

Introduction Integrating security into a widely used platform like GitHub is both a challenge and an opportunity to enhance its...
3 March 2022
Lire cet article en Français
How to Keep a Kubernetes Platform Up and Running

Post co-written by Jean-François le Lezec (Cellenza) and Sébastien Dillier (Squadra)
Maintaining a container-based platform means changing old habits. Containers have arrived with orchestrators that manage their cycles and a new separation between the application code and system layers.
Kubernetes is the leading orchestration platform today. To achieve this, the Kubernetes project teams decided to delegate some of the issues to third-party tools. This means that Kubernetes uses and comes with third-party components which need to be updated alongside major Kubernetes releases to support breaking changes and deprecated APIs.
Keeping a Kubernetes platform up and running properly requires an increased level of industrialization to address the following difficulties:
- Resilience
- Platform updates
- Monitoring
- Recurring task management
Resilience, a Strategic Challenge
One of the most challenging aspects of setting up an application service is making it resilient. The orchestrator makes decisions “autonomously” to ensure that the platform runs smoothly. For instance, the orchestrator may decide to relocate an application service on the current node to free up space. The service will then be moved to a different node and may even change its identity.
Kubernetes provides a rich set of tools to make our applications resilient and maintain our Service Level Agreements (SLAs).
Three main principles characterize resilience:
- High fault tolerance
- Increased load resistance
- Resistance to security threats
Fault Tolerance
The Kubernetes orchestrator provides a wide range of options to help us achieve these resilience goals, but there are some ground rules to follow:
- The first rule is to implement probes that let Kubernetes know if the application is still running and receiving traffic. If a container takes two minutes to start, all requests to it will fail during that time if these probes are not configured. Initially, the default probe implementation in the various software development kits (SDKs) may be suitable. If your API is heavily reliant on a part of the infrastructure, you will need to customize the probes to take this into account. If your application is slow to start up, use a StartUp probe to delay the execution of liveness probes. This will allow the application to start up without compromising the liveness probe.
- The second rule is to have enough replicas. Two is the minimum. This means giving preference to stateless services and outsourcing data storage to services outside the platform. Stateful objects can be used, but storage management must be planned based on resilience and performance.
- The third rule is to configure your applications to run on different nodes. This strategy can be implemented through “topology spread constraints” or “node affinities.” For example, multiple replicas of the same application can be deployed on nodes located in different Azure Availability Zones. Note: Since using nodeSelector/taint severely constrains the orchestrator, this configuration type should only be used for isolating workloads based on their hardware requirements (GPU requirements, for example).
- The fourth aspect is to calibrate our applications’ resources correctly. This allows Kubernetes to request an additional node where new workloads can be placed.
- Specifying Quality of Service (QoS) classes and priorities for pods allows the orchestrator to prioritize resource creation.
- Implement the shutdown process for your containers correctly to shut down your resources cleanly.
- The controlled and sensible use of pod distribution budgets ensures that sufficient replicas are available during maintenance. Although powerful, consider the requirements of the applications, the platform configuration (the max surge in the event of rolling updates on nodes), and the orchestrator’s constraints when using this tool. Incorrect configuration can cause platform updates to fail.
- Complex cases, such as data clusters, can be handled by creating/using operators.
Load Response
Kubernetes provides two native tools for dealing with load issues:
- The Cluster Autoscaler: this component adds or removes nodes from your cluster based on thresholds, such as CPU and memory requirements.
- The Horizontal Pod Autoscaler (HPA) lets you add replicas based on metrics like CPU or memory usage.
By activating these two components, you can create an infrastructure that adapts to the platform’s usage. The HPA’s requests for additional pods activate the autoscaler component. The HPA will request new pods as the load increases, forcing the cluster to create new nodes to accommodate them.
Other community-developed tools can address different use cases as well. These include:
- KEDA (Kubernetes Event-Driven Autoscaler) drives the HPA based on multiple metrics sources and thresholds. For example, the number of replicas can be increased based on the number of elements in a queue. KEDA supports a wide range of sources, including Azure Monitor and Prometheus.

