

Dans la continuité des articles précédents sur la Kubernetes Gateway API, nous explorons aujourd’hui un aspect plus opérationnel de ce...
8 mars 2022
Kubernetes : construire une plateforme en pensant Run

Article corédigé par Benoit Sautière (Cellenza) et Sébastien Dillier (Squadra)
Kubernetes est un écosystème complexe que nous devons construire et gérer dans le temps. C’est un sujet que nous avons déjà développé chez Cellenza lors du Mois du Conteneur en juin 2021. La conception de cet écosystème (la plateforme AKS, les services techniques que nous lui associons et les services Azure périphériques) doit prendre en compte sa future exploitation aussi nommée le « Run ». Autant faire les bons choix dès le début pour éviter de devoir reconstruire avant de passer en production. La construction de cette plateforme doit répondre à un certain nombre d’objectifs que nous allons nous fixer (résilience, disponibilité…). Encore faut-il les formuler.

Quels objectifs pour notre plateforme AKS ?
Les exigences que nous allons faire porter à notre plateforme Kubernetes sont définies par les applications que l’on va héberger dessus. Les métiers doivent décider de l’importance qu’ils accordent à leurs applications. Une application dite « Customer-facing », très visible pour l’entreprise et génératrice de chiffre d’affaires, est considérée comme critique pour l’entreprise. Pour un métier, l’indisponibilité de ce type d’application est considérée comme un risque auquel notre future plateforme AKS devra être en mesure de faire face. La construction de la plateforme Kubernetes découlera de ces objectifs, que nous traduirons en engagements.
En tant que futur exploitant de la plateforme que nous sommes en train de construire, nous devons nous engager sur sa disponibilité et sa résilience. Dans Azure, tous les services que nous consommons sont engagés sur un niveau de SLA. Ces engagements contractuels de la part de Microsoft seront la base de travail pour calculer le SLA (Service Level Agreement ou accord de niveau de service) de la plateforme Kubernetes qui va porter nos applications.
Par défaut, le service Azure Kubernetes Services s’engage sur un objectif de disponibilité (Service Level Objective) de 99.5%. Il ne s’agit pas d’un engagement mais juste d’un objectif. Microsoft propose un engagement sur la disponibilité du service AKS de 99.95% (Azure Kubernetes Service Uptime SLA). Derrière ces chiffres, il ne faut pas perdre de vue que l’indisponibilité existe toujours.
Le tableau ci-dessous présente l’indisponibilité acceptable selon le niveau de SLA retenu par les métiers :
| SLA | Indisponibilité annuelle | Indisponibilité mensuelle | Indisponibilité hebdomadaire |
| 99% | 3.65 Jours | 7.20 heures | 1,68 Heures |
| 99.5% | 1.83 jours | 3.60 heures | 50.4 minutes |
| 99.9% | 8.76 heures | 43.2 minutes | 10.1 minutes |
| 99.95% | 4.38 heures | 21.56 minutes | 5.04 minutes |
A noter : pour tenir ce niveau d’engagement, on doit aussi aborder la disponibilité des équipes qui auront la charge de la plateforme Kubernetes. L’humain est le premier impliqué dans la réponse à un incident. Même si notre réponse est automatisée (bascule automatique sur une autre région Azure, reconstruction de la plateforme dans une autre région…), encore faut-il prendre la décision dans un temps acceptable. En France, pour opérer un service en continu (24h sur 24h, 7 jours par semaine), cela implique d’avoir au moins sept personnes pour chaque poste de l’équipe en charge de l’exploitation de la plateforme, c’est un point à ne pas négliger.
Quel SLA pour notre plateforme AKS ?
La mesure de la disponibilité de notre infrastructure ne se limite pas à la disponibilité de son composant le plus important. Avec Azure Kubernetes Services, nous sommes face à un écosystème où chaque composant dispose de son propre SLA. On parle alors de SLA composite. Comme on peut le voir dans le diagramme ci-dessous, AKS est un écosystème complexe et le calcul du SLA composite ne sera pas une tâche aisée.

