

Dans la continuité des articles précédents sur la Kubernetes Gateway API, nous explorons aujourd’hui un aspect plus opérationnel de ce...
10 mars 2022
Read this post in English
Les outils de Run natifs de la plateforme Azure

Article corédigé par David Frappart (Cellenza) & Florent Hilger et Sébastien Leroy (Squadra)
Avec la maturité actuelle des plateformes Cloud, les environnements de production sont naturellement arrivés dans ces plateformes.
Dans un premier temps, il a été nécessaire d’absorber le paradigme Cloud inhérent à ces plateformes et d’adapter les architectures « Legacy », au sens hors Cloud, à ces nouvelles plateformes.
A présent, il est nécessaire de franchir l’étape suivante : maitriser les opérations des environnements dans le Cloud.
Dans cet article, nous allons tenter d’apporter quelques clarifications et pointeurs pour atteindre ce but, spécifiquement sur la plateforme Azure.
Il serait présomptueux de prétendre tout adresser à travers un seul article, aussi allons-nous nous concentrer sur les sujets suivants :
- En premier lieu, partant du postulat que le Run consiste d’abord à savoir quelles opérations doivent être réalisées, nous allons naturellement parler d’observabilité.
- Nous ferons ensuite une petite incursion dans les concepts de protection des applications, au sens sauvegarde et restauration.
- Enfin, nous décrirons quelle est notre approche aujourd’hui, issue de nos diverses expériences.

Les outils pour l’observabilité dans Azure
Puisque l’avènement du Cloud a engendré un changement dans le design des architectures, il est naturel que les moyens d’observabilité aient été également impactés.
Fort heureusement, la plateforme Azure fournit nativement un écosystème riche et extensible, dans le sens où il est possible de connecter des systèmes d’observabilité tiers.
Parlant d’observabilité, nous aurons besoin de définir des métriques d’une part, et de collecter des logs d’autre part. En effet, les logs permettent de tracer les erreurs sur un système et de définir par exemple un taux d’erreur. Les métriques permettent quant à elle d’obtenir des informations précieuses comme la latence d’un site web ou la saturation d’un micro-service.
Nous allons également avoir besoin d’être informés sur ces logs et métriques, par le moyen d’alertes ou de dashboards.
Les métriques
L’accès aux métriques dans Azure est fourni par Azure Monitor Metrics. Par leur nature, légère, il est possible de prendre en charge des « scénarios quasi-temps réel », selon la documentation Microsoft.
L’exploration des métriques peut être réalisée sur une ressource en direct, en utilisant le menu « metrics » et en ajoutant une métrique désirée.

