

La conférence .NET 2024 s’est tenue il y a quelques jours, présentant les dernières versions de .NET et de C#....
6 mai 2021
Read this post in English
NDepend : 3 usages pour simplifier la vie des développeurs

Si vous êtes développeur .Net, vous avez nécessairement, à un moment ou à un autre, entendu parler de NDepend. Si vous n’avez jamais eu l’occasion de tester cet outil, je vous propose aujourd’hui de vous présenter ce qui, à mes yeux, fait de NDepend un outil fantastique dans la vie de tous les jours sur vos projets.
Usage n°1 : A la découverte de la structure code
Cela nous est tous arrivé : vous démarrez sur un nouveau projet et vous découvrez des centaines de fichiers, dans des dizaines de projet. En gros, des milliers de lignes de code qui se ressemblent toutes les unes aux autres ! Alors que faites-vous ? Vous prenez un projet avec un nom familier – personnellement je cherche les projets en « .core » ou « .data » car ce sont souvent les projets qui sont les plus référencés et où j’ai le plus de chance de trouver des abstractions qui vont me permettre de comprendre ce qu’il se passe – et vous commencez à naviguer dans le code source. Pas facile de s’y retrouver, n’est-ce pas ? C’est un peu comme naviguer dans un labyrinthe sans carte, on y arrive mais ce n’est pas efficace.
C’est là que je vais utiliser NDepend pour m’en sortir. Tout au long de ce billet, j’utiliserai le code source d’Orchad pour les illustrations. Une fois la solution ouverte dans NDepend, voici ce que j’obtiens : une cartographie du code source :

Il y a un filtre qui, par défaut, permet de ne pas afficher les DLL (Dynamic Link Library) dites « third parties » (en gros toutes les DLL qui se sont pas générées par la solution) :

Une fois ce filtre désactivé, nous pouvons voir les DLL du framework .Net et naviguer comme si c’était notre code :

Chaque « boîte » comme « OrchardCore.Users » est une assembly. Les flèches nous indiquent donc les dépendances entre les projets.
NDepend ne s’est pas arrêté là : pour nous simplifier la compréhension du projet, NDepend a aussi créé des « clusters ». Dans ces clusters (4 sur le schéma), nous allons retrouver des projets avec à peu près les mêmes dépendances. Ce schéma est entièrement interactif, je peux sélectionner un projet et voir ses dépendances.
Commençons par le projet Orchad.Core :

Nous voyons, en vert, tous les projets qui dépendent de ce projet directement. C’est plutôt logique : cela a l’air d’un projet central. Je découvre, en bleu qu’il dépend de 2 autres projets :

Allons sur « OrchardCore. Abstractions » :

Tout est logique, ce projet ne dépend de rien. En revanche, il est utilisé quasiment partout. Je sais maintenant que si je dois travailler sur ce projet, j’ai intérêt à bien comprendre ce qu’il se passe à l’intérieur. Mais maintenant que je suis sur ce projet, où dois-je aller pour continuer à investiguer ? Je vais aller utiliser une autre vue, une vue matricielle qui va me permettre de mieux comprendre les liens entre les projets :

Chaque case représente le nombre de fois où le projet est utilisé par un autre projet. Cela vous permet de mieux comprendre les liens de dépendances. Plus le chiffre est haut, plus les projets sont liés.
Pour cet exemple, j’ai utilisé un découpage par projet, mais j’aurais aussi pu utiliser un découpage par namespace, qui peut être plus utile une fois que l’on a compris le fonctionnement du source.
Usage n°2 : Analyse du code
Maintenant que l’on sait naviguer, il est temps de rentrer un peu dans le code et de l’analyser. NDepend nous fournit de la mesure sur le code directement depuis le dashboard de la solution :

Sur la gauche, nous retrouvons les mesures classiques : taille du code, nombre de fichiers, de namespace… Cela donne déjà une idée de l’organisation du code.
Plus à droite, s’affichent des mesures qui peuvent vous être familières si vous utilisez SonarQube :
- Des règles avec des anomalies ;
- Une note de dette technique.
Comme tout autre outil d’analyse de code, NDepend permet également de suivre l’évolution de ces indicateurs dans le temps, via des snapshots. Ces snapshots d’analyse peuvent, par exemple, être effectués au moment du build, ce qui permet de vérifier des « Quality gates » par exemple et de générer des statistiques pour déterminer une tendance générale. NDepend est aussi capable, dans ses outils d’analyse, d’incorporer les résultats de couverture de code pour compléter ces mesures.
Nous reviendrons sur la dette après, regardons d’abord ces règles :
Allons regarder la règle « Avoid types too big ». Elle est assez parlante, et pourtant souvent source de polémique: il faut bien se donner un seuil pour dire qu’une classe est trop grosse, mais lequel ?