Architecture AKS – Vue détaillée
Sans rentrer dans les architecture complexes impliquant de multiples régions Azure, l’indisponibilité de l’un de ces composants impactera nécessairement notre plateforme Kubernetes et donc potentiellement les applications qu’elle héberge, ce qui nous permet d’aborder la notion de résilience.
AKS : une plateforme résiliente par nature
Construire une plateforme résiliente implique de faire des choix. Kubernetes est un système complexe et distribué. L’élaboration d’un système résilient implique de s’intéresser à sa cohérence, sa disponibilité et sa tolérance au partitionnement. Or, selon le théorème de CAP, un système réparti ne peut fournir que deux des trois caractéristiques souhaitées. En conséquence, la plateforme AKS parfaite n’existera jamais. Maintenant que nous l’avons accepté, analysons la résilience que le service Azure Kubernetes Services est en mesure de nous proposer à différents niveaux :
- Niveau Control Plane: Ce sont les nœuds du cluster qui gèrent notre cluster AKS. Microsoft les héberge pour nous gratuitement. A ce niveau, nous avons le choix entre nous contenter de l’objectif de SLO de 99.5% proposé par défaut par Microsoft ou activer l’option « Uptime SLA » qui nous garantit un SLA de 99.95%. Le Control Plane d’AKS étant gratuit, Microsoft ne pouvait pas s’engager sur sa disponibilité. Notons qu’il est possible d’ajouter cette option sur un cluster existant.
- Niveau région Azure: AKS est un service régional, donc lié à une région Azure. A ce niveau, l’utilisation des Virtual Machine Scale Sets nous permet de répartir ses instances entre les multiples zones de disponibilités qui composent la région. En cas d’indisponibilité des instances hébergées dans une zone de disponibilité, le Control Plane de Kubernetes va détecter la situation et assurer la reconstruction des nodes défaillants. L’indisponibilité d’une ou plusieurs instances réduit notre capacité à héberger des applications. Nous avons le choix de surévaluer le nombre d’instances nécessaires ou accepter une indisponibilité temporaire le temps que les instances défaillances soient remplacées.
- Niveau node: Le Control Plane de Kubernetes détecte la défaillance des nodes soit parce que ceux-ci remontent un statut « NotReady » pendant dix minutes consécutives, soit parce que le node ne remonte aucun statut pendant cette même période. Ici encore, le Control Plane de Kubernetes va détecter la situation et assurer la reconstruction des nodes défaillants. Pendant cette période, les capacités d’hébergement (CPU/RAM) s’en trouvent diminuées, ce qui peut avoir un impact sur la disponibilité de nos applications. Pour se prémunir contre ce risque, il est toujours bon de prévoir un node additionnel dans le pool Kubernetes. Cela constitue certes un coût d’un point de vue financier mais il faut le considérer comme une assurance. De toute façon, nous allons avoir besoin de ce node supplémentaire pour gérer la mise à niveau des clusters.
- Niveau Pod: A ce niveau, c’est la définition même de notre application qui détermine la résilience avec la notion de « ReplicaSet ». Dans Kubernetes, nous avons déclaré notre application sous la forme d’un « Deployment ». La notion de « ReplicaSet » permet d’exprimer le nombre d’instances pour chacun de nos pods. Charge au Control Plane de Kubernetes de s’assurer que le nombre de réplicas que nous demandons est le bon, et ce pendant toute la durée de vie de l’application.
Par sa conception, Azure Kubernetes Service intègre de multiples niveaux de résilience. En fait, le seul risque que la plateforme ne puisse adresser nativement est l’indisponibilité du service à l’échelle d’une région Azure. Heureusement, les incidents de ce niveau sont relativement rares. Si le métier considère que nous devons être à même de faire face à ce type de situations, il faudra alors concevoir une infrastructure « Multi-région », permettant de basculer les applications d’une région à une autre.

Architecture AKS multi-région – Vue simplifiée
Disposer des mêmes capacités dans une autre région Azure est relativement simple puisque cela se résume à mettre à disposition des mêmes capacités d’hébergement dans une seconde région Azure. Là où cela se complique, c’est pour le stockage et les services de base de données nécessaires à nos applications.