Métriques dans Azure Monitor
En première approche, ce moyen constitue une façon simple de configurer l’observabilité d’une ressource.
Sorti du mode exploration, en s’appuyant sur la documentation Azure, on peut ainsi obtenir l’ensemble des métriques disponibles pour un type de ressource.
Microsoft.ContainerService/managedClusters
| Métrique | Exportable par le biais des paramètres de diagnostic ? | Nom d’affichage de la métrique | Unité | Type d’agrégation | Description | Dimensions |
| apiserver_current_inflight_
requests |
Non | Demandes en cours | Count | Average | Nombre maximal de demandes en cours actuellement utilisées sur le serveur d’API par type de demande au cours de la dernière seconde | requestKind |
| cluster_autoscaler_cluster_safe
_to_autoscale |
Non | Intégrité des clusters | Count | Average | Détermine si l’autoscaler de cluster entreprend ou non une action sur le cluster | Aucune dimension |
| cluster_autoscaler_scale_
down_in_cooldown |
Non | Recharge de scale-down | Count | Average | Détermine si le scale-down est en recharge. Aucun nœud n’est supprimé au cours de cette période | Aucune dimension |
Échantillon de métriques de plateforme Azure
En fonction de certains seuils à définir, il est possible de créer des alertes ou de générer un dashboard qui agrègera les métriques d’un sous-ensemble de ressources ciblées. Nous aborderons ce sujet plus en détails dans les parties « Alerting » et « Dasboarding ».
Les logs
Après ce tour d’horizon sur les métriques, regardons à présent les logs.
Dans les faits, nous avons globalement 3 types de log :
- les logs d’activités ;
- les logs de ressources ;
- le 3ème type de log qui n’est en réalité pas tout à fait un type de log, puisqu’il s’agit des logs spécifiques à la partie Azure Active Directory.
Pour résumer, nous pouvons nous appuyer sur ce tableau extrait de la documentation Azure :
| Journal | Couche | Description |
| Logs de resources | Ressources Azure | Fournissent des insights sur les opérations effectuées au sein d’une ressource Azure (le plan de données), par exemple l’obtention d’un secret à partir d’un Key Vault ou l’envoi d’une requête à une base de données. Le contenu des journaux de ressources varie en fonction du service Azure et du type de ressource.
Les journaux de ressources étaient auparavant appelés journaux de diagnostic. |
| Log d’activité | Abonnement Azure | Fournit des informations sur les opérations effectuées sur chaque ressource Azure dans l’abonnement à partir de l’extérieur (plan de gestion) en plus des mises à jour sur des événements Service Health. Avec le journal d’activité, répondez aux questions quoi, qui et quand concernant toutes les opérations d’écriture (PUT, POST, DELETE) effectuées sur les ressources dans votre abonnement. Il n’y qu’un seul journal d’activité par abonnement Azure. |
| Logs Azure Active Directory | Tenant Azure | Contiennent l’historique de l’activité de connexion et la piste d’audit des modifications apportées dans Azure Active Directory pour un locataire particulier. |
Descriptif des type de logs dans Azure
Si l’on souhaite détailler un peu les logs des ressources Azure, qui sont également rassemblés dans les Azure Monitor Logs, nous allons avoir :
- les logs natifs des ressources ;
- les logs et données de performances, collectés par des agents dans les machines virtuelles ;
- les logs applicatifs collectés avec Application Insight.
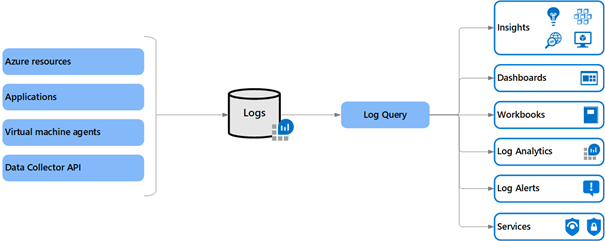
Détails des logs de ressources
A l’exception des logs d’activités, qui sont nativement disponibles depuis le portail Azure pour une durée de 3 mois, les logs sont disponibles, sous réserve que l’on active leur collection à travers les Diagnostic settings.
Lors de la configuration de cette collection, nous avons le choix de la destination de stockage :
- Un compte de stockage Azure ;
- Un espace de travail Log Analytics ;
- Un Event Hub ;
- Des solutions tierces disponibles sur la market place Azure.

Configuration des logs pour une ressource Azure

Type de log et destination possible dans Azure
D’une manière générale, le compte de stockage est utilisé pour les rétentions longues et est peu coûteux.
L’espace de travail Log Analytics permet de travailler directement sur les logs en réalisant des requêtes dans le langage de Microsoft, le Kusto Query Language (KQL). En revanche, le coût d’ingestion des logs n’en fait pas la solution préférée pour les rétentions longues.
Un Event Hub va le plus souvent être utilisé pour envoyer les logs dans des systèmes externes.
Récemment est arrivée la possibilité d’ajouter des solutions partenaires disponibles sur la market place, ce qui peut souvent constituer un choix intéressant pour diminuer le coût de l’adoption d’un nouvel outil (par exemple le passage d’un langage de requête connu dans Kibana vs KQL).

Solution partenaire compatible comme cible de log Azure
Alerting dans Azure Monitor
Azure Monitor embarque bien entendu la possibilité de configurer des alertes.

Configuration des alertes dans Azure Monitor
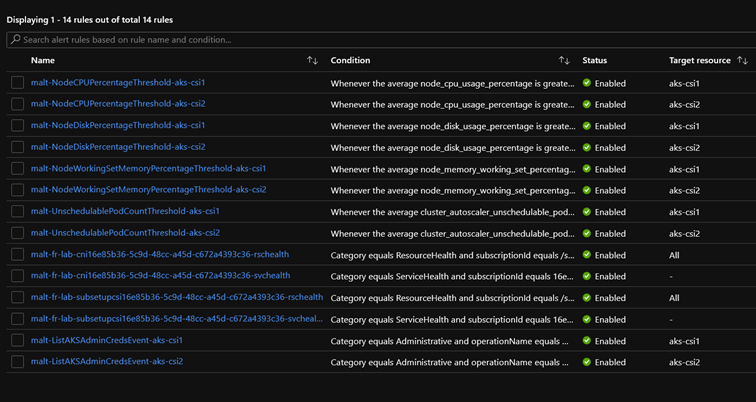
Échantillon d’alertes Azure

Signaux disponibles pour les alertes Azure
Ces alertes s’appuient principalement sur des conditions dans les métriques et des activity logs. Toutefois, pour des logs ingérés dans un espace de travail Log Analytics, il est possible de configurer des alertes personnalisées basées sur des requêtes KQL.

