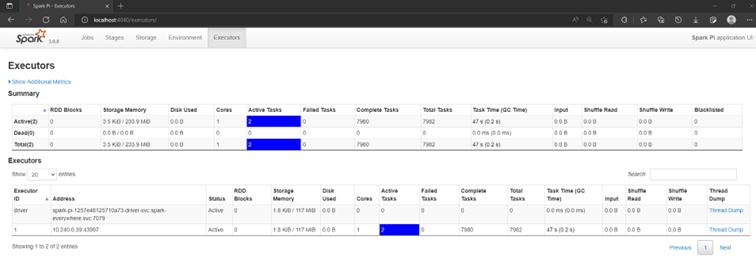
Accessing the Spark UI Portal
kubectl port-forward svc/spark-pi-ui-svc 4040 -n spark-everywhere
Spark UI portal overview:

Pros and Cons of Spark with K8s
Now, let’s talk about the pros and cons of this hybrid solution.
Pros of Spark with K8s:
- Containerization of Spark applications (same source code and dependencies)
- A single infrastructure for the entire technical stack
- Kubernetes is a cloud-agnostic solution
- Ability to optimize costs and resource consumption.
Cons of Spark with K8s:
- Skills development in Kubernetes will be needed if you do not use it elsewhere. This is true on the infrastructure side (observability, monitoring), and the data team will also need a skills upgrade.
- Requires the installation and configuration of various components in the Kubernetes cluster (see previous section) and a lot of maintenance.
- Not all Spark features are always available.
Spark on K8s: The Outcome
Spark on K8s is not yet fully mature, as you have seen in this post. It is, however, something to bear in mind and keep an eye on as technology continues to advance rapidly.
And if you want to read more about hybridization, read our posts below: