

Dans la continuité des articles précédents sur la Kubernetes Gateway API, nous explorons aujourd’hui un aspect plus opérationnel de ce...
17 mars 2022
Read this post in English
L’observabilité des données

Article corédigé par Donatien Tessier et Amine Kaabachi
Comme le disait un vieux slogan publicitaire : « Sans maîtrise, la puissance n’est rien ! »
Pour une data platform, la maîtrise passe principalement par la gestion de la qualité des données (sur le sujet, nous vous invitons à consulter notre article sur la définition d’une donnée de qualité et les différentes étapes de vérification). Une machine de guerre qui transforme et stocke des données inconsistantes n’a pas de sens.
Un pipeline de données est constitué d’un enchainement d’étapes. La dernière étape consiste généralement à mettre à disposition les données auprès d’un ou plusieurs utilisateurs. L’adoption d’un nouveau produit peut se faire rapidement par les utilisateurs et devenir rapidement indispensable. La perte de confiance dans cet outil peut également s’avérer très rapide. Cette confiance sera particulièrement longue à revenir.
C’est pourquoi il est capital de s’assurer de la qualité des données d’une plateforme de données. La qualité intervient à 3 niveaux, du plus basique au plus avancé :
- Santé opérationnelle
- Supervision du jeu de données
- Validation de la qualité des données
- Profil au niveau des colonnes
- Validation au niveau des lignes
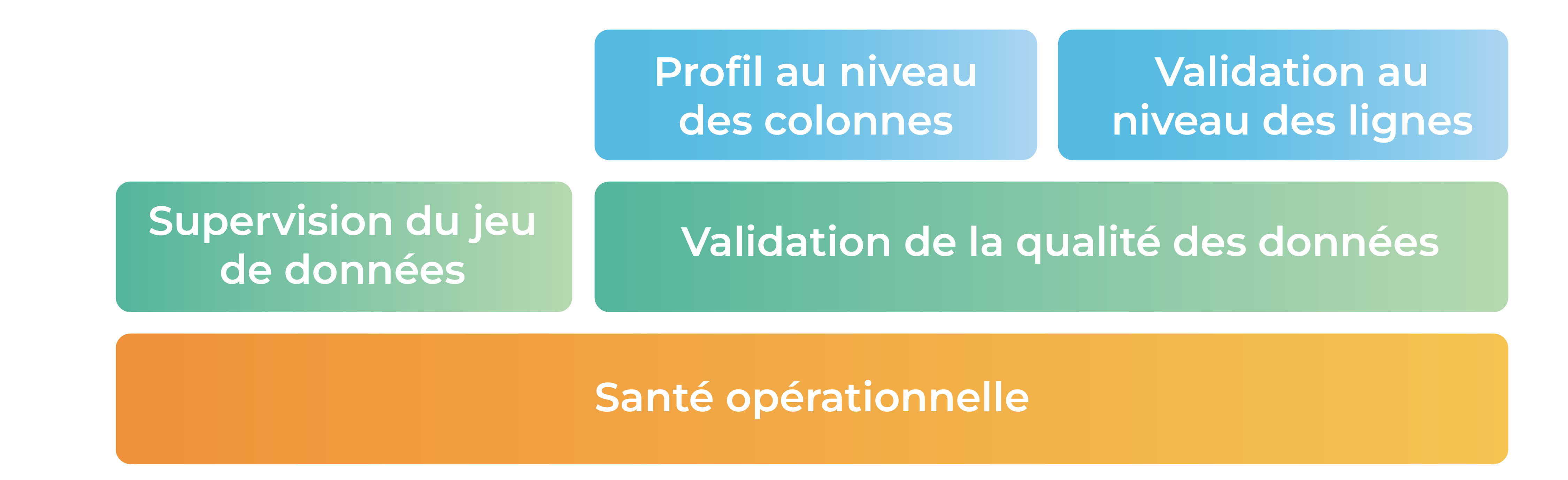

Santé opérationnelle
Statut du pipeline de données
Un pipeline de données est un enchainement d’étapes. Le premier niveau consiste donc à s’assurer que l’intégralité des étapes qui constituent le pipeline se déroulent avec succès. Dans le cas contraire, il faut alerter les personnes en charge de l’opérationnel pour ce projet.
⚠️ Attention cependant à ne pas tomber dans l’excès inverse : remonter des faux positifs fera se détourner les personnes recevant les alertes au risque de passer à côté de problèmes bien réels.
L’exécution des étapes peut échouer pour plusieurs raisons : problème de chemins d’accès, librairie manquante, etc. En utilisant un service tel qu’Azure Data Factory, l’activité échouera et si la configuration a été mise en place, vous serez alerté.
En revanche, dans certains cas, l’exécution se déroulera avec succès alors que les données sont absentes, par exemple. Il faut donc mettre en place des alertes pour signaler un comportement inhabituel et pouvoir réagir en conséquence. Cela sera possible uniquement si, lors des développements, une exception est remontée dans le cas de données manquantes, par exemple. Il ne s’agit donc pas de règles métiers, à proprement parler, mais plutôt de règles d’exploitation auxquelles il est nécessaire de réfléchir lors de la conception. On parlera alors de DataOps.
Temps de traitement
L’exécution des traitements avec succès ne signifie pas forcément que l’application est saine. En effet, le temps de traitement est une composante importante de la santé opérationnelle. Il arrive souvent qu’il se dégrade au fur et à mesure du cycle de vie d’un projet. Le jeu de données de départ croît au fur et à mesure et peut aboutir à des problèmes de performances. Cela peut être le cas, par exemple, lorsqu’une extraction complète des données est réalisée quotidiennement au lieu d’extraire uniquement les nouvelles données et celles qui ont été modifiées. Ce point doit être considéré lors de la conception du projet.
Supervision du jeu de données
Disponibilité des données
Trop souvent, lors du développement d’un projet, les data engineers travaillent avec des jeux de données et ne se projettent pas sur le contexte opérationnel. Que se passe-t-il si les données ne sont pas présentes ?
Une partie des données proviennent d’une source A et d’une source B. Que se passe-t-il si les données de la source A sont absentes de la source B, des deux sources ?
Un fournisseur de données peut ne plus déposer de fichiers dans un répertoire : il sera donc intéressant de remonter le problème lors d’une exécution quotidienne en s’apercevant que le fichier quotidien est absent.
Quoi de plus délétère pour un projet qu’un utilisateur s’aperçoive au bout de quelques jours que les données ne sont plus alimentées dans un rapport ou une application ? De plus, d’un point de vue opérationnel, il est ensuite très chronophage de remonter les étapes du pipeline à la recherche de l’étape à partir de laquelle les données sont absentes et de comprendre la cause de cette absence.
C’est pourquoi il faut remonter des exceptions si les données sont absentes au plus tôt dans la chaine de traitement afin de limiter la nécessité d’investiguer à la recherche de l’origine du problème et de pouvoir réagir le plus rapidement possible.
Sans pour autant se reposer sur lui, il est important de rendre l’utilisateur acteur de la qualité du produit. Par exemple, il peut être intéressant d’afficher pour l’utilisateur la dernière date et heure d’exécution du traitement des données avec succès. Celui-ci aura alors une maitrise de l’information.
Fraicheur des données
La fraicheur des données est un point capital dans un projet data. En effet, le traitement des données peut tourner régulièrement et malgré tout ne pas contenir les dernières données. Il faut donc contrôler s’il existe des manques de données selon un intervalle de rafraichissement prévu. Par exemple, si des données doivent remonter toutes les 5 minutes, il est nécessaire de contrôler qu’il ne manque pas de données pour un des créneaux.
En complément de la fraicheur des données, le volume est un indicateur précieux. Selon des statistiques sur le volume de données, il est facile de remonter une alerte dans le cas où la volumétrie de données ne correspondrait pas à la volumétrie attendue. Dans ce cas, il sera nécessaire d’utiliser des marges de tolérance supérieures et inférieures afin de ne pas produire de faux positifs.
La fraicheur et la volumétrie reposent sur une prévisibilité du comportement des données. Malgré tout, une composante reste imprévisible : le schéma. En effet, celui-ci peut être amené à évoluer au cours de la vie du projet. Cela peut se traduire de plusieurs manières : par le changement d’un type d’une colonne, par l’ajout d’une nouvelle colonne, par la suppression d’une colonne existante, etc.
Schéma
Pour prévenir des changements de type, il est nécessaire de figer le schéma plutôt que de laisser inférer celui-ci (en plus de gain de performances lié au scan des données nécessaires à l’inférence).
Deux possibilités s’offrent à vous pour gérer ces changements :
- les accepter en les accueillant et en autorisant les changements de schéma (https://docs.delta.io/latest/delta-update.html#-merge-schema-evolution)
- les refuser en écartant les données qui ne respectent pas les règles que vous avez fixées.
Dans les deux cas, il est essentiel d’alerter du changement afin de déterminer si le choix n’a pas d’impact sur la solution.
Validation de la qualité des données
Profil au niveau des colonnes
Une fois que nous sommes sûrs de l’état opérationnel et global des jeux de données de nos pipelines data, il est judicieux d’aller plus loin et de vérifier la qualité du contenu.
Dans le cas d’un traitement batch, il n’est pas forcément recommandé de vérifier les valeurs ligne par ligne mais plutôt de le faire sur des échantillons. Comme nous traitons généralement des milliards de lignes, la qualité des données serait un composant très coûteux à ajouter sur l’intégralité des données en entrée.
Imaginons des cas où nous pourrions avoir un problème de qualité de données :
- Une colonne toujours vide dans l’ensemble de données ;
- Une colonne qui était remplie mais qui devient soudainement vide ;
- Un décalage dans les colonnes dû à un problème d’ingestion ;
- Etc.
Que devons-nous faire pour être en mesure de détecter et d’alerter sur ce type de problème ?
L’approche généralement mise en œuvre est la suivante :
- Pour chaque nouveau lot, sélectionner un échantillon aléatoire représentatif.
- Pour cet échantillon, calculer et stocker des métriques de colonnes comme le pourcentage de valeurs vides ou la fréquence de la valeur la plus courante.
- Appliquer une approche de comparaison de distribution ou de détection d’anomalie avec les anciennes métriques.
- Dans le cas de différences significatives, bloquer le processus et effectuer une validation manuelle ou alerter en priorité l’équipe chargée des données.

A noter : le test de Kolmogorov-Smirnov est le plus utilisé pour comparer les distributions dans le cas de la qualité et de la dérive des données. Certaines équipes préfèrent toutefois appliquer une approche de type « Machine Learning » en utilisant par exemple le « One-class SVM » ou d’autres méthodes de détection d’anomalie.
L’implémentation technique recommandée est de partir d’une bibliothèque comme AWS Deequ en Scala ou en Python (fork du projet) et de l’adapter aux besoins de votre entreprise et de vos équipes. Par défaut, cette bibliothèque offre les fonctionnalités suivantes :
- Persistance et interrogation des métriques calculées des données ;
- Profilage des données de grands ensembles de données ;
- Détection d’anomalies sur les métriques de qualité des données au fil du temps ;
- Suggestion automatique de contraintes pour les grands ensembles de données ;
- Calcul incrémental des métriques sur des données en croissance et mise à jour des métriques sur des données partitionnées.
Validation au niveau des lignes
Pour les lots en streaming et les petits jeux de données, l’approche recommandée est d’appliquer une validation ligne par ligne. Lorsqu’elle est appliquée à une petite échelle, c’est le moyen le plus sûr et le plus efficace d’assurer une bonne qualité des données et même de valider certaines règles métier.
Les règles de validation sont appliquées sous forme de tests unitaires ou de tests de qualité. Des bibliothèques permettent de faciliter l’implémentation et l’analyse des résultats.
En Python, un des choix qui s’impose ces dernières années est une bibliothèque open source appelée « Great Expectations » offrant les fonctionnalités suivantes :
- Déclaration des assertions et tests pour les données avec une abstraction couvrant la majorité des besoins de validation ;
- Gestion des suites de validation des données ;
- Génération automatique de la documentation ;
- Profilage automatisé des données.
La bibliothèque est extensible et peut servir de base pour un framework de validation plus complet et adapté à vos cas spécifiques.
La qualité de la donnée : clé du succès d’un projet
La qualité de données est une des clés de succès d’un projet et l’assurance de garder la confiance des utilisateurs. Il convient de s’assurer de la qualité des données est complexe, surtout si l’on souhaite couvrir les trois niveaux que nous vous avons présentés.
Idéalement, les contrôles doivent être prévus et mis en place lors de la conception du projet. Cependant, il n’y a pas de fatalité à la dégradation de la qualité des données et il est toujours possible de rectifier le tir. Bien sûr, en fonction de la conception, ce processus prendra plus ou moins de temps.
Nous sommes convaincus que ce sujet passe par une bonne compréhension du métier.
Et si vous souhaitez en savoir plus sur la façon dont le Build sert le Run ? Nous vous invitons à consulter tous les articles de notre série dédiée au Run, en partenariat avec Squadra :
- 12 Factor-App : les patterns à adopter dans le développement d’applications modernes
- Comment maintenir une plateforme Kubernetes en condition opérationnelle ?
- Kubernetes : construire une plateforme en pensant Run
- Les outils de Run natifs de la plateforme Azure
- Run d’un projet IA : garder sous contrôle le cycle de vie d’un modèle ML
- Quels indicateurs pour suivre votre application mobile ?
- Les plateformes d’intégration dans Azure : pourquoi, avec quels axes et comment les monitorer ?
- OpenTelemetry : instrumentation en .NET dans le futur