Toutes les règles de bases de NDepend viennent avec une explication, mais elles sont entièrement paramétrables. En effet, il suffit d’aller sur « View Source Code » et voir comment est construite une règle :
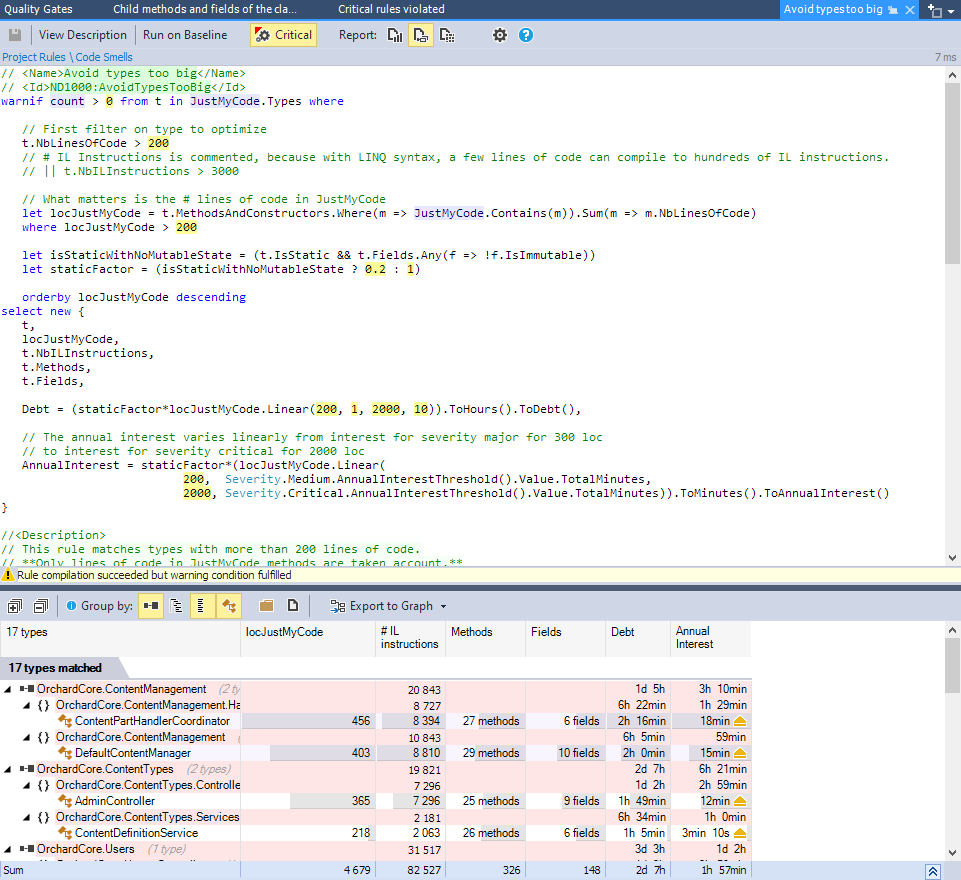
Si vous êtes un développeur C#, cela va vous être très familier. Une règle est une sorte de requête Linq sur des données. Et ces données sont en fait issues de la structure de votre application. Comme une règle, c’est avant tout du code, vous pouvez la copier, la modifier pour en faire une autre.
Voici le genre de règles que je rajoute souvent dans mes projets :
- Quand j’utilise de l’injection de dépendance, j’interdis l’utilisation de la classe concrète, sauf quand je construis mon conteneur d’injection.
- J’ai déjà des problèmes de dates sur mes projets où par inadvertance », les développeurs utilisaient la date locale. Avec une règle, on peut facilement vérifier que la méthode « DateTime::Now() » n’est jamais appelée.
- J’ai des objets avec des données sensibles (date de naissance…) : je peux, en une règle, détecter leur utilisation dans toute la base de code.
NDepend est base de données de la structure de votre application.
Usage n°3 : Mesurer la qualité (de mon code ) et définir mon plan d’action
L’ajout de fonctionnalités et la correction des bugs constituent le nerf de la guerre. Et plus le code d’un logiciel est « propre », plus c’est simple. Sans rentrer dans les détails sur la maintenabilité d’un code source, c’est souvent lié, en autres, à :
- sa couverture de tests;
- sa capacité à être modifié localement sans impact sur la totalité du code source ;
- l’organisation du code (grosses méthodes, interactions entre les classes).
Avec NDepend, ce genre d’information se mesure. A partir des règles, nous pouvons donner des temps de correction théoriques pour fixer les anomalies. Et à partir de ces temps, via des snapshots réguliers, il est possible de déterminer si la qualité globale de notre logiciel s’améliore ou si elle se dégrade.
Dans NDepend, on appelle ce temps de correction notre « dette ». Via le dashboard, on a la possibilité d’agréger les requêtes qui nous remontent la dette :
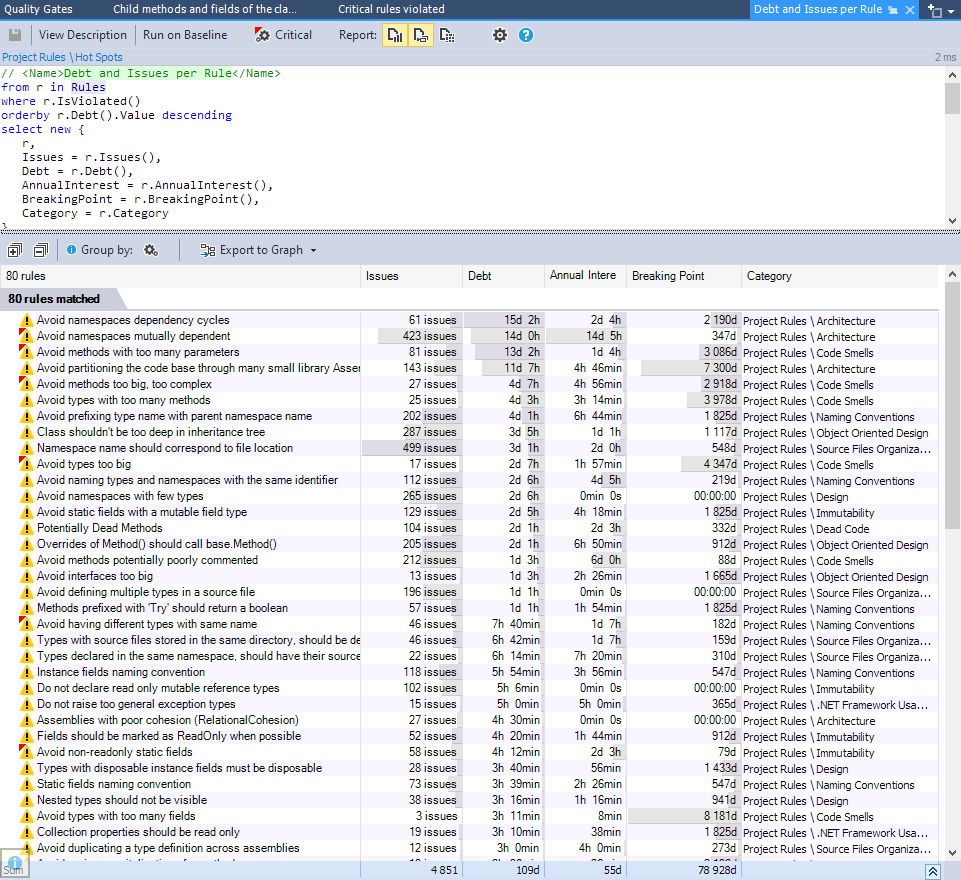