Échantillon de règle basée sur une requête KQL
Ces alertes en elles-mêmes doivent être couplées à un Action Group qui permettra de déterminer les modalités de notification de l’alerte. Ces notifications peuvent être simplement des emails ou intégrer des Logic apps, des Azure functions ou des webhooks.
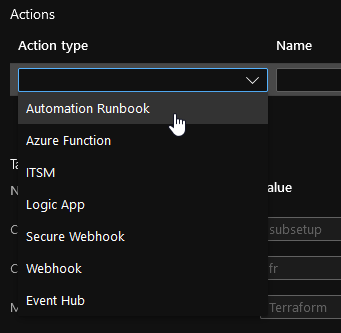
Actions disponibles dans un Action Group
Le dashboarding dans Azure Monitor
Hormis la simple notification, la visualisation de l’état d’un système est également critique dans la gestion des opérations. Il est bien entendu possible de connecter Azure Monitor à des solutions de dashboarding tierces.
Cependant, il est aussi possible de créer des dashboards directement dans Azure. Ces objets se comportent comme des ressources Azure, au sens où l’on peut leur assigner des accès via des rôles RBAC (Role-Based Access Control).
Il se crée de manière simple en sélectionnant une métrique et en sélectionnant l’option « Pin to Dashboard ».
Depuis un espace de travail Log Analytics, en écrivant une requête KQL appropriée, il est possible de générer des graphiques qui peuvent également venir enrichir un dashboard.
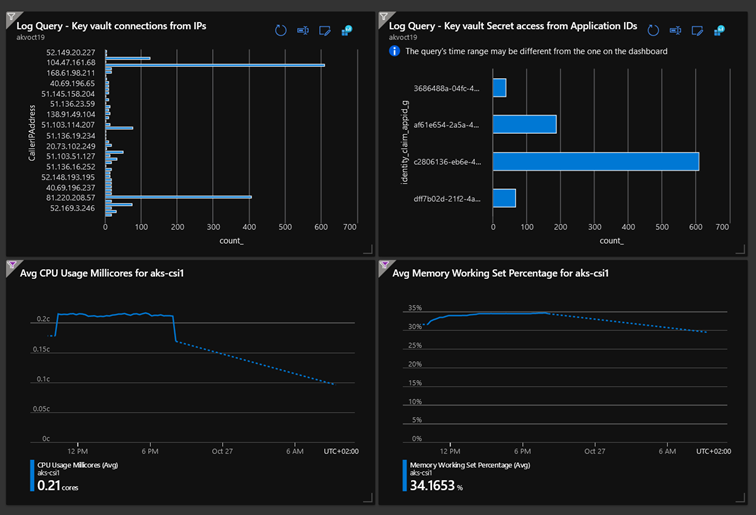
Exemple de dashboard construit à partir de métriques et de requêtes KQL
Notons l’existence de bibliothèques de workbooks, built in ou customisés, constituées de templates de requêtes KQL spécifiques et qui peuvent donner un rendu graphique soit depuis le menu workbook d’une ressource, soit également via le bouton « Pin to Dashboard » pour encore compléter une vue.

