

Longtemps, le Run et le Build d’un projet IT ont été considérés comme totalement indépendants l’un de l’autre : il y...
15 mars 2022
Read this post in English
Run d’un projet IA : garder sous contrôle le cycle de vie d’un modèle ML

Si la dépendance entre le Build et le Run ne fait plus discussion sur les projets IT « classiques », elle est encore plus forte sur les projets de Machine Learning (ML). Sur ce type de projets, la surveillance constante du Run est indispensable pour maintenir la performance du Build et garantir la livraison d’un modèle performant à chaque itération.
- Le maintien de la qualité du modèle à chaque itération
Les acteurs de projets ML (développeurs, décideurs, data engineers, data scientists…) connaissent les heurts de ce type de projet notamment en termes de maintenance : 1 projet ML sur 10 seulement arriverait en production (VentureBeat Transform, 2019) et la maintenance prendrait plus de 50% du temps des développeurs d’une équipe ML (MLOps Virtual Event, 2020).
Depuis une dizaine d’années, ces acteurs ont donc développé des outils permettant de faciliter en particulier le déploiement et la maintenance des projets ML. Le « MLOps » reprend la même méthodologie que le DevOps, à une différence près et de taille : il s’applique au Machine Learning qui ne comprend pas seulement du code mais aussi des données d’entrainement (beaucoup de données), chacun ayant ses problématiques, son cycle de vie. L’un des défis est justement de pouvoir concilier MLOps et DevOps sans discontinuité.
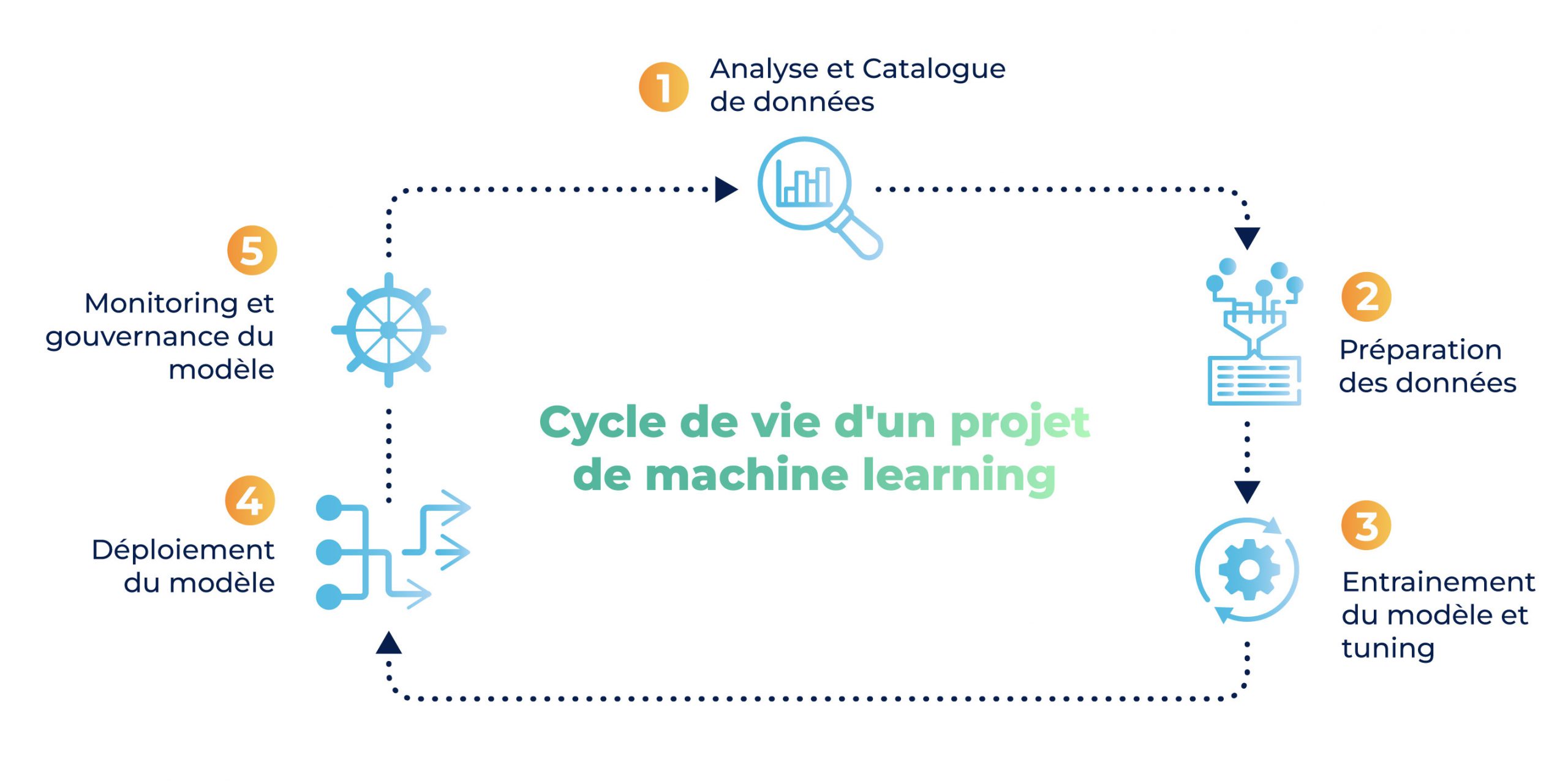
- Concevoir une IA Responsable dès sa conception
A cela s’ajoute la prise de conscience, depuis quelques années, de la nécessité de responsabiliser l’ensemble des acteurs prenant part à la création d’un système ML et de penser à leur impact social, économique et/ou écologique. En 2018, Gartner prévoyait que jusqu’en 2022, 85% des projets d’Intelligence Artificielle (IA) produiraient des résultats erronés en raison de biais dans les données, les algorithmes ou des équipes chargées de les gérer.
