

Developed by GitHub and OpenAI, professionals are calling GitHub Copilot a “revolutionary tool for developers,” since it combines Artificial Intelligence...
16 May 2023
Lire cet article en Français
Effortless MLOps: Streamline your ML workflows with Azure Machine Learning

This article is part of a series of posts about the Azure Machine Learning Service. I invite you to read the first part of this series dealing with Responsible AI dashboards enablement.
In this second part, we will see how to construct the backbone of an MLOPS platform using Azure Machine Learning Service and MLOps v2 accelerator.
Note: some details are avoided to prevent deviation from the scope, you will have useful links in each part.
ML Engineering
The field of Machine Learning (ML) is complex and requires a diverse skillsets, knowledge, and experience to build successful production-grade solutions. With all the existing specialties (Generative AI, NLP, Computer vision, forecasting, deep learning, classical ML, etc.), adding to that the complexity of model development, finding a profile that fills all subjects is just impossible.
The goal of ML engineering is not to master all the specialties, but to have good knowledge in ML and enough skills in software engineering, data engineering and infrastructure to increase the chances of getting ML projects to production and deliver reliable solutions.
According to Ben Wilson of Databricks, ML projects fail due to inexperienced data science team with large scale production grade model to solve a particular problem or simply fail to understand the desired outcome from the business. Look at the below picture where the reasons for ML projects failures are illustrated.

ML engineering Ebook from Databricks
In the coming sections of this article, we will tackle the problem of Infrastructure and how to deploy production-ready ML platforms using MLOPS v2 Accelerator on Azure Machine Learning.
Machine Learning operations
MLOps is an extension of DevOps. It applies DevOps principles and practices to Machine Learning projects. More precisely, it concerns data management, deployment environment, model versioning and model monitoring, in order to enable reproducible experimentations.
We distinguish 5 levels of maturity:
- No MLOps: manual builds and deployment
- DevOps but no MLOps: automated app code build and test.
- Automated Training: automated training pipelines and model management.
- Automated Model Deployment: automated deployment and ML endpoints catalog.
- Full MLOps: e2e automation.
For more information about MLOPS, please refer to Microsoft documentation.
MLOps v2 accelerator
We can find many articles, tools, and repos to deal with MLOps. But still… it’s overwhelming to setup everything from scratch and it needs skills in Software engineering, Infrastructure and DevOps without forgetting the Data end ML part, the core of ML projects.

Some popular tools and platforms for MLOps, picture from NimbleBox.ai
Microsoft has delivered through Azure Cloud, Azure Machine Learning service which is a MLOps platform that offers Low code, no code and full code experiences. The manipulation of this service can be done on the portal but we recommend to use SDK kit and CLI for data scientist/ML engineers, and DevOps/MLOps engineers. This platform is equipped with the essential components to deal with ML operations tasks as shown below:
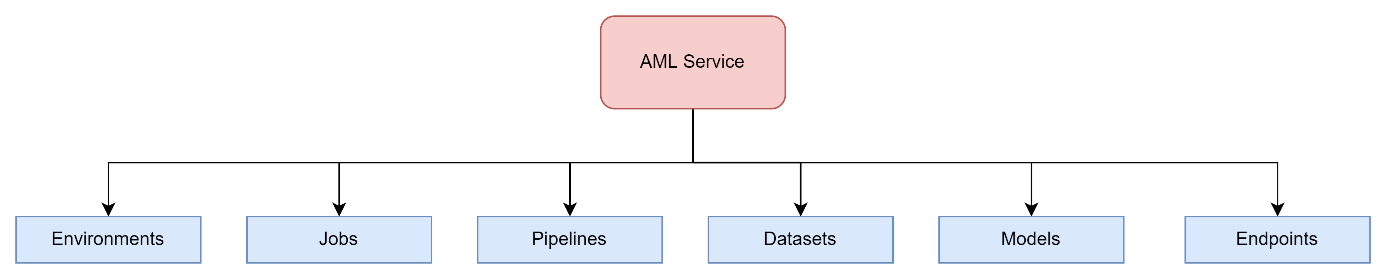
Azure Machine Learning assets
Lately, Microsoft has delivered an MLOps framework, to setup e2e ML projects using AML service in just few minutes called MLOps v2 Accelerator, here is the repo’s project where you can find the deployment guidance using Azure DevOps or GitHub Actions.
To start the construction of your MLOps platform, the first thing to do is to clone the repo. Then go to sparse_checkout.sh. The execution of this shell script will generate and bootstrap a MLOps template.
As you can see the first lines are arguments that we can set in order to customize our MLOps project:
- Set infrastructure as code tool (Terraform or Bicep)
- Set ML project type (classic, computer vision or natural language processing)
- Set MLOps version (CLI, SDK or Responsible AI-CLI)
- Set orchestration tool (Azure Devops or Github Actions)
After that, we select where to save the project, its name, GitHub organization name and finally the project template (we can leave it as it is).

After setting all the wanted arguments, we create an empty GitHub repo and we authorize the authentication to it using SSH. Please refer to GitHub documentation.
After executing the sparse_checkout.sh, a template will be generated as shown below:

In this example we’ve generated a classical template, based on Terraform for IaC and Azure DevOps for orchestration using AML CLI.
Note: Once you have the core template you can customize it and tailor it to fit your ML project needs.
We notice few modules:
- Data where we have a sample dataset.
- Data-science where we have a conda environment configuration and source code of each step of ML development.
- Infrastructure where we have DevOps pipeline configuration for IaC and Terraform modules to create related AML services.
- MLOps where we have deployment configurations (Batch and Online) and DevOps pipelines for training pipeline, batch and online inferencing.
At this stage, notice the most important yml configuration files for the construction of:
- Infrastructure pipeline
- MLOps pipelines (Training, batch and Online inference)

To proceed on Azure DevOps, import the GitHub repo to your Azure DevOps. Then go to “manage repositories”, select “security” and set the build service permissions as below:

To use Terraform as IaC tool we need its extension. In order to create Azure pipelines from the previous yml files we should create service principles with contributor roles. Please refer to Microsoft documentation for this task.
Once it’s done, go to Azure DevOps, Project setting in the bottom page, then Pipelines, select service connections, new service connection, select service principal (manual) and fill in the needed information of your service principle.

One last thing to configure is Pipelines: go to the 3 dots near the new pipeline button. Click and select Manage Security and Allow edit build pipeline.

After finishing all these details we’re ready to create our pipelines.
Infrastructure as code
We start by implementing Terraform IaC pipeline to create our infrastructure.
Go to Pipelines, new pipeline, select Azure Repos Git, select the repo then existing Azure pipelines YAML file and finally select the configuration yml for IaC (tf-ado-deploy-infra.yml)