Quelques templates de workbooks

Workbook AKS
Pour finir, l’export de dashboards permet d’envisager l’industrialisation de leur construction.
Protection des ressources dans Azure
En pensant opération, on va également penser sauvegarde et restauration. Comme pour le monitoring, la plupart des solutions PaaS viennent avec des configurations possibles pour la protection des données. Par exemple, un serveur Azure Database for MySQL peut être configuré avec des sauvegardes automatisées ainsi que des options de Point in Time Restore.
Dans certains cas, la sauvegarde va s’appuyer sur les solutions natives comme Recovery Service Vault qui prend en charge la protection des VMs, dans Azure ou ailleurs, sous certaines conditions, mais également des comptes de stockage de type Blob ou Files, ou plus récemment Azure Database for PostGresQL.
Recovery Service Vault
Préparer les opérations dès les phases de design et de build
L’observabilité
Un corollaire de l’adoption Cloud est l’adoption de l’Infrastructure as Code.
Dès la configuration des logs de ressources où les alertes sont par définition des ressources Cloud, ces dernières deviennent éligibles à la configuration par Infrastructure as Code (IaC) et peuvent de fait être incluses dès le build.
La brique de base pour la configuration des logs de ressources sera la destination des logs. Rappelons-nous que les destinations possibles sont :
- Des comptes de stockage ;
- Des espace de travail Log Analytics ;
- ou des Event Hub.
Il s’agit donc par nature des ressources Azure configurables par Infrastructure as Code.
Que le scénario soit une destination de log globale au niveau de l’abonnement Azure ou associée à un sous-ensemble de ressources, il convient surtout de définir cette source de logs dès les phases amont, de landing zone ou de projet Azure.
Exemple de configuration Terraform d’une métrique Azure Monitor pour base de données
Pour résumer :
- Dans la phase de design :
- Définir les signaux indicateurs de l’état d’une plateforme / application Cloud
- Définir les alertes de métriques correspondant aux indicateurs précédents
- Définir les logs de ressources complétant ces indicateurs
- Définir les destinations de ces logs
- Définir les dashboards et workbooks pertinents devant être définis et standardisés
- Dans la phase de build :
- Construire les alertes Azure Monitor définies en design
- Configurer la destination des logs pour chaque ressource
- Construire les alertes basées sur des requêtes KQL le cas échéant
- Bâtir des dashboards basés sur les templates standards
La sauvegarde
De la même manière, si une brique d’architecture Azure dispose d’une solution de protection native, il est également possible d’ajouter la configuration de la protection en question, et le cas échéant les ressources Azure supplémentaires comme les Recovery Vaults et les politiques de sauvegardes associées. Comme pour Azure Monitor, le choix d’avoir des services de protections en mode mutualisé ou par abonnement doit être fait dès le design.
Exemple de configuration Terraform incluant la protection de la ressource
Exemple de configuration Terraform pour une politique de sauvegarde
Le Run dans Azure : l’essentiel à retenir
Le mot de Squadra, spécialiste du Run dans Azure :
Le Run est le maintien en condition opérationnelle des services mis en place par le Build. C’est pourquoi, il est primordial que le Run soit pris en compte dans la phase de Build pour être efficace dès le lancement du projet. Si l’on transpose cela au domaine de l’automobile, cela reviendrait à vouloir participer aux 24 Heures du Mans en espérant gagner sans staff technique, logistique, pièces ni pilote.
De ce fait, en parallèle de la construction, il faut mener des ateliers afin de déterminer les KPIs, les métriques clés de l’infrastructure, les alertes à émettre, ainsi que les contre-mesures associées. Par exemple :
- Fenêtre de maintenance qui risque d’impacter le service utilisateur ;
- Ajout d’un SDK (Sofware Development Kit) au web service Azure afin de remonter des métriques.
Ces ateliers doivent être menés par les équipes de Run avec l’ensemble des participants et particulièrement les responsables applicatifs. Ce sont les responsables applicatifs qui peuvent déterminer les KPIs clés de leur application (hors infrastructure).
Un Run bien défini permet d’être proactif et rend possibles des améliorations plus pertinentes (ex : capacity planning). Les équipes de « runners » doivent en permanence suivre les composants et les adapter au contexte client en fonction des évolutions de l’éditeur ou applicatif.
La méthodologie DevOps est de rigueur sur l’ensemble des projets, le but étant d’offrir une efficience permanente entre le Build et le Run. L’ensemble de cette mécanique mise en œuvre permet d’adapter mutuellement au fil de l’eau les évolutions et ainsi de garantir une disponibilité maximale
Au cours de cet article, nous avons vu que le Run dans Azure peut s’appuyer largement sur des solutions natives de la plateforme.
Nous avons également mis en avant l’importance de définir le plus en amont possible les indicateurs et les outils de protections des assets Cloud, afin de préparer en mode « IaC » les opérations Cloud.
En revanche, nous n’avons qu’effleuré le sujet Action Group, qui, au-delà de la simple notification, peut servir de base pour intégrer des remédiations ou réponses à des évènements automatisés.
Vous souhaitez en savoir plus sur la façon dont le Build impacte le Run ? Découvrez tous les articles de notre série inédite sur le sujet :
- 12 Factor-App : les patterns à adopter dans le développement d’applications modernes
- Comment maintenir une plateforme Kubernetes en condition opérationnelle ?
- Kubernetes : construire une plateforme en pensant Run
- Run d’un projet IA : garder sous contrôle le cycle de vie d’un modèle ML
- L’observabilité des données
- Quels indicateurs pour suivre votre application mobile ?
- Les plateformes d’intégration dans Azure : pourquoi, avec quels axes et comment les monitorer ?
- OpenTelemetry : instrumentation en .NET dans le futur