Résilience de nos backing services
La notion de « backing services » a été abordée dans le premier article de cette série. Nous devons leur apporter la même exigence que pour Azure Kubernetes Services. Sans eux, pas de stockage, ni de bases de données, donc nos applications ne sont pas opérationnelles. Dans un scénario « Multi-région », il est techniquement possible de consommer des services Azure dans une autre région. Cette solution implique que nous acceptions le surcoût de consommation de bande passante et n’est envisageable que tant que les performances de nos applications ne s’en trouvent pas impactées de manière trop importante. Cependant, cette solution ne prend pas en considération le risque d’indisponibilité de nos « Backing services ». Cela nous amène à considérer les risques auxquels nous devront faire face :
- L’indisponibilité locale du service au sein de la région ;
- L’indisponibilité régional du service.
Selon les « Backing services » que nous consommons dans Azure, ceux-ci proposent des solutions pour atténuer ces risques (le risque zéro n’existe pas). Le tableau ci-dessous synthétise comment les principaux services Azure sont en mesure d’adresser ces risques.
| Service Azure | Indisponibilité locale | Indisponibilité régionale | Stratégie de bascule |
| Storage Account | Zone-redundant storage (ZRS) | Read-Access Geo-Redundant Storage (RA-GRS)
Read-Access Zone-Redundant Storage (RA-ZGRS)
|
Storage Account Object Replication (Blob)
|
| Azure SQL Database | General Purpose service tier zone redundant availability | Active Geo-replication | Auto-Failover Groups |
| Azure Database for MySQL | Zone-Redundant HA architecture | Azure Database for MySQL Read replicas | Geo-Restore
|
| Azure Database for PostGreSQL | Zone redundant high availability architecture | Azure Database for PostgreSQL Read Replicas | On-demand failover |
| Azure CosmosDB | Continuous Backup | Distribute your data globally with Azure Cosmos DB | Configure multi-region writes in your applications that use Azure Cosmos DB |
| Azure Cache for Redis | Zone redudancy | Geo-Replication
|
Failover and patching for Azure Cache for Redis
Configure geo-replication for Premium Azure Cache for Redis instances |
Individuellement, chacun de ces services Azure est en mesure de nous apporter des solutions pour pallier une indisponibilité locale ou régionale du service. Notre défi sera de nous assurer de la cohérence des données qui peuvent être réparties entre multiples services, tout en assurant un temps de rétablissement le plus court possible pour nos consommateurs. Développer ce niveau de résilience implique de s’y préparer et donc d’envisager les pires des scénarios.
Être prêt en cas d’incident
Augmenter la disponibilité et la résilience de notre plateforme AKS la rend plus complexe, tout comme les incidents que nous allons devoir gérer. Cela implique de se préparer à faire face à un certain nombre de scénarios (indisponibilité totale ou partielle de l’infrastructure) et de s’entrainer à y répondre. Du point de vue des métiers, ils doivent se prononcer sur les objectifs que nous devrons atteindre :
- En combien de temps dois-je être capable de rétablir le service ?
- Quelle perte de données est-elle acceptable pour les consommateurs ?
La réponse à la première question consiste à se fixer un objectif de RTO (Recovery Time Objective). Tenir cet objectif implique principalement d’investir dans différents domaines :
- Industrialisation : Du déploiement de l’infrastructure (avec Terraform) mais aussi des applications (avec Helm / Kustomize) ;
- Détecter les signes de défaillances de notre plateforme pour opérer une bascule préventive et non réactive. Cela implique de développer une connaissance fine de notre plateforme Kubernetes via l’observabilité ;
- Tests : Nous devons tester nos procédures vis-à-vis des incidents afin de valider que nous sommes toujours capables de respecter notre engagement de RTO.
Lors de la bascule de notre infrastructure, il existe un risque de perdre des données. Dans le contexte d’un Storage Account, Azure propose de la synchronisation synchrone pour les Zone-Redundant Storage (ZRS), ce qui nous garantit la cohérence de nos données au sein de la région Azure. Dès lors qu’on réplique notre Storage Account dans une autre région Azure en Geo-zone-Redundant Storage (GZRS), la réplication sera asynchrone. A un instant T, il existe donc un risque que la cohérence de nos données ne soit plus respectée. Depuis mi-2020, il nous est possible d’initier le processus de bascule de notre Storage Account.