The result below is our IaC pipeline:
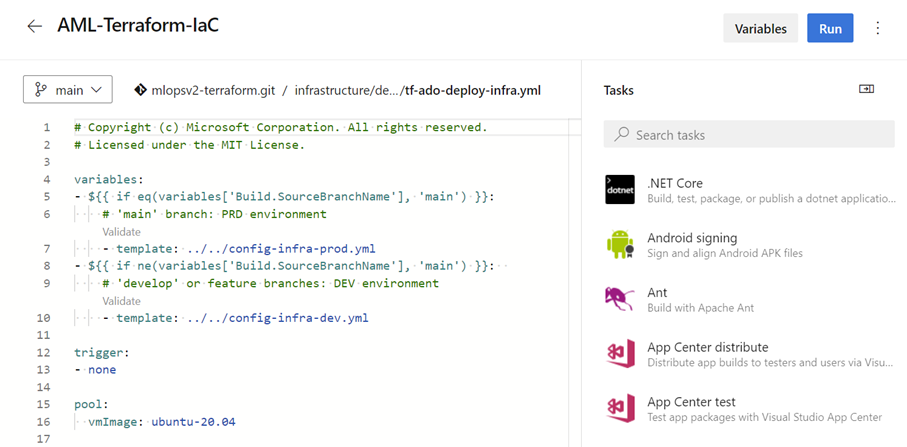
Before jumping to create another pipeline, let’s understand the IaC yaml template.
We load appropriate variables according to a specific branch. In this case, two sets of environments variables are defined, prod on main branch and dev on others than main. We set manual triggering and a ubuntu VM for the hosted agent (where the pipeline will run).
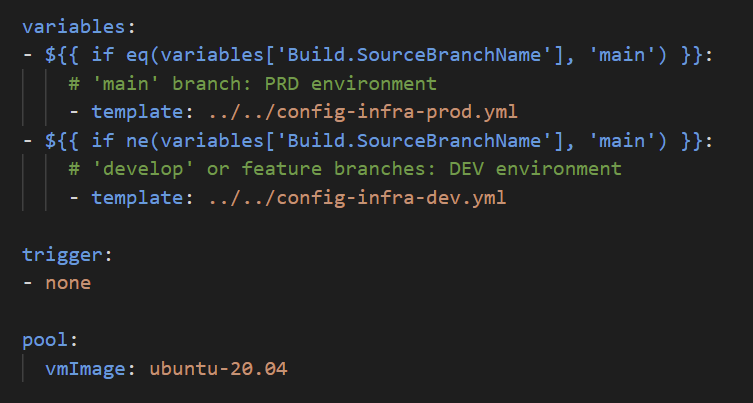
The config-infra-x file is where we define environment variables for each environment.
We have two stages; we create a blob storage on which we save the terraform.tfstate file of Terraform to simplify collaboration between the team and more others benefits. After that we deploy our infrastructure using Terraform workflow init, validate, plan and apply.
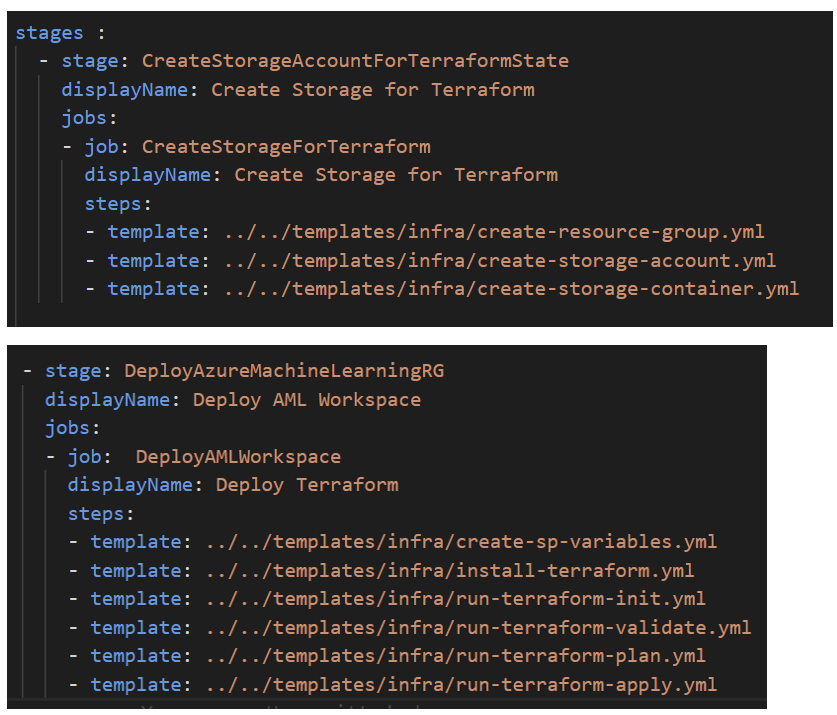
For more details about the used code for the steps click here.
As you can see, it’s pretty straightforward, and you don’t need huge experience in Terraform, because the heavy configuration is already done for us. To check the details of this configuration, go to infrastructure then modules, note that Azure Machine Learning relies on 4 services: Storage Account, Key Vault, Azure Container Registry and Application Insights.
MLOps pipelines
Once the infrastructure is delivered and our workspace is constructed, we can proceed to the creation of ML training, batch and online inferencing pipelines.
Training pipeline
This pipeline contains several tasks:
- Install az cli
- Install aml cli
- Connect to workspace
- Register environment
- Create compute
- Register data
- Run pipeline
Batch inferencing pipeline
This pipeline contains several tasks:
- Install az cli
- Install aml cli
- Connect to workspace
- Create compute
- Create endpoint
- Create deployment
- Test deployment
Online inferencing pipeline
This pipeline contains several tasks:
- Install az cli
- Install aml cli
- Connect to workspace
- Create endpoint
- Create deployment
- Allocate traffic
- Test deployment
We followed the same previous steps to select the proper yml configuration to create the pipelines.
As you can see everything is done for us and at the end of the journey, we will have these 4 pipelines, each one performing a specific task to enable e2e MLOps cycle.

