

Actuellement, la plupart des applications se reposent fortement sur les opérations Input/Ouput (I/O). Ce type d’opération inclut le téléchargement du...
13 avril 2022
Méthode SOLIDITE : les 8 règles pour maitriser le périmètre projet

Appliquée à la globalité d’un projet, la méthode SOLIDITE permet de sortir du cercle vicieux des inter-dépendances, phénomène trop souvent constaté dans les Systèmes d’Information (SI). Respecter les 8 règles de la méthode SOLIDITE permet de libérer n’importe quel projet des dépendances fortes. Finalement, on obtient un projet libéré des délais, des régressions et des dépassements de budget systémiques.

Règle n°1 : Pour chaque objet du SI, définir un unique projet qui en est l’unique responsable
S – Single Responsibility
La règle définie par la méthode SOLID cherche à ce que les objets n’aient qu’un seul but, une seule raison d’être. Un projet peut cependant en avoir plusieurs et ces responsabilités vont également varier avec le temps. Adaptons cette règle en gardant cette notion de responsabilité mais au niveau ressource ou objet SI.
Chaque ressource dans le SI (base ou table de données, espace de stockage, jeux d’APIs…) doit avoir un unique Projet responsable, et ce même si différents projets sont développés par la même équipe.
Ce n’est pas l’équipe qui est responsable, c’est le projet ! Le projet peut en effet, à terme, être confié à une autre équipe ou être externalisé.
Si le projet décide de modifier une ressource dont il est le responsable, le projet doit pouvoir prendre la décision seul. Les impacts sur les autres projets seront masqués par les abstractions (cf. règles suivantes).
Cas d’usage de responsabilité unique de projet
Une base de données est utilisée à la fois par une application de gestion de commandes, par l’application de facturation et par un rapport du service commercial.
Chaque mise à jour, sur cette base de données, entrainera la recherche d’impact et éventuellement la modification des trois applications connexes. Ces dernières sont fortement dépendantes de la base.
Si plusieurs projets se partagent la même base de données, il faut découper la responsabilité du sous modèle. Chaque table ne peut avoir qu’un seul projet responsable.

Objectif : Pas de superposition de périmètre.
Cas particulier des ressources mutualisées
Dans l’exemple précédent, différentes tables sont hébergées dans une même base de données. Cette base de données et le serveur qui l’héberge sont de la responsabilité d’un projet transverse. Le projet responsable de ces serveurs de données, souvent nommé infrastructure ou Data, offre un service aux autres projets : un service d’hébergement. Il en va de même pour le réseau, les serveurs virtualisés, etc.
Néanmoins, si l’infrastructure décide de remplacer un serveur par un autre, tout en respectant le contrat avec les projets (nom de machine, droits, protocoles réseau…), il ne doit pas y avoir d’impact autre qu’un arrêt temporaire de service.
Règle n° 2 : Ne pas redévelopper, ne pas écraser. Etendre.
O – Open Closed Principle
Tout élément d’un projet doit être fermé, immuable, mais ouvert via des extensions.
Lors d’une évolution, si un objet n’est pas directement concerné, il ne doit pas être modifié. Le but est d’éviter de casser ce qui fonctionne.
Cas d’usage
Une table d’une base de données « client » a pour responsable le projet Gestion Client. La comptabilité appelle une api spécifique de gestion client pour des modifications. La comptabilité souhaite ajouter des informations sur le mode de règlement préféré pour la facturation.
Le projet Gestion client créera alors spécifiquement pour la comptabilité, une nouvelle table étendant la table client, de nouvelles méthodes de gestion de ces nouvelles données. Seul le projet comptabilité doit accéder à ces nouvelles informations, il faut éviter de changer les autres interfaces de la table client.

Règle n°3 : Interdire tout accès direct aux ressources et aux méthodes internes de chaque projet mais proposer des abstractions
L – Liskov substitution (Principe de Substitution)
Un Projet quel qu’il soit ne doit exposer que des interfaces ou abstractions. Ainsi, si l’on remplace totalement tous les objets du projet (bases, applications, sites web, jeux d’APIs…) par d’autres objets respectant les mêmes interfaces et abstractions, les applications connexes ne seront pas impactées.
Ces interfaces pourront être des APIs, des systèmes de Queuing, des vues, des Data Lakes, etc.
Même si l’interface ne fait office que de passe-plat entre les applications clientes et les méthodes internes, il DOIT y avoir une interface.

Règle n°4 : Créer une interface spécifique par client
I – Interface Segregation Principle
Il est préférable d’opter pour des interfaces spécifiques pour chaque élément client plutôt qu’une seule interface générale pour tous les clients. Les besoins d’un projet connexe sont susceptibles d’évoluer. Avoir une interface pour chacun de ces clients donne de la souplesse pour adapter chacune d’entre elles.
Avoir une seule interface, c’est risquer des régressions, lors des évolutions, pour tous les projets abonnés à cette même interface.
⚠️ Point d’attention
Avoir des interfaces différentes par client ne veut pas dire que l’on écrira du code spécifique pour chacun. Des interfaces différentes pour la comptabilité ou le commerce peuvent utiliser des méthodes internes génériques et adapter le résultat en ajoutant ou supprimant des valeurs.