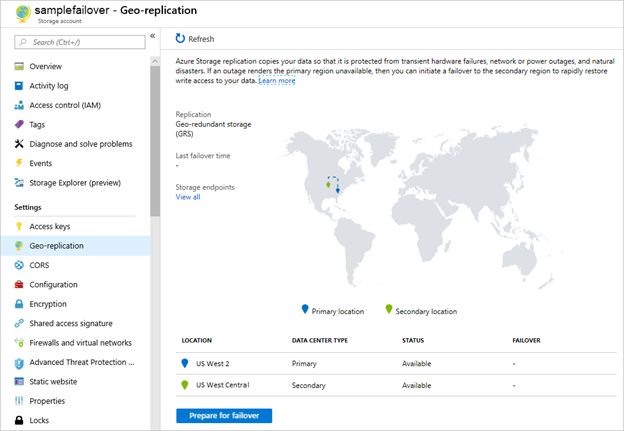
Bascule manuelle de Storage Account entre deux régions Azure
Depuis peu, on dispose même d’un mécanisme de réplication entre deux Storage Accounts distincts : Object replication for block blobs. Notre objectif sera de réduire le risque de perte de données ou tout du moins de réduire le temps d’indisponibilité de nos applications. Voilà pour le RPO (Recovery Point Objective).
Construire notre plateforme AKS
Un cluster AKS, ce sont des instances de compute (node) organisées en groupes (Pools) qui vont héberger nos Pods. On distingue les Pools dits « System-Nodes Pools » et les « User-Nodes Pools ». Le « System-Node Pool » est prévu pour isoler un certain nombre de Pods techniques nécessaires au bon fonctionnement de Kubernetes (CoreDNS, etc.). Un mécanisme nommé « Node affinity » permet de s’assurer que ces pods techniques seront placés sur ce « System-Nodes pool » de manière préférentielle. Pour le « System-Node pool », la bonne pratique est d’avoir au moins trois nodes que le Virtual Machine Scale Set pourra répartir entre les trois zones de disponibilité de la région afin de garantir la résilience. L’indisponibilité de l’un des trois nodes ne met pas le cluster en péril. Enfin, on aura toujours besoin d’au moins un node additionnel afin de pouvoir organiser l’upgrade de Kubernetes. Ce processus de mise à niveau implique de disposer d’au moins un Surge Node pour réaliser l’opération.
En introduisant un ou plusieurs « User-nodes pools » pour héberger nos applications, on peut choisir la taille de machine virtuelle la plus adaptée. Combiné avec un mécanisme nommé « Taints and Toleration », Kubernetes permet de créer un lien d’affinité entre un « User-nodes pool » spécifique (par exemple machines virtuelles avec GPU) et des pods pour favoriser son usage vis-à-vis des autres pods qui, eux, n’ont pas besoin des capacités de ces machines virtuelles.
Pour chaque « User-node pool », ses capacités à héberger des pods sont limitées par la puissance CPU et la mémoire. Augmenter le nombre d’instances permet donc d’augmenter nos capacités d’hébergement. Pour dimensionner notre cluster, nous devons prendre en compte les besoins CPU et mémoire de chaque pod mais aussi leur nombre de réplicas déclarés au sein de chaque « Deployment ». Le nombre total de pods est important car il ne faut pas dépasser le nombre maximum de pods que l’on peut instancier sur chaque node. Cette limite est définie lors de la création du Node pool. A noter : la valeur par défaut n’est pas la même si notre cluster est déployé avec le Network Provider Kubenet ou CNI. Une limite trop basse peut conduire à une sous-utilisation des capacités CPU / mémoire des nodes et donc nécessiter plus de nodes qu’il n’en faudrait réellement. A ce stade, nous connaissons le nombre de nodes qui va composer notre « User-node Pool ». Se pose maintenant une question : si je devais perdre un node, ai-je assez de capacité sur les nodes restants pour héberger toutes mes applications ? Si la réponse est non, vous savez qu’il vous manque donc au moins un node dans votre « User-node pool » pour adresser le risque de perte de capacité de notre cluster.