At this stage we’ve automated all the workflows from infrastructure to batch and online inference and we’ve created the essential foundations of our MLOps platform.
Now, what you need to do is to wrap your existing ML code into this template and wire things properly (for instance make use of existing data on Data lake). In other words, go to:

And edit these files by your code!
Here are some useful links to properly wrap your code and start adopting Azure MachineLlearning as your MLOps platform:
Note: you can find all details in how to guides, concepts, reference, … etc in AML documentation.
And to have another point of view, this is what we’ve just achieved: look at the global architecture enabled by the MLOps v2 accelerator, it’s just amazing!
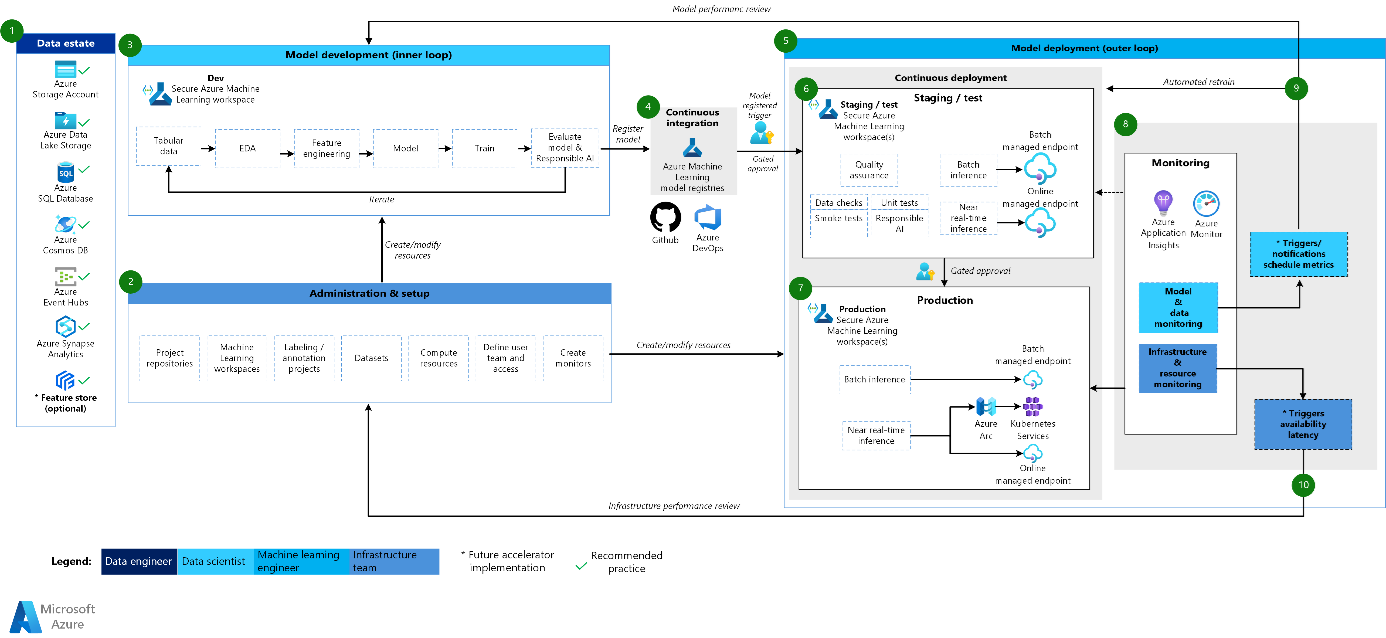
MLOPS v2 Accelerator by Microsoft (* new components to come)
Conclusion about starting an MLOps project
To conclude, starting an MLOps project has never been easier. You just need to rely on the generated template and customize it to fit your needs.
Would you like to be supported on your MLOps platform projects? Contact us!





Thank you for the valuable information on the blog.I am not an expert in blog writing, but I am reading your content slightly, increasing my confidence in how to give the information properly. Your presentation was also good, and I understood the information easily.