- In its initial state, our service has one replica (orange line in the bottom graph), and our infrastructure has three nodes (yellow line in the bottom graph). In our test scenario, we’ll gradually add 60 concurrent users and ask KEDA to add a new replica as soon as we reach the ten additional requests per second (rps) threshold within the ten-replica limit.
- KEDA asks again at the start of the scale-out phase, tracking the changes in the requests. New pods are paused during this phase because the cluster cannot handle the new requests. The cluster autoscaler mechanism then kicks in and creates new nodes. As soon as a new pod is ready, it’s added to the service and handles an average load of ten requests per second.
- Stabilization phase: KEDA maintains a sufficient number of pods to meet the load requirements during this phase.
- Scale-down phase: KEDA keeps the added replicas for a set period before deleting them if no new requests are received. The autoscaler cluster then removes the newly added nodes.
- VPA (Vertical Pod Autoscaler) allows the vertical scaling of a pod by adding resources to it. The VPA is not compatible with the HPA except in Google Cloud Platform (GCP) with the Multiple Pod Autoscaler (MPA).
Protect Yourself
Kubernetes does not include a security layer to protect against attacks. But there are a number of steps you can take to reduce the risk.
Perimeter Segmentation
Defining access, resource management, and segregation policies at network level is the first step. Kubernetes provides several tools to solve these problems:
- Role-based access controls (RBACs) at the namespace level
- Namespace quotas to limit resource usage
- Priority classes to prioritize specific applications. For example, the ingress controller is a critical platform component that must not be harmed by a memory leak from another component
- Network layer isolation via networks policies
- Expose Prometheus metrics and probes on a different port so they are not exposed with ingress
Restrict Container Privileges
The other objective is to limit container access to the virtual machines on which they are hosted. Minimum access policies are implemented to achieve this:
- By removing image shells
- By prohibiting access to the host’s physical resources
- By prohibiting the use of privileged accounts
- By controlling the container’s service accounts
Managing the Platform Through Admissions:
As of Kubernetes version 1.21, Pod Security Policies are deprecated. The community has established projects based on admission controllers that allow for flexible control of the points listed above.
This control is achieved through two methods: validating and mutating admission controllers. Validating to check for probes and mutating to enforce tags or the security context.
The scope of application of these rules ranges from cluster and selector to object type. When used with RBAC, we have a powerful tool to safeguard deployments and maintain control over shared platforms.
Azure integrates Gatekeeper with Azure Policy to create a level of overall management for your infrastructure. There are a huge number of standard policies in Azure Policy, but you can also create your own. Some Gatekeeper functions are not available in Azure, however. Another notable effort is Kyverno, which offers a wide range of policies.
K8s, an Ever-Changing Platform
Container Maintenance
The container registry is the other important component of our container-based architectures: it’s here that we find the images that are ready to be deployed to a cluster.
Remember that an image must be immutable. This means that the application code and its dependencies must be statically defined in an Oracle Cloud Infrastructure (OCI) specification and installed when the image is created. This ensures that an image tested in a quality environment will perform similarly in production and will start up quickly. Each dependency will be defined in a statement and will result in the creation of a layer.
Our images are often based on Linux distributions such as Debian, Alpine, Ubuntu, etc. These images are “hardened” by systems and security teams in mature companies, but this is not always the case.
Image Maintenance
As previously stated, our images are frequently based on a Linux distribution whose life cycle we have no control over. As a result, these images will need updating to apply the latest security patches.
Azure Container Registry provides a sophisticated solution for tracking changes to base images and rebuilding dependent images.
Container Registry Management
Using Continuous Integration (CI) pipelines often generates vast numbers of images. This means that we need to manage the size of our registry. This requires a tag or date-based purge policy. It’s also important not to delete images that are used in production.