Les États se sont aussi approprié le sujet de la régulation du développement de ces systèmes d’IA.
Côté organismes publics : l’UNESCO a publié ses recommandations sur l’éthique de l’IA en novembre 2021. En décembre 2020, le Conseil de l’Europe a rendu un rapport « Vers une réglementation des systèmes d’IA » : l’OCDE a défini ses principes sur l’IA adoptés en mai 2019. En avril 2021, la Commission européenne a proposé un projet de règlement pour une IA digne de confiance…
Côté privé : de nombreuses initiatives de régulation ont été prises par les entreprises, parfois en s’associant à des universités ou autres organisations : organismes de normalisation (ISO/CEI, NIST (Kicking off NIST AI Risk Management Framework, oct. 2021), IEEE (Ethics In Action – in Autonomous and Intelligent Systems) ; création du partenariat mondial pour l’IA (Global Partnership on AI (“GPAI”))…
Un autre défi est donc aujourd’hui de bénéficier de la puissance d’un système ML (automatisation et optimisation de tâches chronophages et peu valorisantes pour recentrer le professionnel sur son cœur de métier et sa relation avec son patient ou son client, amélioration des performances sur certaines tâches, réduction des erreurs sur des tâches stratégiques…), tout en s’assurant que le modèle conçu ne produise pas de risques pour la société, l’économie ou l’environnement (confidentialité et protection des données utilisées pour l’entrainement du modèle, risques de biais algorithmique induit par un jeux de données d’entrainement déséquilibré…).
AI Gouvernance, Machine Learning Operations (MLOps), Responsible AI… Les exigences se sont précisées ces dernières années quant au développement de systèmes d’IA et des principes ont émergé pour garantir la conception d’Intelligences Artificielles responsables :
- Equité et non-discrimination : il s’agit de développer des outils et procédures qui permettent de comprendre, documenter et surveiller les biais de développement et de production. Les systèmes d’IA doivent traiter toutes les personnes avec équité.
- Augmentation humaine: il s’agit de promouvoir des valeurs humaines, de garantir une surveillance humaine qui permettrait notamment aux experts du domaine d’examiner la pertinence du modèle à la fin d’un cycle, mais également de pouvoir comprendre l’impact d’une décision incorrecte, d’autant plus si le système ML automatisé pourrait avoir un impact significatif sur la vie humaine (santé, énergie, finance, banque, justice, transport…).
- Confidentialité et gouvernance des données : la confiance par la confidentialité passe par le développement d’outils et procédures de traitement et de protection des données adaptés au type de données (privées, sensibles…). La sensibilisation des risques liés aux données se concrétise par le développement des procédures et de l’infrastructure nécessaires pour garantir la sécurité des données et des modèles.
- Responsabilité : tous les intervenants sur le projet ont une part de responsabilité sur le système d’IA développé.
- Transparence et explicabilité : il est nécessaire de développer des outils et processus permettant d’améliorer continuellement la transparence et l’explicabilité d’un système ML. Les informations pertinentes sur les modèles doivent être identifiées et documentées.
- Sécurité et fiabilité : le cycle de vie d’un système d’IA doit être reproductible et robuste avec un système de mesure de la précision et de la performance du modèle.