Attention : ce sont les règles de base de NDepend. Elles sont entièrement modifiables et adaptables à vos logiciels. Pour chaque élément, on trouve 4 données :
- Le nombre de fois où l’anomalie apparait;
- La dette cumulée ;
- Les intérêts annuels ;
- Le breaking point.
Si les deux premiers points sont assez clairs, les deux derniers nécessitent une explication. Car ces éléments vont nous permettre de prioriser nos campagnes d’amélioration de code.
Commençons par les intérêts annuels. Comme dans toute dette, un défaut de qualité se paye. Pour une règle, les intérêts annuels représentent le coût en développement si les anomalies ne sont pas corrigées. Par exemple, sur « Instance fields naming convention », les anomalies rendent la lecture du code plus complexe et donc plus longue.
Pour le breaking point, c’est assez simple, une fois que l’on a compris les intérêts. Je reprends la même règle pour l’explication. Nous avons 5h54 de travail estimé pour la réparation des erreurs, et 3h56 estimées de perte de temps par an. Le breaking point nous dit qu’au bout de 547 jours, on aura perdu autant de temps à cause de la dette que si on avait fixé les erreurs, c’est à dire 5h54. On commence donc à vraiment perdre du temps si l’on décide de fixer les erreurs après ce breaking point (puisqu’il faut quand même dépenser la dette pour fixer).
Ce qui veut dire qu’à sévérité équivalente, on a intérêt à fixer les anomalies avec un breaking point court. Par exemple, je ne suis pas près de fixer la règle « Collection properties should be read only » car le breaking point est dans plus de 8000 jours.
Pour résumer les critères pour définir l’ordre des corrections :
- Les anomalies les plus critiques d’abord,
- Celles avec un breaking point petit et un gros intérêt.
N’oubliez pas : vous pouvez ensuite utiliser la fonction d’historique pour superviser les corrections et puis un peu plus tard maintenir la dette dans des valeurs raisonnables.
Un dernier outil pour vous aider : NDepend intègre aussi un indicateur Sqale qui va permettre de donner une note « générale » et le coût pour améliorer sa note. Ce sont généralement des indicateurs dont les manageurs sont friands 😉