Public/Private
A Kubernetes platform is typically built using several public commercial off-the-shelf (COTS) components such as NGINX, cert-manager, Prometheus, and many others. These various images are available in public registries. However, in a Disaster Recovery Plan (DRP), limiting reliance on external sources for critical platforms is preferable. Cloud Solution Providers offer high-availability geo-replicated solutions.
Securing Our Images
Beyond Kubernetes, you need to consider the security of the base images used for your deployments. Vulnerabilities in our images can be detected as early as possible in our CI pipelines and via Microsoft Defender for Cloud at the container registry level.
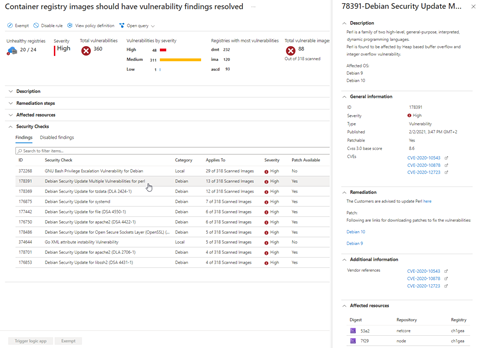
Special attention must be given to deployment configurations in this scenario to ensure your apps have a controlled life cycle within the Kubernetes environment.

Deployment
Configuration
Another key concept of the twelve-factor app is to separate the application configuration from our binary. To respect the principle of immutability, we must externalize our application parameters. Kubernetes provides two objects for this purpose: the configmap and secrets. These mechanisms are pretty similar and should be handled with the same level of caution.
Configmaps and secrets can be injected as a volume or into the application environment variables directly.
The application configuration is stored in a git controller together with these deployment manifests.
Sensitive variables can then be injected during deployment or stored in git, as long as their values are encrypted.
GitOps
The independence of teams working on a Kubernetes platform means each team can have its own cycle. In other words, a business team should not rely on the technical team to deploy an application, and the technical team should not rely on the business teams to operate the platform.
Resilience, access segregation, and automated application deployment mechanisms are needed to guarantee this separation. It’s difficult for operational technical teams to maintain application mapping of the many services and versions deployed on a platform on a large scale. Coordinating the various business teams to redeploy a platform as part of an Azure Kubernetes Service (AKS) migration, DRP, or cluster rebuild (address mapping change) is also complicated.
This requires reliance on a powerful software factory. There are currently two stand-out solutions for deploying to a Kubernetes cluster:
- Push mode involves pushing manifests to our clusters. This method is ideal for small-scale deployments. There are several limitations for industrial deployments, however:
- Maintenance: each cluster requires the maintenance of a service account
- Time: depending on how many deployment agents can be used at once, updating deployments with volumes can take several minutes
- Knowledge and coordination are required between the teams to deploy the various applications
- Pull mode solves a lot of these issues. In pull mode, GitOps allows you to automate deployments to the cluster of various git configurations from different repositories. That way, each team specifies the desired state of their application, and the GitOps agent handles the deployments for them. Consider an AKS migration using an active-passive setup. When the passive cluster is built, it subscribes to an initial repository containing the repository configurations for the business teams (pattern app for apps). The agent then clones the various repositories and deploys the application states described in each one. This method eliminates the need for business teams to access the cluster and for operational teams to understand how to deploy each application.
It’s also worth noting that each team can choose how to structure their repository. Some opt for branch management, while others use folder and tag creation. Each team can define its own way of working. In all cases, a pull or merge request process must be implemented to track actions, reduce risks, and simplify rollback.

Example of a multi-tenant organization
Deployment Pattern
Three standards are used for updates at the application level:
- rolling
- canary
- blue-green
Rolling mode is used by default for Kubernetes deployments. New pods are added during the rollout phase and begin receiving traffic when the deployment reaches the Ready state. Rolling mode does not allow for gradual deployment by controlling the error rate of new pods and network traffic.
Canary mode enables gradual rollout by sending a portion of the network traffic to new pods and controlling their error rate. Canary mode requires additional components such as an NGINX controller or proxies with traffic shifting, for example. Traffic shifting is included in the Open Service Mesh definition and is implemented by default in mesh services. Some tools, such as Flagger or Argo Rollouts, can automate this step. Then, all you need to do is define the success criteria for the deployment to go live.