- But éthique et bénéfice social : la conception de systèmes d’IA doit être centrée sur l’humain et une étude d’impact du projet doit être menée en amont afin d’identifier clairement les risques et impacts potentiels sur la société, l’économie et l’écologie (principe de précaution).
Tout l’enjeu est donc de penser ces défis et d’appliquer ces principes dès la genèse du projet, d’implémenter des garde-fous tout au long de la phase de Build, de les maintenir lors de la phase de Run, d’assurer la robustesse et une mise à l’échelle correcte du système pendant l’ensemble de son cycle de vie.
Disclaimer : cet article n’aura pas vocation :
- Ni à rentrer en détail dans les étapes du MLOps, suffisamment documentées en ligne. Vous pouvez d’ailleurs vous référer à nos articles et vidéos consacrées au MLOps sur le blog de Cellenza;
- Ni à présenter une liste exhaustive des outils disponibles aujourd’hui sur le marché, mais plutôt à présenter des exemples d’outils qui existent : les différentes étapes MLOps et leurs outils seront approfondis dans des vidéos et articles à venir dans les prochains mois !

La Préparation et la protection des données
La régulation s’est intensifiée ces dernières années sur le respect de la vie privée et la protection des données personnelles (RGPD, CCPA…), et l’on retrouve ces exigences dans le cadre d’une IA Responsable puisque ces systèmes d’IA s’appuient sur un grand nombre de données. Les initiatives et réglementations se rejoignent sur les principes visant à respecter la confidentialité (principes de confidentialité de l’OCDE sur l’IA à l’échelle mondiale, projet de réglementation pour une IA digne de confiance à l’échelle européenne) :
- garantie de la limitation de la collecte,
- garantie de la qualité des données,
- garantie de la spécification des objectifs,
- garantie de la limitation de l’utilisation des données,
- garantie de la responsabilité et de la participation individuelle…
Ces principes sont donc parfois déjà liés à certains droits individuels et à une réglementation sur la protection de la vie privée : par exemple dans le cadre du RGPD pour l’UE pour le principe d’équité (article 5), la surveillance humaine (article 22), la robustesse et la sécurité de traitement (article 5), le droit à l’explication (articles 12 à 15, 22) ou le droit à l’oubli (article 17).
Catégorisation et gouvernance des données
Pour remplir ces exigences et éviter les amendes parfois lourdes établies par ces règlementations (RGPD : jusqu’à 4% du CA annuel mondial), il faut déjà avoir une vision globale des données à disposition et les catégoriser (données personnelles, sensibles, stratégiques, métier…) pour pouvoir attribuer une responsabilité de celles-ci et un contrôle d’accès.
Vous trouverez ci-dessous plusieurs exemples d’outils de catégorisation et de gouvernance des données :
- Catégorisation des données – Azure Purview
Cette Solution Microsoft de gouvernance des données unifiées permet de tracer les données et de gérer leur accès et responsabilité.

- Catégorisation des données – Azure SQL Information Protection
Cet outil introduit des fonctionnalités avancées intégrées à Azure SQL Database pour découvrir, classer, étiqueter et protéger les données sensibles des bases de données.
- Respect des obligations juridiques – exemple du droit à l’oubli RGPD avec Delta
Pour en savoir plus, nous vous invitons à consulter notre article “Droit à l’oubli : quel impact sur la donnée ? Comment le mettre en place ?”
- Qualité de données
Sur ce sujet, nous vous conseillons de consulter l’article suivant de cette série sur l‘Observabilité des données
Jeux de données déséquilibrés et biais algorithmiques
Le biais algorithmique est une anomalie présente lors de la sortie du système d’IA. Cela peut parfois être dû aux données collectées pour entrainer le modèle : il peut, par exemple, s’agir d’une mauvaise sélection par l’humain amenant à la sous-représentation d’une population ou d’un biais historique (par exemple un modèle d’octroi de crédits entrainé sur des données des dernières décennies sans prendre en compte l’évolution de l’émancipation économique des femmes : Article Le Point Aurélie Jean – Quand les algorithmes discriminent les femmes, 2019).
Nous vous proposons quelques outils :
- Microsoft Responsible AI Dashboard
Cette représentation visuelle permet à l’utilisateur de rechercher certaines informations comme le taux d’erreur et la représentation des données.

- Préparer les données avec Tensorflow Responsible AI guide
- Know your Data: analyse de l’ensemble des données de manière interactive pour améliorer la qualité des données (réduction des problèmes de biais et d’équité).
- TF Data Validation: analyse et transformation de données pour détecter des problèmes de biai
- Limiter le risque d’exposition de données d’entrainement sensibles avec une descente de gradient stochastique à confidentialité différentielle (DP-SGD).