Pour finir, le nombre de nodes composant un pool n’est pas nécessairement fixe, il peut être dynamique en configurant la fonctionnalité Cluster Autoscaler. Le cluster AKS détecte les situations ou le Control Plane n’est pas en mesure de déployer de nouveaux pods à cause des contraintes imposées. Le cluster va donc automatiquement augmenter le nombre de nodes dans le pool. Cette fonctionnalité se décline aussi au niveau des pods en utilisant les métriques pour déterminer le nombre de pods nécessaires au bon fonctionnement (Horizontal Pod Autoscaler).

Cluster Autoscaler et Horizontal Pod Autoscaler
Cycle de vie d’une plateforme Kubernetes
Kubernetes est un produit vivant. Depuis juillet 2021, la communauté en charge du développement de Kubernetes a acté un cycle de trois releases majeures par an. Chaque nouvelle release s’accompagne de nouvelles fonctionnalités mais aussi des corrections de sécurité. Dans Azure, la politique de support d’Azure Kubernetes Services indique que seules trois releases majeures stables sont supportées. Concrètement, il ne sera plus possible de mettre à niveau un cluster AKS si sa version date de plus d’un an. Le sujet ne doit pas être sous-estimé. La plateforme Kubernetes que nous construisons inclut tout un écosystème dont il sera nécessaire d’organiser la mise à niveau. Pour cela, deux stratégies sont à notre disposition :
- Upgrade
- Rebuild
Stratégie Upgrade
Azure Kubernetes Services prend en charge le Maintien en Condition Opérationnelle (MCO) de nos clusters, il nous simplifie le processus de mise à niveau. Avec le temps, ce processus technique devient un non- évènement du point de vue AKS. Cependant, nous devons encore valider le bon fonctionnement de l’écosystème que nous y installons et vérifier que nous ne constatons pas de régression sur les applications. Lors d’une nouvelle release, il peut arriver que certaines APIs soient dépréciées. Ces changements sont annoncés à l’avance pour nous permettre de les anticiper. Le processus d’upgrade étant pris en charge par AKS, il est industrialisé de bout en bout. On peut choisir de mettre à niveau le Control Plane, un Pool, voire même node par node si nécessaire. Techniquement, AKS va isoler chaque node (cordon et drain) de manière à forcer le redéploiement des pods sur d’autres nodes. Ceci fait, le node est remplacé par un nouveau. Ce processus peut être long, surtout si le cluster doit redéployer de nombreux pods. Le principal défaut de cette stratégie est qu’on ne connait pas la durée totale de l’opération. En tant que futur exploitant, cette stratégie ne nous permet pas de de nous engager sur une fenêtre de maintenance. Enfin, elle implique que tous les métiers propriétaires des applications acceptent une même date pour réaliser cette opération de maintenance.
Stratégie Rebuild
La stratégie Rebuild consiste à construire une nouvelle plateforme AKS à côté de la plateforme existante pour organiser une bascule progressive des applications. Cette approche permet de valider notre capacité à reconstruire notre plateforme Kubernetes et donc de valider que nous sommes capables de respecter notre objectif de temps de rétablissement du service (RTO). Cette stratégie ne nous impose pas de basculer toutes les applications en même temps et nécessitera une attention particulière pour la bascule des « Backing services ».
Quels indicateurs suivre ?
Le moniting de notre plateforme Kubernetes nous donne de nombreux indicateurs sur sa santé. En charge de l’exploitation, nous avons besoin de deux familles d’indicateurs :
- Les indicateurs de capacité
- Les indicateurs de situation
La première famille d’indicateurs doit nous permettre de valider que le dimensionnement de notre plateforme permet de répondre aux besoins des applications hébergées, même en cas de pic de charge. La seconde famille se focalise sur les applications.