Règle n°5 : Ne dépendre que d’interfaces et d’abstractions.
D – Dependency Inversion principle
Cette règle est le corollaire du principe de Substitution (règle n°3).
En tant qu’application cliente (ou connexe), un projet ne doit s’appuyer que sur des interfaces ou des abstractions.
Une dépendance forte, c’est un interblocage. Si un projet exécute des requêtes directement sur les tables de données d’un autre projet, c’est une dépendance forte. Utiliser plutôt des vues, des Data Lakes, des APIs…
Si un projet a du code en commun (classes, méthodes…) avec un autre projet, c’est une dépendance forte. Préférer des librairies provenant d’un gestionnaire de package ou un api management plutôt qu’un fichier commun ou du code dupliqué.
Règle n° 6 : Automatiser l’intégration, le déploiement et la création de l’infrastructure
I – Intégration continue / Déploiements Continus et IaC (CI/CD/IaC)
Il est recommandé d’automatiser systématiquement et le plus tôt possible l’intégration (CI) et le déploiement (CD) de tous les éléments du projet.
Les pratiques DevOps sont devenues la norme (pour en savoir plus sur le sujet, nous vous invitons à consulter les articles des experts Cellenza sur le DevOps)
L’intégration et le déploiement continus doivent être mis en place dans tout Système d’Information. Il n’y a aucune valeur ajoutée à effectuer des tâches manuelles fréquentes. Par ailleurs, « l’erreur est humaine » : une étape oubliée ou une faute de frappe sont vite arrivées.
Gardons bien en tête que : Automatisé = Sécurité.
Un autre élément à envisager sérieusement pour le déploiement continu est l’Infrastructure as Code (IaC). L’IaC permet de définir du code pour créer ou mettre à jour toute l’infrastructure. Il n’est plus nécessaire de créer manuellement les serveurs, les configurations réseau, les réplications, sauvegardes ou les permissions. Tout est automatisé via du scripting ou des outils spécifiques (cli, Terraform, ARM Templates, etc.).
L’IaC est souvent considérée comme trop coûteuse. Cela est dû à l’impression que l’infrastructure une fois mise en place ne changera que très peu et ne nécessitera pas d’automatiser sa création ou sa modification. Mais il n’en est rien.
Les arguments en faveur de l’IaC
- L’infrastructure est créée et modifiée par le processus de déploiement. La bonne santé du SI ne dépend pas de quelques hommes / femmes clés qui retiennent les connaissances (par manque de temps, par ignorance de l’impact, parfois par volonté de nuire…). Avec l’IaC, la connaissance est tracée et sauvegardée;
- L’IaC permet de recréer ex nihilo une infrastructure stable et comparable à la production. Elle est donc déployable pour tous les environnements (développements / tests / UAT / etc.) ;
- Les différents environnements étant créés par le même processus, les tests sont facilités. Fini les écarts venant de configurations ou d’installations différentes.
- Un déploiement IaC permet aussi de recréer une production après une attaque, une défaillance ou une erreur humaine. C’est l’outil parfait pour les plans de reprise d’activité.
Règle n°7 : Automatiser les tests le plus tôt possible pour fiabiliser et pérenniser.
T – Tests Automatisés
Automatisez autant que possible les tests : tests unitaires, tests d’intégration, tests d’UI et tests de montée en charge.
Ils ont plus de 25 ans, cependant les tests automatisés font souvent l’objet d’idées reçues : Combien de fois a-t-on déjà entendu « Les tests automatiques, c’est trop cher, on verra plus tard » ? Ou bien le fameux « Tester c’est douter ».
Cependant dans un monde où les livraisons agiles se font toutes les 2 semaines, peut-on imaginer tester manuellement la totalité du code à chaque livraison ?
Les tests unitaires permettent aux développeurs de détecter pendant la phase de développement une régression sur le code.
Les tests d’intégration et les tests d’UI automatisés permettent de détecter avant la livraison des écarts dans le rendu ou les calculs, qu’il s’agisse de clients lourds, de rapports ou de sites web.
Enfin, les tests de montée en charge doivent aussi être automatisés. De nombreux outils permettent de tester, à peu de frais, de grands volumes d’utilisateurs simulés sur des périodes courtes. Ces tests valident que les dernières évolutions n’ont pas d’impacts sur les règles d’auto-scaling, sur la fiabilité ou qu’elles n’ont pas introduit de fuite mémoire ou de boucles sans fin. Tester automatiquement est plus fiable que d’attendre et espérer que tout va tenir lors du prochain « burst ».
Automatiser, c’est aussi supprimer le facteur humain couteux et faillible. Néanmoins, l’automatisation ne doit pas remplacer totalement l’humain. L’œil, l’instinct ou la chance permettent aussi de détecter des bugs. Ces détections manuelles doivent ensuite être automatisées pour participer à une amélioration constante du système.
Un nouveau dicton pourrait ainsi remplacer l’ancien : « Livrer sans tests automatisés, c’est se planter ».
Règle n°8 : Évaluer et examiner pour pouvoir décider
E – Évaluer, Examiner Monitorer
Connaitre son projet, ce n’est pas seulement une œuvre de l’esprit. Il faut baser les décisions sur des éléments factuels.
Maintenir une procédure stockée, une version de package ou une API qui n’est plus utilisée, c’est du temps perdu. Mais pour évaluer, il faut des indicateurs.
Si un projet utilise des services Cloud (API Management, App services, SQL Server, Cosmos DB), ces indicateurs existent souvent déjà par défaut et sont facilement exploitables : nombre de requêtes, taux d’erreur, CPU, mémoire…
Outillage de l’évaluation : l’exemple Application Insights
Si un projet est ancien, et même si le projet n’est pas dans le Cloud, la fonctionnalité d’Azure Monitor, Application Insights, est un service idéal. D’autres outils similaires existent également. Application Insights ajoute de nombreuses informations à des clients lourds, des sites web ou des APIs en quelques clics et en quelques lignes de configuration seulement.
Son utilisation est très simple : créer une ressource App insights sur Azure. Rajouter la librairie idoine à la solution. Définir la chaine de connexion. Et c’est parti.
Application Insights ajoute automatiquement, lors de la compilation ou l’exécution, des métriques et des logs. Les dépendances sont immédiatement détectées (serveur de base de données, service d’envoi de mail, storage…). Le nombre d’appels vers une API, le pourcentage de requêtes en erreur, le temps de latence sont affichés visuellement et sont également accessibles avec des requêtes pour des tableaux de bords.
De nombreuse informations précieuses, au prix de seulement quelques minutes d’effort !