- Fiches de données
- IA sur étagère : Blackbox ?
Les IA « prêtes à l’emploi » (Cognitives services Azure – Face API, Speech To Text, etc.) permettent un gain de temps important mais sont parfois limitées dans l’accès aux données d’entrainement et aux modèles utilisés, et laissent une moins grande marge à la customisation et au contrôle par l’utilisateur (effet « boite noire »).
Cependant, après quelques cas critiques, on observe un effort de la part des éditeurs pour redonner le contrôle à l’utilisateur et regagner sa confiance. Ainsi, Microsoft ou IBM ont dû améliorer leur technologie de reconnaissance faciale et donner à l’utilisateur du service plus d’outils d’évaluation du modèle après certains biais de genre et de couleur de peau relevés en 2018 par l’informaticienne Joy Buolamwini basée au MIT Media Lab.
La Conception et l’entrainement d’un modèle ML
L’un des principaux défis de la conception d’un système d’IA est de concevoir une IA plus responsable et plus fiable. Cela se joue dès la phase d’idéation du projet et pour une part importante également lors du Build. Le modèle ML interagira avec de nombreuses personnes de profils différents (data scientists, décideurs, utilisateurs réels, personnes directement ou indirectement impactées par le système d’IA).
La confiance par l’ensemble de ces interlocuteurs dans le modèle ML conçu est essentielle pour la réussite du projet. Pour cela, la définition en amont de l’impact potentiel du modèle (social, économique, écologique), de l’éthique, et de l’explicabilité du modèle est nécessaire pour instaurer cette confiance autant dans le modèle que dans le process automatisé qui le soutiendra.
Développer et entrainer le modèle : Équité et Interprétation
Lors de l’entrainement du modèle, il sera nécessaire d’utiliser ou de développer des outils permettant de garantir l’équité et l’explicabilité du modèle.
Equité et Non-Discrimination
Dans un rapport de 2020, le Défenseur des droits en partenariat avec la CNIL soulignait les « risques considérables de discrimination que peuvent faire peser sur chacun et chacune d’entre nous l’usage exponentiel des algorithmes dans toutes les sphères de notre vie », insistant sur le fait que ce sujet était « longtemps resté un angle mort du débat public » et qu’il ne « [devait] plus l’être » (Algorithmes : prévenir l’automatisation des discriminations, 2020).
En plus des biais liés aux données (manque de représentativité des données mobilisées par exemple), ces biais peuvent être amplifiés par le modèle (par exemple lorsqu’on se limite à la performance globale du modèle en oubliant des sous-groupes/populations).
Voici quelques exemples d’outils :
- AzureML : Azure Machine Learning Studio est un environnement de développement intégré basé sur une interface graphique qui permet de créer et de rendre opérationnel le flux de travail Machine Learning sur Azure. Il dispose de nombreuses fonctionnalités pour mesurer la précision du modèle. La fonctionnalité Fairlean permet d’évaluer l’ « impartialité » des prédictions d’un modèle.
- Dataiku – Model fairness reports permet d’en savoir plus sur le degré de biais d’un modèle, en implémentant certaines mesures d’équité.
Interprétation et explicabilité du modèle
La difficulté tient souvent dans le juste équilibre à trouver entre la performance du modèle et son interprétation. En effet, complexifier le modèle revient souvent à réduire son explicabilité, parfois jusqu’à en devenir une « boite noire ».
Il faut donc inclure dans le développement du projet ML des outils et processus pour améliorer continuellement la transparence et l’explicabilité du modèle lorsque cela est raisonnable.
Cette interprétation permet également aux professionnels du domaine de garder la main sur leur expertise et de remettre en cause une prédiction lorsqu’elle est incohérente. La pression est aussi parfois dans la réglementation : par exemple, l’article 22 du RGPD prévoit qu’une personne ne doit pas faire l’objet d’une décision fondée exclusivement sur un traitement automatisé et émanant uniquement de la décision d’une machine.
Exemples d’outils :
- Les algorithmes LIME (Local Interpretable Model-agnostic Explanations) et SHAP (SHapley Additive exPlanations) : deux bibliothèques Python populaires pour l’interprétabilité du modèle.
- Microsoft Responsible AI Dashboard – InterpretML introduit un modèle de « Boite en verre » (EBM) performant pour expliquer le comportement d’un modèle.
Évaluer et fiabiliser : mesure de précision du modèle
Il est bien évidemment nécessaire de développer des processus pour garantir la précision et minimiser les erreurs du modèle grâce à des outils et métriques pertinentes par rapport au type de modèle et aux applications spécifiques du domaine.