Finally, blue-green mode allows two versions of an application to coexist: the published N version and the new N+1 version. After testing, the N+1 version replaces the N version.
Monitoring a K8s Platform
There are several reasons to monitor a Kubernetes platform:
- Understanding use
- Detecting and preventing failures
- Detecting and preventing hostile (malicious) behavior
Monitoring must also meet the requirements of the infrastructure, business, and security teams.
In practice, infrastructure teams focus on overall infrastructure availability, while business teams focus on application availability and Key Performance Indicators (KPIs). Finally, the security teams closely monitor access logs. Your chosen solution needs to meet the needs of all three groups.
We need to collect infrastructure and application metrics, event logs, and traces published by our applications to meet these objectives. A dashboarding and alerting solution is also required. In addition, a stream processing solution can correlate events based on data sources.
Although platform monitoring is the subject of this section, you will soon realize that we need to monitor not only the Kubernetes platform itself but also its entire ecosystem, i.e.:
- Events issued by Azure Health or the Kubernetes platform, for example, Azure Storage incidents
- Metrics for PaaS components used by Kubernetes or various storage services, such as the number of open ports on a load balancer
- Metrics, events, and logs provided by Kubernetes, for example, use of the port-forward API
- Application-provided metrics and logs, such as HTTP call traces, error rate, and latency
- Application-provided traces, such as calls between services or to storage
There are four ways to do this:
- Use cloud provider capabilities, such as Azure Monitor, Azure Defender for Cloud, Azure Container insights
- Use open source projects, such as Prometheus stack and Jaegger for the trace part
- Use third-party solutions, such as Datadog, ELK, Splunk
- A combination of the solutions listed above: for example, Prometheus for collecting Kubernetes metrics, Alertmanager for sending notifications, and Grafana for the dashboard part. The logs are sent to Azure Monitor or Event Hubs via Fluentd/Fluent Bit.
The application metrics are collected through the Prometheus endpoint expose, a platform standard used by all parties involved.

Hybrid implementation schemas:
Due to the wide range of Kubernetes implementations, each will have its own monitoring requirements.
Scale, topology, roles, and multi-cluster location should all be considered when choosing your strategy.
The diagram below shows a popular bottom-up strategy from infrastructure to applications.
Automating Recurrent Tasks
Should You Back up a Kubernetes Cluster?
Backing up a K8s cluster becomes relevant once we have outsourced the data, application source code, infrastructure scripts, and desired states to Git.
Yes, because your Kubernetes-hosted application may not have the same criticality level as your CI/CD chain or Git repository. In a DRP, you want to be confident that you can quickly restore your application without relying on an external system with availability you can’t always control. Note that some deployments change the state of a cluster, for example, when creating a new load balancer or amending a DNA record, whereas the backup will restore the known state.
Certificate Management
Certificate management is another delicate issue. Our applications typically use HTTPS, so they have to manage their certificates and associated DNS records.
Certificates are also used to authenticate mesh services. Managing the life cycle of certificates is therefore crucial. These procedures can be automated using Cloud Native Computing Foundation components that manage DNS records at the Azure zone level and certificate rotation. These components also provide certificate expiration metrics, so you can check that the system is working correctly.
Updating COTS Products
Updating COTS products on a platform is a critical activity that should not be overlooked. AKS deprecation follows the Kubernetes release cycle, requiring operators to migrate minor version clusters two to three times a year.
The Kubernetes version change brings with it many changes and deprecated APIs. The external COTS products used will need updating accordingly. Changes to kube-state-metrics can also heavily impact the monitoring solution.
More about Kubernetes
As we have seen, keeping an app running on Kubernetes requires you to meet a number of constraints across the development, run, and infrastructure teams.
Post co-written by Jean-François Le Lezec (Cellenza) and Sébastien Dillier (Squadra)