Les indicateurs de capacité
La disponibilité de notre plateforme est le premier indicateur de capacité à suivre. Kubernetes suit l’état de chaque node avec la notion de Condition. Cet indicateur nous permet de facilement détecter les nodes indisponibles ou présentant une consommation mémoire élevée. Cette information est importante car un node en moins dans le cluster, ce sont des Pods que le cluster peut ne plus pouvoir instancier. Les capacités de notre cluster sont limitées par la taille des machines virtuelles et les ressources qu’elles mettent à disposition (CPU, mémoire). La fonctionnalité Cluster Autoscaler permet d’augmenter les capacités du cluster mais ce n’est pas instantané. La fonctionnalité ne se déclenche que lorsqu’un déploiement n’a pu être réalisé, ce qui signifie notre plateforme n’a pas été en mesure de répondre aux besoins d’une application. Flirter avec les limites n’est donc pas une option. Si nous avons identifié des périodes de forte activité pour nos applications, autant anticiper la demande.
Un second indicateur de capacité à suivre est le nombre de pods instanciés par node. Ce nombre est limité au niveau de chaque node pool. La valeur par défaut varie selon que notre cluster utilise la stack réseau Kubenet ou CNI. Kubernetes refusera d’instancier des Pods sur un node si cette limite est atteinte. Une valeur trop basse et ce sont des ressources (CPU / mémoire) que nous ne pouvons pas utiliser. Le problème, c’est que cette valeur n’est configurable qu’à la création du node pool. Tout comme la consommation CPU ou mémoire, cet indicateur détermine les capacités d’hébergement.
Les indicateurs de situation
Concernant les indicateurs de situations, le premier qui va nous intéresser est le statut des Deployments. Kubernetes compare en permanence le nombre de Pods demandés (les réplicas) avec le nombre de Pods réellement instanciés. Une différence entre les deux peut être le fait d’une situation transitoire (augmentation du nombre de Pods avec Horizontal Pod Autoscaler) mais si la situation perdure, il existe un risque pour l’application de ne pas pouvoir répondre à un pic de charge.
Second indicateur à suivre : les « Retry ». Un Deployment peut échouer pour de multiples raisons, cela peut être le fait d’une situation transitoire. Kubernetes détecte cette situation et incrémente un compteur de « Retry » au niveau de chaque Deployment. Un accroissement de cet indicateur peut suggérer que la situation n’est pas transitoire. Il conviendra alors de déterminer pourquoi ; ce sera le point de départ d’une démarche de diagnostic à mener avec une approche rigoureuse, ce qui nécessite un peu de pratique.
Comment suivre ces indicateurs ?
Le moyen le plus simple pour suivre ces indicateurs est de mettre en place des tableaux de bord. La solution Azure Container Insights est intégrée à Azure Monitor et donc à Azure. La solution présente l’avantage d’être nativement intégrée à Azure et d’être prête à consommer sur étagère.

Azure Monitor Container Insights (Microsoft)
Pour rester indépendant du Cloud Provider, il est possible de s’orienter vers une solution open-source comme Grafana. La solution s’installe sous la forme d’une application sur Kubernetes. L’intégration avec Azure est relativement rapide et de multiples tableaux de bord sont déjà disponibles pour suivre nos indicateurs, comme celui illustré ci-dessous :

AKS Grafana dashboard (Grafana)
Pour aller plus loin sur Kubernetes
La construction de notre plateforme Kubernetes implique de nombreux choix techniques mais aussi organisationnels pour être en mesure de respecter les engagements pris vis-à-vis des métiers. Il est essentiel de prévoir comment sera opérée la plateforme une fois mise en production. Après, le travail continuera pour répondre à de nouveaux engagements. Comme évoqué lors du Mois du Conteneur, il faudra investir dans l’observabilité de notre plateforme et de nos applications. Nous vous invitons à consulter notre livre blanc « Préparer l’adoption de Kubernetes ».
Nous vous invitons également à consulter l’ensemble de notre série d’articles autour du Run, rédigés en partenariat avec Squadra :
- 12 Factor-App : les patterns à adopter dans le développement d’applications modernes
- Comment maintenir une plateforme Kubernetes en condition opérationnelle ?
- Kubernetes : construire une plateforme en pensant Run
- Les outils de Run natifs de la plateforme Azure
- Run d’un projet IA : garder sous contrôle le cycle de vie d’un modèle ML
- Observabilité des données
- Quels indicateurs suivre pour vos applications mobiles ?
- OpenTelemetry : instrumentation en .NET dans le futur