Quelques exemples d’outils :
- Microsoft Responsible AI Toolbox – Debugging :
- Error Analysis: analyse et diagnostique les erreurs du modèle ;
- DiCE : permet une analyse contrefactuelle pour le débogage des prédictions individuelles ;
- EconML: aide les décideurs à délibérer sur les effets des actions dans le monde en utilisant l’inférence causale ;
- HAX Toolkit: guide les équipes dans la création d’expériences collaboratives homme-IA fluides et responsables.
- Dataiku – Model Error Analysis : un plugin qui fournit à l’utilisateur des outils pour automatiquement décomposer les erreurs du modèle en groupes significatifs pour pouvoir plus facilement les analyser, mettant en évidence le type d’erreurs le plus fréquent, etc.
Le déploiement et le monitoring d’un modèle Machine Learning (ML)
Les modèles ML sont dynamiques : ce type de projet fonctionne par itérations successives puisque le modèle évolue constamment en fonction des données d’entrée notamment. Il faut donc s’assurer que ce modèle – performant au moment de sa livraison – reste performant dans le temps.
Pour cela, il va falloir associer des outils de déploiement continu (pipelines CI/CD), de monitoring et d’alerting pour prévenir les risques de concept drift, data drifts, etc. (pour l’explication de ces notions, consultez notre article « Simplifiez vos projets de data science avec MLflow »).
Déploiement et reproductibilité du modèle
Le développement d’une infrastructure est nécessaire pour permettre un niveau raisonnable de déploiement continu et de reproductibilité à travers les opérations des systèmes ML.
Nous vous proposons ci-dessous quelques outils de déploiement et reproductibilité du modèle :
- MLflow est une plateforme open-source de gestion du cycle de vie de modèles ML depuis l’expérimentation vers le déploiement, en assurant la reproductibilité et permettant de créer un registre de modèles central.
Pour aller plus loin sur MLflow :
- Autres plateformes robustes open-source pour simplifier le cycle de vie d’un projet ML (Experiment tracking, data versioning …) : KubeFlow, Pachyderm.
- Pour les solutions entreprise : Azure ML ou AWS SageMaker.
- Kubernetes : nous vous conseillons la lecture de notre article « Kubernetes : construire une plateforme en pensant Run »
Garder un contrôle humain
Il peut être facile d’oublier l’impact de mauvaises prédictions dans un système d’IA automatisé. Des fonctionnalités permettant aux travailleurs et experts du domaine de constamment affiner ou recadrer la précision du modèle doivent être implémentées dès que possible, et surtout si cette automatisation peut engendrer un impact significatif sur la société et la vie humaine (santé, banque, justice…).
Cela passe notamment par l’identification des informations pertinentes du modèles et sa documentation et/ou vulgarisation.
Exemples d’outils :
- Model Card permet de générer une sorte de carte d’identité des modèles ML développés (Tensorflow Model Card Toolbox)

- Dataiku Document Model Generator permet de générer une documentation associée avec n’importe quel modèle entrainé, générant un fichier Word qui fournit certaines informations comme l’objectif du modèle, comment ce modèle est conçu (algorithme, features, traitements…), les ajustements effectués et la performance du modèle.
Pour aller plus loin sur le Run
La relation est donc étroite entre le Build et le Run dans un projet d’IA. De même, le maintien de la cohérence entre les deux cycles de vie Données et Modèle et le respect des exigences pour concevoir une IA Responsable font du projet ML un projet particulièrement complexe à maintenir en phase de Run.
Mais la prise de conscience de cette complexité a ces dernières années amené les éditeurs et développeurs à implémenter de multiples outils et fonctionnalités de MLOps et DataOps permettant plus aisément de gérer les deux phases Build & Run.
Le MLOps en particulier aide à rendre les modèles ML plus évolutifs, fiables, éthiques et explicables pour répondre à des exigences de régulations qui ne pourront être que plus fortes dans les prochaines années.
Pour en savoir plus comment optimiser le Run dès la phase de Build, nous vous invitons à consulter les autres articles de cette série proposée en partenariat avec Squadra, l’expert du Run sur Azure :
- 12 Factor-App : les patterns à adopter dans le développement d’applications modernes
- Comment maintenir une plateforme Kubernetes en condition opérationnelle ?
- Kubernetes : construire une plateforme en pensant Run
- Les outils de Run natifs de la plateforme Azure
- L’observabilité des données
- Quels indicateurs pour suivre votre application mobile ?
- Les plateformes d’intégration dans Azure : pourquoi, avec quels axes et comment les monitorer ?
- OpenTelemetry : instrumentation en .NET dans le futur