Source : documentation Microsoft
Les possibilités sont illimitées. App Insights permet également de mieux interpréter l’origine d’un bug avec le profileur, mais aussi de déterminer la tendance du nombre d’erreurs pour une période.
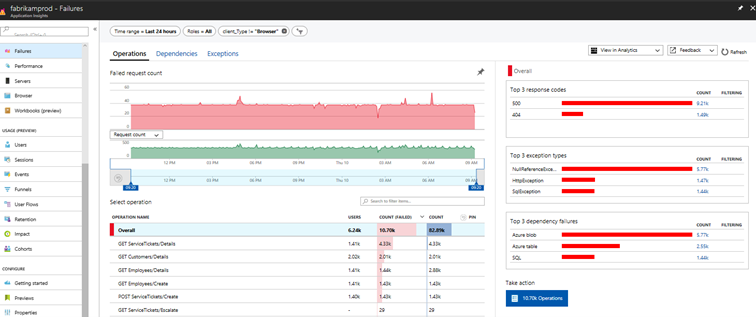
Source : documentation Microsoft
Ajouter des Métriques spécifiques
Au-delà des données remontées automatiquement, et quel que soit l’outil de remontée des données de monitoring, il est primordial de créer et stocker des métriques métier.
Par exemple, lors de la création d’une commande, un log peut être créé pour indiquer la création en succès. Mais il est avantageux à ce moment de créer également plusieurs métriques.
Les métriques diffèrent des logs, qui ne sont que du texte qu’il faut interpréter. Les métriques constituent un ensemble de clés / valeurs. Elles peuvent être techniques (temps de traitement, quantité de mémoire utilisée…) mais aussi être fonctionnelles. Pour une commande, on pourra avoir la quantité / le code produit commandé, le type de livraison, le pays, le navigateur utilisé, la version de l’application cliente à l’origine de la requête, etc.
Pourquoi utiliser des métriques ?
- Contrairement au logs, il ne faut pas interpréter du texte. Les métriques sont des valeurs utilisables immédiatement, cumulables via des requêtes simples.
- Cela décharge le serveur de base de données. Des requêtes à destination de tableaux de bord peuvent être fréquentes et consommatrices mais ne sont pas essentielles. Il est préférable déporter vers un système de recueil de métriques.
- Les métriques ne contenant pas de données sensibles (personnelles), des équipes commerces ou de développement peuvent effectuer sans risque des recherches ou effectuer du débogage.
- Certaines données de la requête initiale ne sont pas sauvegardées en base. Elles sont pourtant utiles ponctuellement : pour la résolution d’incidents, pour connaitre la version des APIs utilisées, l’heure des appels, la durée d’un traitement spécifique…
Pour aller plus loin sur la méthode SOLIDITE et faire une comparaison entre un projet géré avec et sans cette méthode, nous vous invitons à lire la suite de cet article.





